Содержание статьи

Современные сайты редко отдают данные без сопротивления. Даже простая выгрузка каталога или новостной ленты сталкивается с ограничениями по частоте запросов, проверками заголовков, анализом cookies и выполнением JavaScript. Игнорирование этих механизмов приводит к блокировке IP, искажению данных или подмене контента, что делает результаты парсинга непригодными для работы.
Перед началом сбора данных важно определить, какие именно барьеры применяются: серверные фильтры, поведенческий анализ, антибот-сервисы или динамическая генерация страниц. Например, сайты с CDN часто отслеживают несоответствие между User-Agent и TLS-отпечатком, а SPA-приложения могут отдавать пустой HTML без выполнения скриптов. Распознавание этих признаков позволяет выбрать корректный инструмент и сценарий запросов.
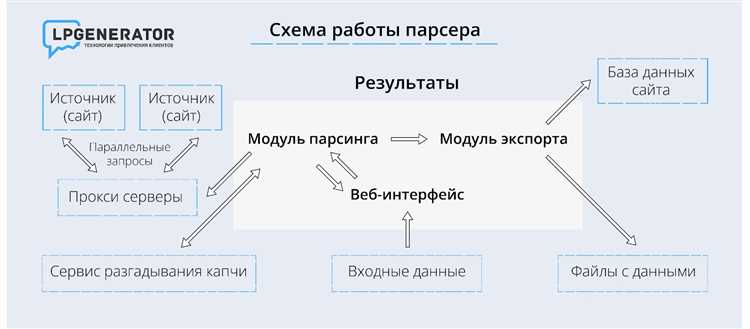
Практика показывает, что устойчивый парсер строится вокруг контроля частоты обращений, сохранения сессий и воспроизведения цепочек действий пользователя. Это включает работу с прокси разного типа, управление cookies между запросами и эмуляцию браузерного окружения на уровне сетевых параметров. Отдельного внимания требует получение данных, загружаемых асинхронно через API, где ошибки чаще связаны не с блокировками, а с неверным порядком запросов.
В статье рассматриваются прикладные подходы к обходу распространённых защит: от анализа правил доступа и сетевых ответов до обработки CAPTCHA и динамического контента. Материал ориентирован на тех, кто работает с реальными проектами и нуждается в предсказуемом результате при сборе данных в условиях ограничений.
Анализ robots.txt, пользовательских соглашений и рисков ответственности
Пользовательские соглашения и условия использования содержат более жёсткие формулировки, чем robots.txt. В них часто прямо указаны запреты на автоматический сбор, агрегацию и повторное использование контента, а также последствия в виде блокировки аккаунтов, ограничения доступа по IP или юридических претензий. Критично проверять разделы, связанные с использованием данных, интеллектуальной собственностью и допустимыми способами доступа, особенно при коммерческом применении результатов парсинга.
Риски ответственности зависят от юрисдикции, характера данных и способа доступа. Сбор открытой информации без авторизации обычно имеет меньшие правовые последствия, чем парсинг личных кабинетов, платных разделов или персональных данных. Отдельную категорию составляют запросы, создающие нагрузку на инфраструктуру сайта, что может трактоваться как вмешательство в работу сервиса.
Практическая рекомендация заключается в фиксации исходных условий: сохранении копий robots.txt и пользовательского соглашения на момент начала работ, документировании целей сбора и ограничении объёма данных минимально необходимым набором. Такой подход снижает вероятность претензий и упрощает аргументацию в случае споров, даже если сайт применяет формальные или скрытые ограничения.
Определение типов антибот-фильтров по сетевым и поведенческим признакам

Идентификация антибот-защиты начинается с анализа сетевых ответов сервера. Изменение HTTP-статусов при росте частоты запросов, подмена кодов 200 на 403 или 429, а также нестабильные редиректы указывают на серверные фильтры. Отдельного внимания требуют ответы с одинаковым HTML, но разным содержимым JavaScript, что часто сигнализирует о подключении внешних антибот-сервисов.
