Содержание статьи

Разработка собственного языка программирования на C требует точного планирования синтаксиса и структуры команд. На этом этапе важно определить, какие типы данных будут поддерживаться, как будут выглядеть операторы присваивания, условные конструкции и циклы. Рекомендуется описать грамматику с помощью формальных правил, чтобы избежать двусмысленностей при последующей обработке кода.
Следующий шаг – создание лексического анализатора, который разбивает исходный код на токены. Для этого удобно использовать массивы структур, где каждая структура хранит тип токена и его значение. Такой подход упрощает передачу информации на этап синтаксического анализа и позволяет быстро идентифицировать ошибки в коде.
Парсер должен преобразовывать поток токенов в дерево разбора, отражающее логическую структуру программы. Рекомендуется реализовать рекурсивный спуск или таблицу предикатов для обработки различных конструкций. Это обеспечит правильное сопоставление скобок, блоков кода и вызовов функций, что критично для корректной работы интерпретатора или компилятора.
Проектирование системы типов и проверка их соответствия помогают избежать ошибок выполнения. На этом этапе важно определить правила преобразования типов, допустимые операции и ограничения для пользовательских структур данных. Реализация строгой проверки типов в рантайме или компиляции уменьшает вероятность логических ошибок в программах.
Интерпретатор или генератор кода на C должен выполнять команды или преобразовывать их в низкоуровневый код с учётом выделения памяти и управления потоками выполнения. Использование структур данных для хранения контекста выполнения и стеков вызовов позволяет управлять переменными и функциями без утечек памяти и конфликтов имен.
Выбор синтаксиса и структуры команд для нового языка

При создании нового языка программирования критично определить синтаксис и структуру команд, чтобы обеспечить однозначное восприятие кода компилятором и пользователями. Синтаксис формирует правила написания выражений, операторов и блоков кода.
Рекомендуется начинать с:
- Определения ключевых слов и операторов: выбрать набор слов для объявления переменных, условий, циклов и функций.
- Установки правил именования идентификаторов: длина, допустимые символы, регистрозависимость.
- Выбора формата блоков кода: фигурные скобки, отступы или специальные маркеры для начала и конца блоков.
Структура команд должна обеспечивать логическую последовательность выполнения. Для этого важно:
- Определить порядок следования операторов внутри блоков и функций.
- Выделить синтаксис выражений: арифметические, логические и условные операции.
- Проработать правила вызова функций, передачи аргументов и возврата значений.
Особое внимание стоит уделить совместимости с типами данных:
- Выбор примитивных типов: int, float, char и их расширений.
- Поддержка пользовательских структур и массивов.
- Правила преобразования типов и контроля совместимости при операциях.
Рекомендуется составить документ с полными примерами команд и блоков кода. Это позволит тестировать парсер и интерпретатор на ранних этапах разработки и избежать неоднозначностей в обработке синтаксиса.
Разработка лексического анализатора для обработки исходного кода
Рекомендуется реализовать следующие компоненты:
- Таблицы символов для хранения идентификаторов и литералов с указанием типа и позиции в коде.
- Регулярные выражения для распознавания чисел, строк, операторов и ключевых слов.
- Структуры данных, содержащие тип токена, значение и позицию строки и столбца в исходном коде.
Для обработки пробелов и комментариев следует:
- Игнорировать пробельные символы между токенами.
- Реализовать фильтры для однострочных и многострочных комментариев.
Оптимизация работы анализатора включает:
- Использование конечных автоматов для ускорения распознавания токенов.
- Буферизацию входного потока для уменьшения количества обращений к памяти.
- Своевременную генерацию ошибок при некорректных символах с указанием позиции.
Тестирование лексического анализатора проводится на различных примерах исходного кода, включая нестандартные комбинации токенов, чтобы гарантировать корректное разбиение текста и подготовку точных данных для парсера.
Создание парсера для построения структуры программы

