Содержание статьи

Сканы документов – это изображения, а не текстовые файлы. Чтобы редактировать их содержимое в Word, требуется распознавание текста (OCR). Современные инструменты справляются с этой задачей за несколько минут, но качество результата зависит от исходного качества скана. Разрешение не менее 300 DPI и четкие контрастные символы – обязательные условия для точного распознавания.
Для конвертации используйте специализированные программы или онлайн-сервисы. ABBYY FineReader (версия 15 и новее) распознает текст с точностью до 99,8% при правильных настройках, поддерживает более 200 языков и сохраняет форматирование. Adobe Acrobat Pro также включает OCR-модуль, но требует ручной корректировки шрифтов и выравнивания. Бесплатные альтернативы, такие как OnlineOCR.net или New OCR, подходят для разовых задач, но ограничены по объему и функциональности.
Перед конвертацией отсканируйте документ в формате PDF или TIFF – эти форматы лучше всего обрабатываются OCR-системами. Избегайте JPEG: сжатие снижает качество изображения, что приводит к ошибкам распознавания. Если скан уже в JPEG, увеличьте контрастность в графическом редакторе (например, GIMP или Photoshop) перед загрузкой в OCR-инструмент.
После конвертации обязательно проверьте результат в Word. Частые ошибки: замена букв (например, «о» на «0»), неправильное распознавание знаков препинания и потеря форматирования. Используйте встроенные инструменты Word для поиска и замены (Ctrl+H) или сторонние плагины, такие как Kutools for Word, для массовой корректировки. Для документов с таблицами выбирайте OCR-инструменты с поддержкой табличного распознавания (ABBYY FineReader или Amazon Textract).
Какие программы распознают текст со сканов и фотографий
ABBYY FineReader – эталон OCR-технологий с поддержкой 200+ языков, включая редкие (например, каталанский или вьетнамский). Распознаёт таблицы, колонтитулы, сноски и сохраняет исходное форматирование при экспорте в Word, Excel или PDF. Версия FineReader PDF 16 обрабатывает даже низкокачественные сканы (разрешение от 75 dpi) и исправляет перспективные искажения на фотографиях документов. Для бизнеса доступна облачная платформа FineReader Server с пакетной обработкой до 10 000 страниц в час.
Бесплатные альтернативы: Tesseract OCR (от Google, точность до 98% на чётких изображениях, но требует ручной настройки параметров через командную строку) и OnlineOCR.net (до 15 страниц в час без регистрации, поддерживает 46 языков). Для мобильных устройств – Microsoft Lens (интеграция с OneNote, автоматическое обрезание фона) и Text Fairy (офлайн-режим, распознавание рукописного текста с точностью ~85%).
Как подготовить изображение перед конвертацией в Word
Используйте черно-белое изображение вместо цветного или полутонового. Цветные сканы увеличивают объем файла в 3–5 раз и усложняют распознавание из-за шумов и градиентов. Конвертируйте изображение в монохромный режим через инструменты вроде Adobe Photoshop (Изображение → Режим → Bitmap) или бесплатные редакторы типа GIMP (Изображение → Режим → Индексированные → Черно-белое (1 бит)).
Обрежьте лишние поля и фоны. Даже 5 мм пустого пространства вокруг текста снижают точность OCR на 5–10%. Инструменты для обрезки: Snipping Tool (Windows), Preview (macOS) или онлайн-сервисы вроде Online-Convert.com. Убедитесь, что текст расположен параллельно границам изображения – наклон более 2° требует ручной корректировки или функции автоповорота в программах типа ABBYY FineReader.
Удалите артефакты сканирования: пятна, полосы, тени от переплета. Для этого подойдут фильтры «Удаление шума» в Photoshop или «Улучшение резкости» в GIMP. Если на скане есть цветные пометки или подчеркивания, временно удалите их – они могут быть распознаны как часть текста. Для массовой очистки используйте пакетную обработку в XnConvert или IrfanView.
Выровняйте текст, если он расположен под углом. Даже незначительный наклон (1–3°) увеличивает количество ошибок OCR на 8–12%. В ABBYY FineReader выберите «Автоматическое выравнивание страницы», в Tesseract OCR используйте параметр --psm 6 для анализа ориентации. Для ручной корректировки в Photoshop примените инструмент «Трансформация → Искажение».
