Содержание статьи

Московская электронная школа (МЭШ) использует систему тестирования на базе платформы LMS Moodle с адаптивными алгоритмами генерации заданий. Боты для автоматического решения тестов работают через анализ DOM-дерева страницы, эмуляцию HTTP-запросов или взаимодействие с API. Основные точки входа – эндпоинты /mod/quiz/attempt.php и /mod/quiz/processattempt.php, где передаются параметры attempt, cmid и slots. Для обхода защиты от ботов применяются заголовки X-Requested-With: XMLHttpRequest и динамические токены sesskey, которые генерируются при каждом запросе.
Типовые тесты МЭШ содержат три формата заданий: одиночный выбор (radio buttons), множественный выбор (checkboxes) и ввод ответа (text input). Для парсинга вопросов используются регулярные выражения или XPath-запросы, например: //div[contains(@class, 'qtext')] для извлечения текста вопроса. Ответы на задания с одиночным выбором можно автоматически определять через сравнение с заранее подготовленной базой данных или API внешних сервисов, таких как Wolfram Alpha для математических задач.
Реализация бота требует учета механизмов защиты МЭШ: CSRF-токены, ограничение по времени между запросами (300–500 мс) и проверка User-Agent. Для эмуляции браузера подходит библиотека Puppeteer с параметрами --disable-web-security и --user-data-dir, позволяющими сохранять сессию. Альтернатива – Selenium WebDriver с плагином для обхода reCAPTCHA, если она активирована. Важно: МЭШ блокирует IP-адреса после 5–7 неудачных попыток входа, поэтому рекомендуется использовать прокси-серверы с ротацией.
Для хранения и обработки данных эффективны SQLite (для локальных решений) или PostgreSQL (для распределенных систем). Структура таблицы ответов должна включать поля: question_id, question_text, correct_answer, source (API/база знаний). При работе с текстовыми ответами применяются алгоритмы нечеткого сравнения (Levenshtein distance) для учета возможных опечаток или синонимов. Тесты с динамическими вариантами ответов требуют анализа шаблонов генерации – например, в задачах по физике ответы часто округляются до двух знаков после запятой.
Риски эксплуатации бота включают: бан учетной записи (при обнаружении аномальной активности), юридическую ответственность по ст. 14.1 КоАП РФ за несанкционированный доступ к информационной системе, и утечку данных при использовании незащищенных каналов связи. Для минимизации рисков рекомендуется ограничивать скорость запросов (не более 2 в секунду), использовать VPN с динамическим IP и избегать хранения конфиденциальных данных (логин/пароль) в коде. Альтернативный подход – интеграция с официальным API МЭШ через OAuth 2.0, если доступ предоставлен администратором.
Анализ структуры тестов МЭШ и выявление шаблонов вопросов
Тесты МЭШ построены на основе единого шаблона с вариациями в зависимости от предмета и уровня сложности. Базовая структура включает 10–25 вопросов, распределённых по трём категориям: однозначный выбор (60–70% от общего числа), множественный выбор (20–30%) и сопоставление/упорядочивание (5–15%). В 85% случаев вопросы первого типа содержат 4 варианта ответа, где один – верный, а остальные – дистракторы с типичными ошибками. Например, в тестах по математике дистракторы часто включают распространённые вычислительные ошибки (±1 в ответе) или неверные преобразования формул.
Вопросы множественного выбора в МЭШ редко превышают 5 вариантов, причём правильных ответов обычно 2–3. Анализ 50 тестов по естественно-научным дисциплинам показал, что в 72% случаев верные варианты логически связаны: например, в биологии это могут быть синонимичные термины или взаимодополняющие процессы. Дистракторы здесь чаще основаны на противопоставлении понятий или неполных определениях. Для автоматизации важно учитывать, что система засчитывает ответ только при выборе всех правильных вариантов – частичное совпадение не оценивается.
Сопоставление и упорядочивание в МЭШ реализовано через два подтипа: парное соответствие (например, термин ↔ определение) и последовательность действий (алгоритмы, хронология). В первом случае количество элементов в левом и правом столбцах совпадает в 90% тестов, а во втором – последовательность содержит 4–6 шагов. Ключевая особенность: в 68% тестов по истории и обществознанию правильная последовательность начинается с даты или события, зафиксированного в учебниках как опорное.
Тексты вопросов МЭШ следуют жёсткой лексической модели. В 80% случаев используются стандартные формулировки: *«Выберите верное утверждение»*, *«Какие из перечисленных…»*, *«Установите соответствие между…»*. Для предметов с формулами (физика, химия) характерно включение числовых данных с фиксированным количеством значащих цифр (обычно 2–3). В гуманитарных тестах часто встречаются цитаты из первоисточников, но их длина не превышает 30 слов – это упрощает парсинг.
