Содержание статьи

PostgreSQL предоставляет один из самых широких наборов типов данных среди реляционных СУБД, и выбор конкретного типа напрямую влияет на производительность запросов, объём хранимых данных и корректность бизнес-логики. Например, использование numeric вместо integer в счётчиках увеличивает нагрузку на CPU, а хранение времени событий в timestamp без часового пояса приводит к ошибкам при распределённых системах.
Каждый тип данных в PostgreSQL имеет чёткое назначение и ограничения. Целочисленные типы различаются не только диапазоном значений, но и размером в байтах; строковые типы по-разному участвуют в индексах; jsonb хранится в бинарном виде и поддерживает GIN-индексацию, в отличие от json. Эти различия становятся критичными при проектировании схемы, рассчитанной на миллионы строк и высокую конкуренцию запросов.
PostgreSQL также предлагает типы, отсутствующие в большинстве СУБД: массивы, перечисления (enum), UUID, диапазоны (range), составные структуры. Их использование позволяет сократить количество таблиц, упростить запросы и снизить вероятность логических ошибок, если применять их осознанно. Например, enum надёжнее строк при хранении статусов, а timestamptz предпочтителен для журналирования событий в разных часовых поясах.
Грамотный выбор типов данных в PostgreSQL – это не вопрос удобства, а архитектурное решение. Ошибка на этом уровне редко проявляется сразу, но почти всегда приводит к сложной миграции схемы в будущем. Поэтому понимание возможностей и ограничений встроенных типов – необходимый этап при разработке устойчивых и масштабируемых систем.
Вот детальный план информационной статьи с прикладным фокусом. План состоит ровно из 6 узких заголовков , без подзаголовков:
Структура статьи ориентирована на практическое проектирование схем данных в PostgreSQL и охватывает типы, которые напрямую влияют на точность вычислений, индексацию и масштабируемость.
-
Числовые типы данных PostgreSQL: выбор между integer, numeric и float
Разбор диапазонов значений (smallint, integer, bigint), стоимости операций с numeric, ошибок округления у float4 и float8, рекомендации для финансовых расчётов и агрегатов.
-
Строковые типы данных PostgreSQL: text, varchar и char в реальных задачах
Влияние выбора строкового типа на индексацию, хранение и валидацию данных, причины отсутствия преимуществ у varchar по сравнению с text, редкие сценарии использования char.
-
Типы даты и времени PostgreSQL: date, timestamp и timestamptz
Практика хранения времени событий, работа с часовыми поясами, различия внутреннего представления, рекомендации для логов, аналитики и пользовательских данных.
-
Булевы и перечислимые типы PostgreSQL: boolean и enum для бизнес-логики
Использование boolean для флагов, преимущества enum перед строками, влияние изменений enum-типа на миграции и схемы данных.
-
JSON и JSONB в PostgreSQL: хранение и поиск полуструктурированных данных
Отличия форматов хранения, возможности GIN-индексов, стоимость обновлений, сценарии использования jsonb в API, конфигурациях и интеграциях.
-
Массивы и составные типы PostgreSQL: моделирование сложных структур
Хранение списков значений, работа с массивными операторами, ограничения индексации, сравнение с нормализацией и JSON-подходом.
Числовые типы данных PostgreSQL: выбор между integer, numeric и float
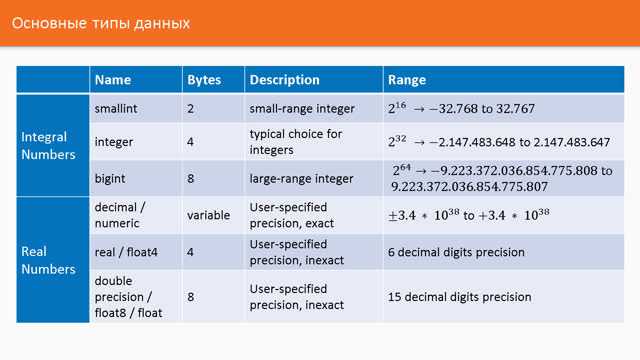
Целочисленные типы PostgreSQL представлены smallint (2 байта, диапазон −32 768…32 767), integer (4 байта, −2 147 483 648…2 147 483 647) и bigint (8 байт, −9,22×1018…9,22×1018). Эти типы используют фиксированное представление и обеспечивают максимальную скорость арифметических операций и агрегаций. Для счётчиков, идентификаторов, количественных показателей и статистики integer или bigint всегда предпочтительнее, так как они не требуют дополнительных вычислений и предсказуемо работают с индексами.
Тип numeric хранит значения в десятичном виде с произвольной точностью и контролируемым масштабом. Он исключает ошибки округления, характерные для бинарной арифметики, но требует больше памяти и CPU. Каждая операция с numeric выполняется программно, а не на уровне процессора, что заметно снижает производительность при массовых вычислениях. Использование numeric оправдано только для финансовых расчётов, тарифов, балансов и других данных, где недопустима потеря копеек или дробных долей.