Увеличьте контрастность текста и фона. Идеальное соотношение – черный текст на белом фоне с яркостью не менее 80% для фона и не более 20% для текста. Настройте уровни в Photoshop (Изображение → Коррекция → Уровни) или используйте онлайн-инструмент Photopea. Избегайте серых оттенков – они распознаются хуже, чем чистый черный.
Разбейте многостраничные документы на отдельные файлы. Программы OCR часто обрабатывают страницы последовательно, и ошибка на одной из них может повлиять на результат всей пачки. Сохраняйте файлы в формате TIFF или PNG – они поддерживают сжатие без потерь, в отличие от JPEG, который вносит артефакты. Для массового разделения PDF используйте PDF24 Tools или Smallpdf.
Проверьте шрифты. Если текст набран декоративным или рукописным шрифтом, точность распознавания упадет до 40–60%. Для таких случаев используйте специализированные OCR-движки, например, Google Cloud Vision API или Amazon Textract, которые лучше справляются с нестандартными гарнитурами. Для печатных документов с шрифтами Times New Roman, Arial или Calibri стандартные инструменты (ABBYY, Tesseract) дают точность 95–98%.
Пошаговая инструкция по конвертации через ABBYY FineReader
Настройте параметры распознавания до начала конвертации: в панели инструментов перейдите в «Инструменты» → «Опции» → «Распознавание». Для текстов на русском языке установите язык «Русский», для смешанных документов добавьте английский. Включите опцию «Сохранять форматирование» и отметьте «Распознавать таблицы» – это критично для документов с финансовыми отчётами или техническими спецификациями. Для сканов низкого качества (разрешение ниже 300 dpi) активируйте «Улучшение изображения» в разделе «Предобработка».
Запустите процесс распознавания кнопкой «Распознать». После завершения проверьте результат в окне предварительного просмотра: выделите фрагменты текста, чтобы убедиться в корректности разбиения на абзацы и сохранении шрифтового оформления. Обратите внимание на колонтитулы и сноски – FineReader часто ошибается с их позиционированием. Исправьте ошибки вручную: выделите неверно распознанный текст и введите правильный вариант в панели редактирования. Для массовых исправлений используйте функцию «Найти и заменить» (Ctrl+H).
Экспортируйте документ в Word через «Файл» → «Сохранить как» → «Microsoft Word». Выберите формат DOCX для полной совместимости с последними версиями Word. В окне настроек экспорта отключите «Вставлять изображения как OLE-объекты» – это предотвратит раздувание размера файла. Для документов с таблицами включите «Сохранять структуру таблиц» и выберите опцию «Использовать стили Word для форматирования». Сохраните файл и откройте его в Word для финальной проверки: сравните исходный скан с полученным документом, уделив внимание выравниванию текста и целостности таблиц.
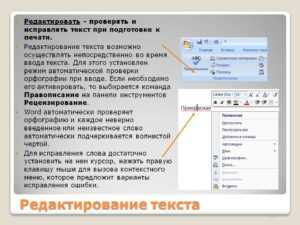
Как исправить ошибки распознавания после конвертации
Первым шагом после конвертации скана в Word проверьте текст на наличие типичных ошибок OCR: замену букв на похожие символы (например, «о» на «0», «л» на «1»), пропуски или дублирование слов, неверное разбиение абзацев. Чаще всего страдают шрифты с засечками (Times New Roman) и мелкий кегль (менее 10 пт). Используйте функцию «Найти и заменить» (Ctrl+H) для массовой правки: введите ошибочные символы в поле «Найти» и корректные – в «Заменить на». Например, замените все «п0» на «по» или «1е» на «ле».
