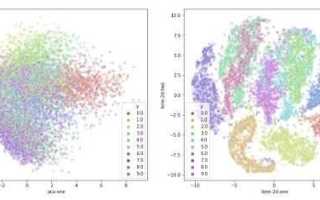
t-SNE (t-distributed Stochastic Neighbor Embedding) – метод снижения размерности, предназначенный для визуализации высокоразмерных данных. Он преобразует многомерные объекты в двумерное или трёхмерное пространство, сохраняя локальные сходства между точками. В Python алгоритм реализован в библиотеке scikit-learn, что позволяет интегрировать его с другими инструментами анализа данных.
Алгоритм t-SNE основан на вероятностном подходе: близкие точки в исходном пространстве получают высокую вероятность взаимного соседства, а затем модель минимизирует расхождение распределений между исходным и низкоразмерным пространством с помощью KL-дивергенции. Для практической работы важно правильно нормализовать данные и выбирать подходящий perplexity и количество итераций для стабильной визуализации.
Применение t-SNE в Python охватывает кластеризацию изображений, текстов и биоинформатические данные. Например, при анализе эмбеддингов слов или векторов признаков изображений алгоритм позволяет выявлять скрытые структуры и аномалии, которые сложно обнаружить стандартными методами. Эффективное использование требует тестирования различных параметров и предварительной обработки данных для устранения шумов и корреляций.
Для визуализации результатов t-SNE рекомендуется использовать matplotlib или seaborn. Разные настройки цвета, формы и прозрачности точек помогают сразу оценить плотности кластеров и их взаимное расположение. Сравнение нескольких запусков с различными параметрами позволяет определить оптимальные условия для конкретного набора данных и задачи.
htmlTSNE в Python: принципы работы и применение

htmlTSNE – расширение стандартного t-SNE для интерактивной визуализации результатов в веб-браузере. В Python его используют для динамического исследования высокоразмерных данных без потери структуры локальных кластеров. Основной пакет для работы – openTSNE с поддержкой экспорта в HTML через plotly или bokeh.
Принципы работы htmlTSNE совпадают с классическим t-SNE, но с дополнительным шагом генерации интерактивного HTML-файла. Процесс включает:
- Нормализацию данных с использованием StandardScaler или MinMaxScaler.
- Определение гиперпараметров: perplexity, learning_rate, n_iter.
- Построение низкоразмерного представления через openTSNE с возможностью многопоточности для ускорения вычислений.
- Экспорт полученных координат в интерактивную визуализацию с помощью plotly или bokeh, включая поддержку масштабирования, выделения кластеров и подсказок при наведении.
Рекомендации по использованию:
- Перед запуском htmlTSNE удалять выбросы и проводить отбор признаков для улучшения качества кластеризации.
- Выбирать perplexity в диапазоне от 5 до 50 в зависимости от размера данных. Мелкие наборы требуют меньшей perplexity, крупные – большей.
- Использовать n_iter не менее 1000 для стабильных визуализаций; для больших наборов данных можно до 5000 итераций.
- Сохранять интерактивные HTML-файлы для анализа и совместного использования без необходимости повторного расчёта.
- Комбинировать htmlTSNE с другими методами снижения размерности, например, PCA, для предварительного сжатия больших наборов данных.
htmlTSNE особенно полезен для:
- Анализа эмбеддингов слов и текстов.
- Визуализации признаков изображений после извлечения CNN.
- Исследования биоинформатических данных, таких как экспрессия генов в клетках.
- Интерактивного сравнения нескольких наборов данных и выявления аномалий.
Что такое t-SNE и где его используют
t-SNE (t-distributed Stochastic Neighbor Embedding) – алгоритм снижения размерности, ориентированный на сохранение локальной структуры данных. Он преобразует многомерные объекты в двумерное или трёхмерное пространство, где расстояния между точками отражают вероятности соседства в исходном пространстве. Основное отличие от PCA – акцент на локальные отношения, а не на глобальную дисперсию.