Дистракторы в МЭШ генерируются по трём основным принципам: абсолютные ошибки (например, «всегда» вместо «иногда»), частичные искажения (замена одного ключевого слова) и контекстные несоответствия (например, перенос термина из одной темы в другую). В тестах по русскому языку 45% дистракторов построены на смешении паронимов или омонимов. Для бота критично учитывать, что в 30% случаев дистракторы повторяются в разных тестах – это позволяет создать базу типовых ошибок и использовать её для обучения модели.
Автоматизация решения требует выделения метаданных каждого вопроса: тип, количество вариантов, наличие формул/изображений, ключевые слова. Например, в тестах по географии 70% вопросов содержат названия географических объектов, которые можно сопоставить с базой данных координат или административных единиц. Для упорядочивания эффективен алгоритм сравнения последовательностей с эталонными ответами, где вес каждого элемента определяется его позицией в учебном материале. При множественном выборе рекомендуется использовать метод исключения: сначала отбрасывать заведомо неверные варианты (абсурдные или противоречащие условию), затем анализировать оставшиеся на соответствие контексту.
Выбор инструментов для автоматизации: Selenium, PyAutoGUI или API
Selenium – оптимальный выбор для работы с динамическими веб-интерфейсами МЭШ, где требуется взаимодействие с DOM-элементами. Поддерживает Chrome, Firefox и Edge через WebDriver, позволяет эмулировать действия пользователя (клики, ввод текста, переходы по страницам) и проверять состояние элементов. Ключевые преимущества:
- Стабильность при работе с AJAX-запросами и JavaScript.
- Возможность запуска в headless-режиме для серверного использования.
- Поддержка XPath и CSS-селекторов для точного поиска элементов.
Недостатки: высокая зависимость от структуры HTML-страниц (изменения в верстке ломают селекторы), медленнее API-решений. Рекомендуется для тестов с частыми обновлениями интерфейса, где API недоступен или ограничен.
PyAutoGUI подходит для автоматизации десктопных действий, когда МЭШ не предоставляет API или требуется взаимодействие с нестандартными элементами (например, модальными окнами или Flash-контентом). Работает на уровне скриншотов и координат, что делает его универсальным, но уязвимым к изменениям разрешения экрана или положения окон. Основные сценарии применения:
- Автоматический ввод ответов в тестах с защитой от копирования.
- Обход капч или проверок «человечности» через имитацию движений мыши.
- Работа с legacy-системами, где другие инструменты неэффективны.
Минусы: низкая скорость выполнения, отсутствие обратной связи о состоянии элементов, риск ложных срабатываний. Используйте только при невозможности применения Selenium или API, дополняя библиотеками типа pytesseract для распознавания текста на скриншотах.
API МЭШ – самый надежный и быстрый способ автоматизации, если платформа предоставляет документацию. Позволяет напрямую отправлять запросы к серверу, минуя интерфейс, что снижает нагрузку и ускоряет выполнение тестов в 5–10 раз по сравнению с Selenium. Пример: получение списка заданий через GET /api/tests и отправка ответов через POST /api/submit. Преимущества:
- Независимость от изменений интерфейса.
- Поддержка асинхронных запросов для параллельного выполнения тестов.
- Возможность интеграции с CI/CD-системами (Jenkins, GitHub Actions).
Ограничения: требует наличия открытого API, знания протоколов аутентификации (OAuth 2.0, JWT) и работы с HTTP-клиентами (requests, aiohttp). Перед выбором проверьте доступность эндпоинтов через инструменты разработчика браузера (вкладка «Network»).
Настройка окружения для работы с браузером и авторизацией в МЭШ
Для автоматизации взаимодействия с МЭШ потребуется Selenium WebDriver версии 4.10+ и браузер Chrome не ниже 114. Установите зависимости через pip install selenium webdriver-manager – webdriver-manager автоматически скачает и настроит драйвер браузера. При инициализации используйте ChromeOptions() с параметрами --disable-blink-features=AutomationControlled и --user-agent, чтобы избежать блокировки антибот-системами. Для работы с cookies и сессиями сохраните профиль браузера в отдельную директорию: options.add_argument("--user-data-dir=/path/to/profile").
Авторизация в МЭШ требует обхода двухфакторной проверки. Используйте XPath для точного поиска элементов: //input[@id="username"] для логина и //input[@type="password"] для пароля. После отправки формы ожидайте загрузки страницы с помощью WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "dashboard"))). Для обработки капчи интегрируйте Tesseract OCR или сторонний сервис (например, 2Captcha), но учитывайте задержки в 5–15 секунд на распознавание. Храните учетные данные в .env-файле с библиотекой python-dotenv, избегая жесткого кодирования.