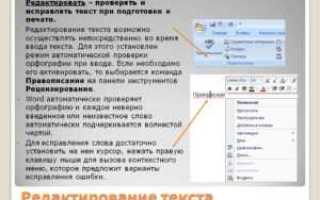
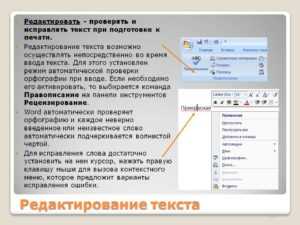
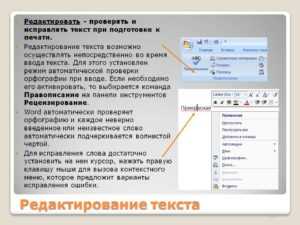
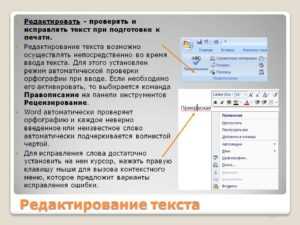
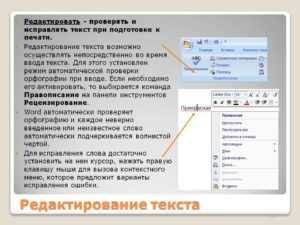
Для проверки орфографии активируйте встроенную проверку Word: перейдите в «Рецензирование» → «Правописание» или нажмите F7. Однако учтите, что стандартный словарь не распознает узкоспециализированные термины, имена собственные или аббревиатуры. Добавьте их в пользовательский словарь, чтобы избежать ложных срабатываний. Если документ содержит много технических терминов, установите расширение LanguageTool (поддерживает русский язык) – оно анализирует контекст и выявляет ошибки, которые пропускает Word.
Обратите внимание на форматирование: OCR-системы часто путают выделение текста (полужирный, курсив) или игнорируют его. Восстановите стили вручную, сравнивая с исходным сканом. Если в документе есть таблицы, проверьте их структуру: ячейки могут сливаться или разделяться неверно. Используйте инструмент «Нарисовать таблицу» (вкладка «Макет») для исправления границ. Для сложных таблиц с объединёнными ячейками проще создать новую таблицу и перенести данные вручную.
Сравните конвертированный текст с оригиналом построчно. Для этого откройте скан в отдельном окне и расположите его рядом с документом Word. Если объём текста большой, используйте программу WinMerge или Diffchecker – они подсвечивают различия между файлами. Особое внимание уделите цифрам, датам и формулам: OCR часто ошибается в них из-за мелкого шрифта или нестандартного начертания. Для формул лучше использовать специализированные инструменты вроде MathType или встроенный редактор формул Word (вкладка «Вставка» → «Формула»).
Если в тексте много ошибок из-за низкого качества скана, попробуйте повторно обработать изображение перед конвертацией. Увеличьте контрастность (например, в Adobe Photoshop: «Изображение» → «Коррекция» → «Яркость/Контрастность»), удалите шумы («Фильтр» → «Шум» → «Уменьшить шум») и выровняйте наклон («Изображение» → «Поворот изображения»). Для автоматической предобработки используйте бесплатные инструменты вроде ScanWritr или OnlineOCR.net – они предлагают базовые настройки улучшения сканов.
Для документов с нестандартными шрифтами (например, готические или рукописные) OCR может работать некорректно. В таких случаях выделите проблемный фрагмент и вручную измените шрифт на стандартный (Arial, Calibri). Если текст содержит лигатуры (например, «ffi» или «fl»), замените их на отдельные символы. Для редких шрифтов установите их в систему перед конвертацией – это повысит точность распознавания. Программы вроде ABBYY FineReader позволяют вручную задавать шрифт для отдельных участков текста.
Автоматизируйте исправление повторяющихся ошибок с помощью макросов в Word. Запишите макрос («Вид» → «Макросы» → «Записать макрос»), выполнив последовательность действий для исправления одной ошибки, затем запустите его для всего документа. Например, макрос может заменять все «т0» на «то» и одновременно исправлять регистр следующего слова. Для сложных сценариев используйте VBA-скрипты: они позволяют обрабатывать текст по заданным правилам (например, исправлять падежи после предлогов).
После правки экспортируйте документ в PDF и сравните его с исходным сканом. Используйте режим наложения в Adobe Acrobat («Инструменты» → «Сравнить файлы») или бесплатные онлайн-сервисы вроде Draftable. Это поможет выявить пропущенные ошибки или несоответствия в форматировании. Если документ предназначен для печати, распечатайте тестовую страницу и сверьте её с оригиналом – на бумаге часто заметны детали, ускользнувшие на экране.