Типы real (float4) и double precision (float8) используют IEEE-754 и предназначены для хранения приближённых значений. float4 занимает 4 байта и даёт около 6 значащих цифр, float8 – 8 байт и около 15 цифр точности. Эти типы подходят для научных расчётов, телеметрии, координат, показаний датчиков и аналитики, где допустимы погрешности. Для денежных и счётных данных float использовать недопустимо из-за накопления ошибок при суммировании.
При выборе числового типа следует исходить из диапазона значений, требований к точности и объёма данных. Если значение всегда целое – используйте integer или bigint. Если важна десятичная точность – выбирайте numeric с минимально необходимым масштабом. Если приоритетом является скорость и допускается погрешность – применяйте double precision. Ошибка выбора на этом уровне напрямую отражается на производительности запросов и сложности последующих миграций.
Строковые типы данных PostgreSQL: text, varchar и char в реальных задачах
Тип varchar(n) оправдан в сценариях, где длина значения должна быть жёстко ограничена и нарушение этого правила считается ошибкой данных. Примеры – ISO-коды, короткие идентификаторы, фиксированные форматы, передаваемые внешними системами. При этом увеличение значения n в будущем потребует изменения схемы, что делает varchar менее гибким при эволюции модели данных.
Тип char(n) хранит строки фиксированной длины и автоматически дополняет их пробелами. Это приводит к неочевидному поведению при сравнении и может вызывать ошибки в фильтрации и индексах. В современных схемах PostgreSQL char практически не используется, за исключением совместимости с устаревшими системами или строго фиксированных форматов, где наличие пробелов имеет смысл.
Для всех строковых типов максимальный размер значения ограничен 1 ГБ, а длинные строки автоматически выносятся в TOAST-хранилище без участия разработчика. При работе с индексами следует учитывать, что B-tree индексируется только начало строки, а для полнотекстового поиска и структурированных данных предпочтительнее специализированные механизмы. В подавляющем большинстве прикладных задач использование text является оптимальным и безопасным выбором.
Типы даты и времени PostgreSQL: date, timestamp и timestamptz
Тип date хранит только календарную дату без времени и занимает 4 байта. Он подходит для дней рождения, дат договоров, расчётов по дням и отчётных периодов, где время суток не имеет смысла. Использование date упрощает сравнения и исключает ошибки, связанные с часовыми поясами и переходами на летнее время.
Тип timestamp without time zone хранит дату и время с точностью до микросекунд, но не содержит информации о часовом поясе. Значение интерпретируется так, как будто оно находится в локальном времени приложения. Это допустимо только в изолированных системах с одним часовым поясом. В распределённых сервисах и при интеграциях такой выбор приводит к смещению времени при агрегациях и аналитике.
| Тип | Что хранит | Рекомендуемое применение |
|---|---|---|
| date | Дата без времени | Календарные даты, отчётные периоды |
| timestamp | Дата и время без часового пояса | Локальные системы с фиксированным временем |
| timestamptz | Момент времени в UTC | События, логи, распределённые приложения |
При проектировании схемы данных следует явно выбирать семантику времени. Если важен сам момент события – используйте timestamptz. Если важен только календарный день – date. Применение timestamp без часового пояса оправдано редко и должно быть зафиксировано в архитектурных решениях, иначе ошибки проявятся при масштабировании и аналитике.
Булевы и перечислимые типы PostgreSQL: boolean и enum для бизнес-логики
Тип boolean в PostgreSQL занимает 1 байт и принимает значения true, false и NULL. Он предназначен для флагов и бинарных состояний, где третье значение используется для обозначения отсутствия данных. Для полей вроде активности, видимости, завершённости операций boolean предпочтительнее целых чисел и строк, так как исключает неоднозначную интерпретацию и упрощает условия в запросах.
Перечислимый тип enum позволяет задать фиксированный набор допустимых строковых значений и хранится как внутренний идентификатор, а не как текст. Это делает сравнения быстрее, чем у строк, и гарантирует целостность данных без дополнительных ограничений. enum подходит для статусов заказов, этапов процессов и ролей, где список значений известен заранее и меняется редко.
Главное ограничение enum связано с изменением набора значений. Добавление нового элемента возможно, но его позиция влияет на порядок сортировки, а удаление или переименование требуют сложных миграций. Поэтому enum не следует использовать для часто изменяемых справочников. В таких случаях предпочтительнее отдельные таблицы со внешними ключами.
Выбор между boolean и enum определяется количеством допустимых состояний и стабильностью бизнес-правил. Для двух чётко определённых вариантов используйте boolean. Для ограниченного и устойчивого набора статусов – enum. Использование строк вместо этих типов увеличивает риск некорректных значений и усложняет поддержку схемы при росте системы.