На сетевом уровне следует фиксировать параметры соединения и заголовки:
- несовпадение между User-Agent и набором TLS-расширений;
- появление дополнительных cookies после первого запроса;
- изменение структуры ответов при использовании разных IP-адресов;
- задержки ответа, зависящие от истории запросов.
Поведенческие фильтры выявляются через моделирование пользовательских сценариев. Если последовательные переходы по страницам приводят к доступу, а прямые запросы – к блокировке, значит система отслеживает логику навигации. Типичный признак – требование загрузки вспомогательных ресурсов, таких как шрифты, изображения или служебные JSON-запросы.
Для диагностики поведения используются контролируемые эксперименты:
- изменение интервалов между запросами без смены IP;
- отключение выполнения JavaScript и сравнение ответов;
- повтор запросов с сохранением и без сохранения cookies;
- эмуляция прокрутки, кликов и фокуса вкладки.
Комбинация сетевых и поведенческих признаков позволяет отличить простые лимитирующие механизмы от систем, анализирующих отпечатки браузера и паттерны действий. Точная классификация защиты сокращает число тестовых попыток и снижает вероятность немедленной блокировки, что критично при работе с ограниченными источниками данных.
Работа с лимитами запросов, таймингами и окнами частоты
Большинство сайтов применяет количественные ограничения, привязанные к IP, сессии или комбинации параметров запроса. Типичные пороги находятся в диапазоне от 5–20 запросов в секунду для публичных страниц и 60–300 запросов в минуту для API. Превышение лимита часто приводит к ответам 429 или скрытым санкциям, при которых сервер продолжает отвечать кодом 200, но возвращает усечённые или повторяющиеся данные.
Для устойчивой работы необходимо учитывать временные окна, в рамках которых считаются обращения. Некоторые системы используют скользящее окно в 60 секунд, другие – фиксированные интервалы в 5 или 10 минут. Неправильная оценка окна приводит к накоплению запросов и блокировке даже при умеренной средней нагрузке.
Практический анализ лимитов удобно начинать с контролируемого увеличения частоты и фиксации реакции сервера:
| Параметр | Наблюдение | |
|---|---|---|
| Рост задержки ответа | Увеличение TTFB после серии запросов | Срабатывание мягкого лимита |
| Код 429 | Возврат после N запросов | Жёсткий порог по окну |
| Смена контента | Повторы данных при коде 200 | Тихое ограничение |
Настройка таймингов должна учитывать не только паузы между запросами, но и распределение нагрузки во времени. Использование случайных интервалов в пределах заданного диапазона снижает предсказуемость паттерна. Для каталогов и пагинации разумно закладывать паузы 1–3 секунды между страницами, а для API – выдерживать фиксированный бюджет запросов на минуту с запасом 20–30%.
Дополнительный контроль достигается через раздельные очереди запросов для разных типов ресурсов и обязательную обработку заголовков Retry-After. Соблюдение серверных сигналов позволяет продолжать сбор данных без эскалации ограничений и снижает риск долгосрочных блокировок.
Имитирование поведения браузера через заголовки, cookies и отпечатки
Антибот-системы всё чаще оценивают не отдельный запрос, а целостный профиль клиента. Несогласованность заголовков сразу выделяет автоматизированный трафик: например, наличие User-Agent без соответствующих Accept-Language, Sec-CH-UA или Referer. Набор заголовков должен соответствовать конкретной версии браузера и платформы, включая порядок их передачи и регистр.
Cookies играют ключевую роль в проверке последовательности действий. Многие сайты устанавливают служебные значения уже при первом заходе и ожидают их возврата при следующих запросах. Игнорирование обновлений cookies или их повторное использование между разными IP приводит к сбоям сессии. Корректная стратегия – хранить cookies в изолированном контексте и обновлять их строго по ответам сервера.
Отпечаток браузера формируется на уровне сетевых и клиентских характеристик. Помимо User-Agent учитываются TLS-параметры, порядок расширений, поддержка HTTP/2 и значения заголовков Client Hints. Несовпадение, например, между заявленной версией Chrome и набором шифров в TLS-рукопожатии часто приводит к мгновенной фильтрации запросов.