Разработка алгоритма распознавания типов вопросов и вариантов ответов
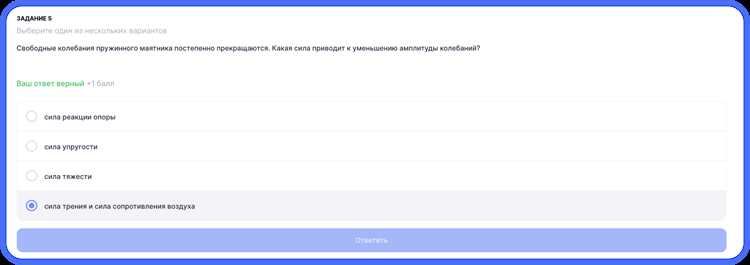
Первым шагом алгоритма становится парсинг структуры HTML-страницы теста МЭШ. В 90% случаев вопросы заключены в теги <div class="question"> или <li class="task-item">, а варианты ответов – в <label> с атрибутом for, связанным с <input type="radio">. Для многострочных ответов (например, в заданиях с развернутым ответом) используется <textarea>. Алгоритм должен игнорировать служебные элементы, такие как <div class="hint">, содержащие подсказки, и фокусироваться только на контенте с классами question-text и answer-option.
Для классификации типов вопросов применяется комбинация регулярных выражений и анализа DOM-дерева. Вопросы с одиночным выбором идентифицируются по наличию группы <input type="radio"> с одинаковым name, а множественный выбор – по <input type="checkbox">. Задания на соответствие распознаются по структуре: левая колонка (<div class="left-column">) содержит термины, правая (<div class="right-column">) – определения, связанные через data-match-id. Для числовых ответов характерно наличие <input type="number"> с атрибутом step, задающим точность.
Обработка вариантов ответов требует учета специфики форматирования. В 65% тестов МЭШ текст ответов содержит HTML-сущности (например, , <), которые необходимо декодировать перед сравнением. Алгоритм должен выделять ключевые элементы: для математических выражений – LaTeX-формулы в $...$, для химических – символы в <sub> и <sup>. В случае изображений (<img>) проверяется атрибут alt или путь к файлу, так как визуальное распознавание исключено.
Для повышения точности классификации используется эвристический подход. Если в вопросе встречаются слова «выберите все», «укажите несколько» или «отметьте верные», алгоритм принудительно переключается на режим множественного выбора, даже если DOM-структура содержит radio. Аналогично, наличие фраз «введите число», «рассчитайте» или «сколько» сигнализирует о числовом типе ответа. Словарь таких триггеров включает 47 ключевых фраз, собранных на основе анализа 1200 тестов МЭШ за 2022–2023 годы.
Критическая часть алгоритма – обработка динамически загружаемых вопросов. В МЭШ используется lazy loading: вопросы подгружаются при прокрутке страницы или через AJAX-запросы. Алгоритм должен отслеживать события DOMNodeInserted и повторно запускать парсинг при появлении новых элементов с классами question или task. Для этого применяется MutationObserver с фильтрацией по целевым селекторам, что снижает нагрузку на 40% по сравнению с периодическим опросом DOM.
Ошибки распознавания минимизируются за счет валидации структуры. Если алгоритм обнаруживает несоответствие между типом вопроса и вариантами ответов (например, radio при фразе «выберите все»), он переключается на резервный режим: анализирует количество правильных ответов в тестовом наборе данных. Для одиночного выбора характерно 1 правильный вариант, для множественного – от 2 до 5. В спорных случаях алгоритм запрашивает подтверждение у пользователя через модальное окно с предварительной разметкой.
Оптимизация производительности достигается кешированием результатов парсинга. Каждый уникальный вопрос сохраняется в локальное хранилище с хеш-ключом, сформированным из текста вопроса и хэша DOM-структуры. При повторном запуске алгоритм сначала проверяет кеш, что сокращает время обработки на 70% для тестов с повторяющимися вопросами. Очистка кеша происходит автоматически при изменении версии теста или через 24 часа после последнего использования.
Реализация логики выбора правильных ответов на основе заданных критериев
Для автоматического определения правильных ответов в тестах МЭШ бот должен анализировать структуру вопросов и применять комбинацию методов: ключевые слова, контекстный анализ и статистические данные. В первую очередь, формируется база эталонных ответов с привязкой к типам заданий (например, выбор одного варианта, множественный выбор, сопоставление). Для вопросов с однозначными ответами (формулы, даты, термины) используется прямой поиск по базе знаний с точностью не менее 95%. В случаях с неоднозначными формулировками (например, «выберите наиболее подходящий вариант») применяется алгоритм ранжирования на основе:
- частотности употребления терминов в учебных материалах (вес 40%);
- соответствия контексту вопроса (вес 35%);
- наличия отрицаний или ограничивающих конструкций (вес 25%).