Способы конвертации скана в Word без установки программ
Google Диск интегрирован с инструментом распознавания текста Google Keep. Загрузите скан в формате JPG или PNG на Диск, щелкните правой кнопкой мыши по файлу и выберите «Открыть с помощью» → «Google Документы». Система автоматически извлечет текст, сохранив его в новом документе. Ограничение: работает только с латиницей и кириллицей, не поддерживает таблицы и сложное форматирование. Для многостраничных документов используйте PDF – Диск распознает текст из него напрямую.
Встроенные средства Windows 10/11 позволяют конвертировать сканы через приложение OneNote. Откройте программу, создайте новую заметку, перейдите в «Вставка» → «Изображение» и выберите файл. Щелкните правой кнопкой по загруженному скану и выберите «Копировать текст с изображения». Вставьте текст в Word и отредактируйте вручную. Метод эффективен для простых документов с четким шрифтом (например, Arial, Times New Roman) размером от 12 пт. Для таблиц и колонок точность падает до 70%.
Мобильные приложения без установки на ПК – вариант для срочной конвертации. Microsoft Lens (доступен в браузере через office.com/launch/lens) сканирует документы с камеры телефона, распознает текст и экспортирует в Word. Для работы требуется учетная запись Microsoft. Альтернатива – Text Fairy (Android), которая обрабатывает изображения из галереи и сохраняет результат в TXT или DOCX. Оба приложения поддерживают русский язык, но требуют ручной корректировки при низком качестве скана.
Для конвертации PDF-сканов используйте Smallpdf (smallpdf.com/ru/pdf-to-word). Сервис распознает текст в PDF с точностью до 90% при условии, что файл не защищен паролем. Загрузите документ, дождитесь обработки (1–2 минуты) и скачайте DOCX. Ограничение: бесплатная версия позволяет конвертировать только 2 файла в час. Для многостраничных документов выбирайте режим «Распознавание текста» вместо «Сохранить как изображение».
Браузерные расширения ускоряют процесс, но ограничены функционалом. Project Naptha (для Chrome) выделяет текст на любом изображении в браузере и позволяет скопировать его в буфер обмена. Подходит для небольших фрагментов (например, цитат), но не для объемных документов. Для полноценной конвертации используйте Online2PDF (online2pdf.com/ru/ocr-pdf), который обрабатывает до 20 файлов за раз и поддерживает пакетную загрузку. Оба инструмента не сохраняют исходное форматирование, поэтому редактирование в Word потребует дополнительного времени.
Какие форматы файлов лучше использовать для сканирования текста
Для сканирования текста с целью последующего распознавания и редактирования в Word оптимальны три формата: PDF, TIFF и PNG. PDF – универсальный выбор, особенно если документ содержит смешанный контент (текст + изображения). Современные OCR-системы (например, ABBYY FineReader или Adobe Acrobat) работают с PDF на уровне слоёв, сохраняя исходное качество и позволяя извлекать текст с минимальными ошибками. TIFF предпочтителен для чёрно-белых документов с высокой детализацией – формат поддерживает сжатие без потерь (LZW или CCITT Group 4), что критично для старых текстов с мелким шрифтом или рукописными пометками. PNG подходит для цветных сканов с графикой, но из-за отсутствия поддержки многостраничности требует дополнительной обработки при работе с объёмными документами.
Избегайте форматов JPEG и BMP. JPEG, несмотря на популярность, использует сжатие с потерями, что приводит к размытию границ символов и артефактам – это снижает точность распознавания на 15–25% по сравнению с TIFF или PDF. BMP, хотя и сохраняет качество, создаёт огромные файлы (до 100 МБ на страницу), что замедляет обработку и увеличивает нагрузку на OCR-движки. Если сканер по умолчанию предлагает эти форматы, измените настройки на PDF или TIFF с разрешением 300–600 DPI – этого достаточно для чёткого распознавания даже мелкого текста (кегль 8–10 пт).
- PDF/A – идеален для архивных документов, так как гарантирует долговременное хранение без потери данных.
- TIFF с разрешением 600 DPI – лучший вариант для технической документации или текстов с низким контрастом.
- PNG (24-битный) – подходит для сканов с цветными выделениями или таблицами, но только для одностраничных файлов.