Алгоритм строит вероятностные распределения сходства между точками в исходном пространстве и минимизирует расхождение между ними и распределениями в низкоразмерном пространстве с помощью KL-дивергенции. Это позволяет выявлять кластеры и скрытые структуры даже при высокой размерности данных.
t-SNE применяют в следующих областях:
- Визуализация эмбеддингов слов и текстовых данных для оценки семантических связей.
- Анализ признаков изображений после работы нейросетей для выявления паттернов и аномалий.
- Биоинформатика: анализ экспрессии генов, кластеризация клеток по типам и состояниям.
- Обнаружение аномалий в данных IoT и финансовых потоках через выявление нетипичных кластеров.
Для практического применения важно предварительно масштабировать данные, тестировать perplexity в диапазоне 5–50 и выбирать количество итераций не менее 1000. В Python t-SNE реализован в scikit-learn, openTSNE и позволяет интегрироваться с matplotlib и plotly для визуализации.
Математические основы алгоритма t-SNE
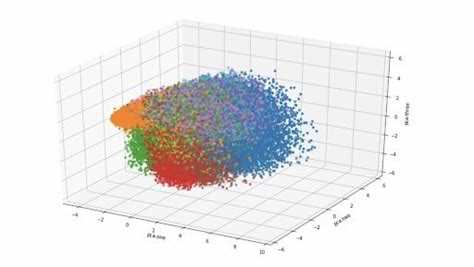
Алгоритм t-SNE строит низкоразмерное представление данных, минимизируя расхождение распределений сходства между точками. В исходном пространстве для каждой точки xi вычисляется условная вероятность соседства pj|i через гауссово распределение:
pj|i = exp(-||xi — xj||² / 2σi²) / Σk≠i exp(-||xi — xk||² / 2σi²)
σi подбирается таким образом, чтобы локальная плотность соседей соответствовала заданной perplexity. Общая вероятность pij симметризуется:
pij = (pj|i + pi|j) / 2N, где N – число точек.
В низкоразмерном пространстве для точек yi используется t-распределение с одной степенью свободы для вычисления вероятности qij:
qij = (1 + ||yi — yj||²)-1 / Σk≠l(1 + ||yk — yl||²)-1
Минимизируется KL-дивергенция между распределениями pij и qij:
C = Σi≠j pij log(pij/qij)
Для оптимизации применяют градиентный спуск с инерцией. В Python библиотека openTSNE использует ускоренные методы, включая Barnes-Hut и FFT-аппроксимации, позволяя работать с сотнями тысяч точек. Рекомендации по параметрам:
- perplexity: 5–50 в зависимости от плотности кластеров;
- learning_rate: 200–1000 для стабильного сходимости;
- n_iter: минимум 1000, лучше 3000–5000 для больших наборов.
Подготовка данных для t-SNE в Python
Для корректной работы t-SNE важна предварительная обработка данных. Алгоритм чувствителен к масштабам признаков и выбросам, поэтому первый шаг – нормализация. Наиболее эффективны StandardScaler для центрирования и стандартизации, или MinMaxScaler для приведения значений к диапазону [0,1].
Удаление выбросов повышает стабильность визуализации. Рекомендуется использовать IsolationForest или метод межквартильного размаха для идентификации аномальных точек. Для больших наборов данных предварительное снижение размерности с помощью PCA до 30–50 признаков ускоряет расчет и сохраняет основные структуры.
Обработка категориальных признаков: t-SNE работает только с числовыми данными. Применяют OneHotEncoder или OrdinalEncoder в зависимости от числа категорий и плотности данных. После кодирования снова рекомендуется масштабирование.
Примеры оптимальной подготовки:
- Для эмбеддингов слов или изображений нормализация и предварительный PCA.
- Для табличных данных с различными единицами измерения – стандартизация всех числовых признаков и кодирование категорий.
- Для временных рядов – агрегация и нормализация оконных признаков перед применением t-SNE.