При работе с JavaScript-защитами важна согласованность окружения выполнения. Значения navigator, screen, timezone и доступность Web API должны соответствовать заявленной платформе. Даже мелкие расхождения, такие как отсутствие canvas или нестандартный размер экрана, используются для классификации клиента.
Практический подход заключается в использовании полноценных браузерных движков или тщательно настроенных HTTP-клиентов с воспроизведёнными отпечатками. Чем ближе поведение запросов к реальной пользовательской сессии, тем ниже вероятность перехода от мягких проверок к жёстким блокировкам.
Получение динамического контента при использовании JavaScript

Сайты с клиентской отрисовкой часто отдают минимальный HTML, а данные подгружаются после выполнения JavaScript через XHR или fetch-запросы. При прямом HTTP-доступе такой ресурс выглядит пустым, поэтому первоочередная задача – определить источники фактических данных. Это делается через анализ сетевой активности в браузере и сопоставление действий пользователя с запросами к API.
На практике динамический контент поступает из нескольких типовых источников:
- JSON-эндпоинты, вызываемые после загрузки страницы;
- GraphQL-запросы с параметрами состояния интерфейса;
- встроенные конфигурационные объекты в JavaScript-файлах;
- данные, возвращаемые только после выполнения цепочки запросов.
Если API защищено, важно воспроизвести порядок запросов и заголовки, которые формирует браузер. Часто сервер ожидает наличие токенов, полученных на предыдущем шаге, или проверяет referer и cookies. Пропуск хотя бы одного вспомогательного запроса приводит к возврату пустых или неполных данных.
В случаях, когда логика генерации данных сильно связана с состоянием DOM, требуется выполнение JavaScript-кода. Для этого используются браузерные движки с возможностью ожидания конкретных событий:
- загрузка всех сетевых запросов;
- появление нужных элементов в DOM;
- изменение состояния после кликов или прокрутки;
- обновление данных при смене фильтров.
Отдельное внимание следует уделять асинхронной подгрузке при пагинации и бесконечной прокрутке. Здесь данные часто загружаются пакетами с курсорами или смещениями, а не с классическими номерами страниц. Фиксация параметров каждого запроса позволяет отказаться от эмуляции интерфейса и перейти к прямому получению данных.
Комбинация анализа сетевых вызовов и выборочного выполнения JavaScript снижает сложность парсинга и уменьшает количество лишних обращений. Чем точнее выделен источник данных, тем ниже вероятность срабатывания защит, связанных с нагрузкой и поведением клиента.
Подходы к взаимодействию с CAPTCHA и интерактивными проверками
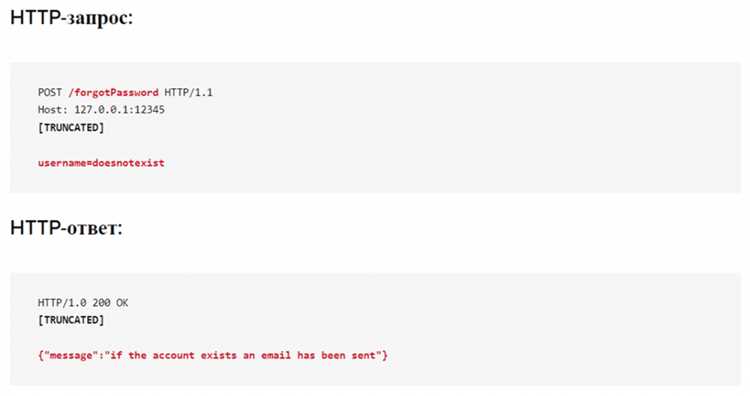
CAPTCHA и интерактивные проверки применяются как финальный уровень фильтрации, когда сетевые и поведенческие признаки вызывают подозрение. Их появление почти всегда контекстно: после серии однотипных запросов, резкой смены IP или некорректной сессии. Первый шаг – зафиксировать условия, при которых проверка возникает, а не пытаться обрабатывать её вслепую.