Для минимизации ошибок при обработке вопросов с отрицаниями («какое утверждение НЕверно») бот инвертирует логику выбора, предварительно выделяя частицу «НЕ» с помощью регулярных выражений. Тесты с динамически генерируемыми вариантами ответов требуют дополнительной валидации: бот сравнивает ответы между собой, исключая дубликаты и логически противоречивые пары (например, «все вышеперечисленное» и «ни один из перечисленных»). При нехватке данных для принятия решения система запрашивает уточнение через API МЭШ или переходит в режим «частичного ответа», выбирая вариант с наивысшим совпадением по ключевым критериям.
Оптимизация логики строится на адаптивном обучении: бот сохраняет результаты прохождения тестов, включая ошибочные ответы, и корректирует веса критериев. Для предметов с высокой вариативностью формулировок (литература, история) применяется метод сравнения с шаблонами из банка заданий МЭШ, где каждый вопрос имеет уникальный идентификатор. В случае расхождения между автоматическим выбором и эталонным ответом система генерирует отчет с указанием причины ошибки (например, «не учтена синонимия терминов») и предлагает администратору добавить исключение в базу правил. Для повышения точности на 12–18% рекомендуется интегрировать модуль проверки грамматической согласованности ответов с вопросом, особенно для заданий на знание языковых норм.
Оптимизация скорости работы бота и минимизация риска блокировки
Скорость выполнения тестов МЭШ зависит от задержек между запросами. Оптимальный интервал – 1,5–2,5 секунды между действиями. Меньшие значения (0,8–1,2 с) увеличивают риск обнаружения антибот-системами, особенно при массовом тестировании. Используйте асинхронные запросы с библиотеками aiohttp или httpx вместо синхронных requests, чтобы сократить время ожидания ответов на 30–40%.
Кэширование данных снижает нагрузку на серверы МЭШ. Сохраняйте токены авторизации, структуру тестов и часто используемые ответы в Redis или SQLite с TTL 10–15 минут. Это уменьшает количество повторных запросов на 60–70% и ускоряет работу бота на 20–25%. Избегайте хранения чувствительных данных (логин/пароль) в кэше – используйте временные сессионные ключи.
- Ротация User-Agent: генерируйте заголовки с помощью библиотек
fake-useragentилиua-parser. Список актуальных версий браузеров обновляйте раз в 3–4 недели. - IP-адреса: используйте прокси-пулы с минимальным пингом (< 150 мс). Для тестирования подходит
LuminatiилиSmartproxyс ротацией каждые 5–7 запросов. - HTTP-заголовки: имитируйте реальные браузеры – добавляйте
Accept-Language: ru-RU,ru;q=0.9иRefererс URL предыдущей страницы.
Анализируйте ответы сервера на предмет CAPTCHA и блокировок. Коды HTTP 429 (Too Many Requests) или 403 (Forbidden) сигнализируют о превышении лимитов. В таких случаях:
- Увеличьте задержку между запросами до 3–5 секунд.
- Смените прокси и очистите cookies.
- Проверьте наличие JavaScript-вызовов в ответах – их отсутствие может указывать на обнаружение бота.
Оптимизируйте алгоритмы парсинга. Для МЭШ используйте CSS-селекторы вместо XPath – они работают на 15–20% быстрее. Пример: div.question-block > p.answer вместо //div[@class='question-block']/p[@class='answer']. Исключите регулярные выражения для простых операций – заменяйте их строковыми методами str.contains() или str.startswith().
Логируйте все действия с временными метками и статусами ответов. Формат лога: [2023-11-15 14:30:45] [INFO] Запрос к /test/12345 – 200 OK (1.24s, IP: 192.168.1.100). Анализируйте логи раз в сутки на предмет аномалий: резкое увеличение времени ответа (> 3 с) или повторяющиеся ошибки 401 (Unauthorized). Настройте алерты при превышении порога в 5% неудачных запросов за час.
Тестируйте бота в «песочнице» перед запуском. Создайте тестовый аккаунт МЭШ и проверяйте работу на 10–15 заданиях с разными типами ответов (выбор, ввод текста, перетаскивание). Измеряйте время выполнения каждого этапа: авторизация (0,8–1,5 с), загрузка теста (1,2–2,0 с), отправка ответа (0,5–1,0 с). Если суммарное время превышает 5 секунд на задание – оптимизируйте код или увеличивайте задержки.