После подготовки данных можно запускать t-SNE в Python через scikit-learn или openTSNE, учитывая подобранные гиперпараметры perplexity и learning_rate.
Настройка гиперпараметров t-SNE
Основные гиперпараметры t-SNE влияют на качество и стабильность визуализации: perplexity, learning_rate, n_iter и init. Perplexity регулирует число ближайших соседей для расчета вероятностей и обычно выбирается в диапазоне 5–50. Меньшие значения подходят для мелких, плотных кластеров, большие – для разреженных и больших наборов данных.
Learning_rate определяет скорость градиентного спуска. Рекомендуемый диапазон: 200–1000. Слишком низкий learning_rate приводит к застреванию в локальных минимумах, слишком высокий – к разрыву кластеров. Для больших наборов данных можно увеличивать learning_rate пропорционально числу точек.
N_iter задаёт количество итераций оптимизации. Минимальное значение – 1000, для сложных или больших наборов данных лучше 3000–5000. Проверка графика стоимости KL-дивергенции позволяет определить, когда оптимизация стабилизировалась.
Init определяет начальное расположение точек: pca ускоряет сходимость и помогает сохранить глобальные структуры, random увеличивает разнообразие результатов, но требует большего числа итераций.
Для повышения стабильности визуализации рекомендуется запускать t-SNE несколько раз с разными random_state и выбирать среднее представление. Сочетание предварительного PCA и правильно подобранных гиперпараметров снижает шум и ускоряет вычисления.
Writing
Реализация t-SNE с использованием sklearn
Для работы с t-SNE в Python чаще всего используется модуль sklearn.manifold.TSNE. Он позволяет уменьшить размерность данных до 2 или 3 измерений для визуализации и анализа кластерной структуры.
Пример базовой инициализации:
from sklearn.manifold import TSNE
tsne = TSNE(
n_components=2, # количество измерений на выходе
perplexity=30.0, # мера локальной плотности, влияет на сглаживание
learning_rate=200.0, # скорость обучения градиентного спуска
n_iter=1000, # количество итераций оптимизации
random_state=42 # фиксирование случайного состояния
)
Переменные perplexity и learning_rate критичны для качества визуализации. Оптимальные значения подбираются экспериментально, обычно perplexity в диапазоне 5–50, learning_rat
Writing
Визуализация результатов t-SNE в Python
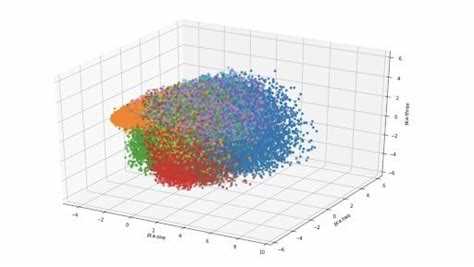
После применения t-SNE для снижения размерности данных важно визуализировать результаты, чтобы выявить структуру и кластеры.
Простейший способ – использовать matplotlib:
import matplotlib.pyplot as plt
plt.scatter(
X_embedded[:, 0],
X_embedded[:, 1],
c=labels, # метки классов для раскраски точек
cmap='viridis',
s=10 # размер точек
)
plt.xlabel('t-SNE 1')
plt.ylabel('t-SNE 2')
plt.title('Визуализация t-SNE')
plt.show()
Рекомендации по визуализации:
- Использовать цветовую палитру для разных классов (
cmap='tab10'илиviridis). - Увеличивать размер точек при малом количестве объектов для лучшей читаемости.
- Добавлять прозрачность
alphaдля плотных областей. - При
Writing
Сравнение t-SNE с другими методами снижения размерности
t-SNE лучше подходит для визуализации высокоразмерных данных с сохранением локальной структуры. В сравнении с другими методами снижения размерности:
PCA (Principal Component Analysis)
- Линейный метод, сохраняет глобальную структуру данных.
- Быстрее t-SNE на больших выборках.