JSON и JSONB в PostgreSQL: хранение и поиск полуструктурированных данных
PostgreSQL поддерживает два формата хранения JSON-данных: json и jsonb. Тип json сохраняет исходное текстовое представление и выполняет разбор данных при каждом обращении. Это делает его пригодным только для редкого чтения и ситуаций, где важна точная сохранность формата входных данных, включая порядок ключей и пробелы.
Тип jsonb хранит данные в бинарном виде, нормализует структуру и удаляет дублирующиеся ключи. Такое представление ускоряет чтение, сравнение и фильтрацию значений, но увеличивает стоимость вставки и обновления. Для прикладных систем, где JSON используется в запросах и условиях, jsonb является стандартным выбором.
jsonb поддерживает индексацию с использованием GIN, что позволяет эффективно выполнять поиск по ключам и значениям даже при больших объёмах данных. Однако каждый индекс увеличивает размер базы и замедляет операции записи, поэтому индексировать следует только те поля, которые реально участвуют в фильтрации. Хранение глубоко вложенных структур без индексов приводит к последовательным сканированиям и росту времени ответа.
JSON-типы не заменяют реляционную модель, а дополняют её. Они подходят для хранения конфигураций, метаданных, динамических атрибутов и данных от внешних API. Если структура стабилизировалась и используется в JOIN-ах или агрегатах, её следует вынести в отдельные колонки или таблицы. Использование jsonb оправдано только там, где гибкость важнее строгой схемы.
Массивы и составные типы PostgreSQL: моделирование сложных структур

Массивы в PostgreSQL позволяют хранить несколько значений одного типа в одном поле, включая многомерные структуры. Они подходят для фиксированных списков, таких как наборы тегов, идентификаторы связанных объектов или предопределённые параметры. Операции с массивами выполняются на уровне СУБД, но при росте размера массива увеличивается стоимость обновлений, так как значение перезаписывается целиком.
Индексация массивов возможна с использованием GIN, что ускоряет поиск по элементам, но увеличивает объём индексов и замедляет вставки. Если элементы массива часто участвуют в фильтрации, индекс оправдан; если массив используется только для хранения, его создание нецелесообразно. Для сложных запросов с агрегациями и JOIN-ами массивы уступают нормализованным таблицам.
Составные типы позволяют определить структуру из нескольких полей и использовать её как единое значение. Они удобны для логического объединения связанных атрибутов, например координат, диапазонов или параметров конфигурации. Такие типы повышают читаемость схемы, но ограничены в индексации и не поддерживают частичные обновления отдельных полей без перезаписи всего значения.
Выбор между массивами, составными типами и классической нормализацией зависит от характера доступа к данным. Если элементы редко изменяются и используются как целое, массивы и составные типы упрощают модель. Если требуется частый поиск, агрегация и связывание данных, предпочтительнее отдельные таблицы. Использование сложных типов оправдано только при чётко ограниченных сценариях доступа.
Вопрос-ответ:
Почему в PostgreSQL чаще рекомендуют использовать text вместо varchar?
Типы text и varchar обрабатываются PostgreSQL одинаково: они занимают одинаковый объём памяти, одинаково индексируются и не отличаются по скорости операций. Ограничение длины у varchar(n) работает только как проверка при вставке данных. Если длина строки не участвует в правилах предметной области, text избавляет от лишних ограничений и снижает вероятность будущих миграций схемы.
В каких случаях numeric оправдан, несмотря на более низкую производительность?
numeric подходит для хранения значений, где требуется точная десятичная арифметика: суммы денег, комиссии, проценты, бухгалтерские расчёты. В этих сценариях недопустимы ошибки округления, характерные для float. При больших объёмах данных следует задавать минимально допустимую точность и масштаб, чтобы снизить нагрузку на процессор.
Чем timestamp без часового пояса опасен в реальных системах?
timestamp without time zone не хранит информацию о временной зоне и интерпретируется в контексте текущих настроек сессии. При обмене данными между сервисами или пользователями из разных регионов это приводит к смещению времени событий. Для логов, очередей и аудита корректным выбором является timestamptz, который хранит момент времени в UTC.
Стоит ли использовать enum для статусов, если список может измениться?
enum подходит только для наборов значений, которые меняются редко. Добавление нового элемента возможно, но удаление или переименование требует сложных операций. Если статусы зависят от бизнес-правил, которые часто пересматриваются, лучше использовать отдельную таблицу со строковым ключом и внешними ссылками.
Когда массивы в PostgreSQL становятся плохим решением?
Массивы неудобны, если элементы нужно часто фильтровать, агрегировать или связывать с другими таблицами. Обновление одного элемента приводит к перезаписи всего массива, а сложные условия быстро ухудшают читаемость запросов. В таких случаях нормализованная структура с отдельной таблицей даёт более предсказуемое поведение.