Существует несколько распространённых сценариев внедрения проверок. Простые варианты ограничиваются отображением статической CAPTCHA в HTML, тогда как более сложные решения интегрируются через JavaScript и взаимодействуют с внешними сервисами. В последнем случае сервер часто ожидает валидный токен, привязанный к отпечатку клиента и времени выполнения сценария.
Практика работы с такими проверками включает:
– снижение частоты запросов и восстановление корректной последовательности действий до появления CAPTCHA;
– сохранение и повторное использование сессий, успешно прошедших проверку;
– разделение потоков трафика, чтобы изолировать источники, провоцирующие проверки.
При неизбежности обработки CAPTCHA важно учитывать её тип. Текстовые и графические варианты чаще зависят от IP и времени, тогда как интерактивные проверки анализируют движения мыши, задержки между событиями и состояние вкладки. Попытка пройти такую проверку без полноценного браузерного окружения обычно приводит к повторному показу или скрытому отказу.
Отдельного внимания требуют проверки, встроенные в API-ответы. В этих случаях сервер возвращает формально корректный статус, но подменяет полезные данные маркером проверки. Фильтрация таких ответов и автоматическая пауза в работе позволяют избежать накопления бесполезных запросов.
Стратегия взаимодействия с CAPTCHA должна быть направлена не на массовое решение, а на минимизацию её появления. Чем реже система доходит до интерактивных проверок, тем стабильнее и предсказуемее сбор данных.
Вопрос-ответ:
Почему сайт начинает возвращать код 200, но данные оказываются пустыми или повторяющимися?
Такое поведение характерно для скрытых ограничений. Сервер формально принимает запрос, но подменяет полезную нагрузку шаблонным ответом или кешированным фрагментом. Это используется, чтобы не выдавать явный признак блокировки. Проверка выполняется сравнением ответов при смене IP, заголовков и пауз между запросами. Если содержимое перестаёт совпадать с браузерной версией страницы, значит сработал фильтр.
Как понять, что сайт отслеживает поведение, а не только частоту запросов?
Признаком поведенческого анализа является зависимость доступа от последовательности действий. Например, прямой запрос к внутренней странице приводит к отказу, а переход по цепочке ссылок — нет. Также показателен запрос загрузки вспомогательных ресурсов: если их отсутствие меняет ответ сервера, значит учитывается модель взаимодействия пользователя со страницей.
Есть ли смысл работать напрямую с API сайта, если он используется фронтендом?
Да, но только после анализа параметров запросов. Часто API ожидает токены, cookies или заголовки, полученные на предыдущих шагах. Без воспроизведения этой логики сервер возвращает ошибку или неполные данные. Важно зафиксировать порядок вызовов и структуру полезной нагрузки, а не копировать одиночный запрос.
Почему CAPTCHA появляется не сразу, а спустя десятки успешных запросов?
Интерактивные проверки активируются при накоплении подозрительных признаков. Это может быть одинаковый интервал между запросами, отсутствие вторичных ресурсов или смена IP без обновления cookies. Система даёт время на сбор сигнала, а затем переводит сессию в режим проверки, вместо немедленного отказа.
Что делать, если robots.txt разрешает доступ, а сайт всё равно блокирует парсер?
robots.txt отражает декларативные правила, но не управляет серверной логикой. Ограничения могут применяться независимо от этого файла и быть описаны в условиях использования. В такой ситуации следует ориентироваться на сетевое поведение сайта: коды ответов, задержки, изменения контента и требования к заголовкам.
Почему смена IP через прокси не снимает блокировку, а сайт продолжает отдавать проверку или пустые ответы?
Многие системы давно не ограничиваются привязкой к IP. Проверка часто строится на связке сетевых параметров, cookies и отпечатка клиента. Если прокси меняется, а сессионные cookies или заголовки остаются прежними, сервер связывает новые запросы с ранее отмеченной активностью. Дополнительным фактором может быть одинаковый порядок запросов и фиксированные интервалы между ними. Для восстановления доступа требуется изоляция сессий, обновление cookies при смене IP и корректировка таймингов, чтобы поведение не выглядело машинным.