- Не всегда выявляет кластеры, особенно при нелинейных зависимостях.
- Рекомендуется применять перед t-SNE для уменьшения размерности до 50–100 признаков.
UMAP (Uniform Manifold Approximation and Projection)
- Сохраняет как локальную, так и частично глобальную структуру.
- Writing
Практические кейсы применения t-SNE
t-SNE применяется для визуализации высокоразмерных данных и выявления скрытой структуры. Конкретные кейсы:
Анализ изображений
- В компьютерном зрении используется для визуализации признаков, извлечённых сверточными нейронными сетями.
- Позволяет выявлять кластеры схожих изображений и аномалии.
- Рекомендация: перед применением t-SNE выполнить PCA до 50–100 признаков для ускорения обработки.
Обработка текста
- В NLP t-SNE применяется для визуализации векторных представлений слов (word embeddings) и предложений.
- Позволяет выявить тематические кластеры и семантические связи между словами.
- Рекомендация: использовать нормализацию векторов перед применением t-SNE для стабильной визуализации.
Биоинформатика
- Применяется для анализа одноклеточных RNA-seq данных для выявления подтипов клеток.
- Позволяет визуально оценивать различ
Вопрос-ответ:
Что такое t-SNE и для чего его используют в Python?
t-SNE (t-Distributed Stochastic Neighbor Embedding) — алгоритм снижения размерности, который сохраняет локальные связи между объектами данных при отображении их в 2D или 3D пространстве. В Python его используют для визуализации высокоразмерных данных, поиска кластеров и анализа структур в наборе признаков, например, для изображений, текстовых векторов или геномных данных.
Какие параметры t-SNE наиболее влияют на результат и как их выбирать?
Ключевые параметры —
perplexity,learning_rateиn_iter.perplexityрегулирует количество соседей, учитываемых при формировании локальной структуры, обычно в диапазоне 5–50.learning_rateзадает шаг градиентного спуска и влияет на сходимость; оптимальные значения — 10–1000.n_iter— число итераций оптимизации, стандартно 1000–2000. Значения подбирают экспериментально, проверяя стабильность кластеров на визуализации.Как правильно выбрать значение perplexity для t-SNE?
Параметр
perplexityопределяет количество соседей, которые алгоритм учитывает при сохранении локальной структуры. Обычно выбирают значения в диапазоне 5–50. Небольшие значения выделяют мелкие кластеры, большие — более крупные структуры. Рекомендуется проверять несколько вариантов и сравнивать визуализации для стабильной кластерной структуры.Почему результаты t-SNE могут отличаться при повторных запусках?
t-SNE использует стохастический градиентный спуск, поэтому конечные координаты объектов могут меняться при разных запусках. Чтобы получать воспроизводимые результаты, нужно фиксировать
random_state. Для больших выборок рекомендуется также выполнять предварительное уменьшение размерности через PCA, что снижает влияние случайности на финальное отображение.Что такое t-SNE и для чего его используют в анализе данных?
t-SNE (t-Distributed Stochastic Neighbor Embedding) — это алгоритм понижения размерности данных, который помогает визуализировать многомерные наборы данных в 2D или 3D пространстве. Он сохраняет локальные структуры: объекты, которые близки в исходном пространстве, остаются близкими и на визуализации. t-SNE часто применяют для анализа кластеров, выявления паттернов и аномалий в сложных данных, таких как изображения, текстовые эмбеддинги или генетические данные.
Как правильно использовать t-SNE в Python и какие параметры важны для настройки?
В Python t-SNE реализован в библиотеке sklearn через класс TSNE. Для корректной работы важно учитывать несколько параметров: perplexity определяет количество ближайших соседей, влияя на вид кластеров; learning_rate контролирует скорость оптимизации; n_iter задаёт число итераций градиентного спуска. Перед применением t-SNE данные обычно нормализуют или масштабируют. Часто алгоритм используют после предварительного снижения размерности с помощью PCA, чтобы ускорить работу на больших выборках.