Парсер преобразует последовательность токенов, сгенерированных лексическим анализатором, в дерево разбора, отражающее логическую структуру программы. Это необходимо для проверки синтаксиса и подготовки к интерпретации или компиляции.
Рекомендуется использовать следующие подходы:
- Рекурсивный спуск для обработки вложенных конструкций, включая условия, циклы и функции.
- Таблицы предикатов или грамматики LL(1) для определения допустимых последовательностей токенов.
- Структуры узлов дерева, включающие тип конструкции, дочерние элементы и ссылку на позицию в исходном коде.
Парсер должен учитывать:
- Корректное сопоставление скобок и границ блоков кода.
- Обработку вложенных вызовов функций и передачи аргументов.
- Обнаружение синтаксических ошибок с точным указанием строки и столбца.
Для повышения надёжности рекомендуется строить дерево с возможностью обратного обхода и внесения корректировок, что упрощает последующую генерацию кода и интеграцию проверок типов и выражений.
Проектирование системы типов и проверка их соответствия
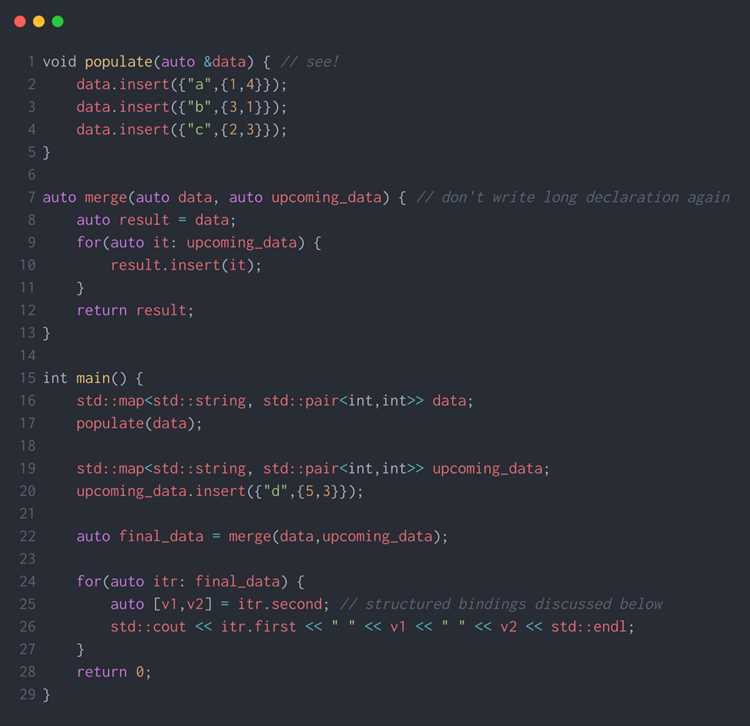
Система типов определяет допустимые операции с данными и взаимодействие различных элементов программы. Для нового языка важно задать набор примитивных типов и правила преобразования между ними.
Рекомендуется включить следующие типы:
| Тип | Описание | Примеры использования |
|---|---|---|
| int | Целые числа | Переменные счетчиков, индексы массивов |
| float | Числа с плавающей точкой | Вычисления с дробными значениями |
| char | Символы | Обработка символов и строк |
| struct | Пользовательские структуры | Объединение различных типов данных в одну сущность |
Для проверки соответствия типов следует реализовать алгоритмы:
- Проверка совместимости при присваивании и арифметических операциях.
- Контроль типов аргументов при вызове функций.
- Автоматическое преобразование совместимых типов с предупреждением о возможной потере данных.
Рекомендуется хранить типы переменных и выражений в таблице символов с указанием области видимости и времени жизни. Это упрощает анализ и предотвращает конфликты при обработке сложных выражений и вложенных функций.
Реализация интерпретатора или генератора кода на C
Интерпретатор выполняет команды исходного кода напрямую, а генератор кода преобразует структуру программы в исполняемый код на C. Выбор подхода зависит от целей языка и объема программ.
Рекомендуется использовать следующие элементы:
- Структуры для хранения контекста выполнения, включая стек вызовов, локальные переменные и указатели на функции.
- Обход дерева разбора в порядке прямого или обратного обхода для генерации инструкций или выполнения операций.
- Модуль управления памятью для выделения и освобождения ресурсов при создании объектов и массивов.
Для интерпретатора важно реализовать обработку выражений и операторов:
- Арифметические и логические операции с учетом типов данных.
- Условные конструкции и циклы с поддержкой вложенности.
- Вызовы функций с передачей аргументов и возвратом значений.
Для генератора кода рекомендуется создавать промежуточные структуры, которые отражают последовательность инструкций на C, и реализовать функцию трансляции для каждой конструкции языка. Это позволяет легко интегрировать оптимизацию и отладку на этапе компиляции.
Обработка ошибок и диагностических сообщений компилятора
Компилятор должен своевременно выявлять синтаксические и семантические ошибки, предоставляя информацию о месте и причине сбоя. Для этого рекомендуется реализовать систему сообщений с указанием строки, столбца и типа ошибки.
Следует классифицировать ошибки на:
- Синтаксические – неправильная структура команд, несоответствие скобок, недопустимые токены.
- Типовые – несовпадение типов при присваивании, аргументах функций или арифметических операциях.
- Семантические – использование неинициализированных переменных, вызов неопределенных функций, дублирование идентификаторов.
Рекомендуется хранить ошибки в динамическом массиве структур, содержащих:
- Тип ошибки
- Сообщение для пользователя
- Позицию в исходном коде
Для удобства отладки полезно реализовать:
- Подсветку строки с ошибкой в исходном коде.
- Предложения по исправлению на основе анализируемых контекстов.
- Регистрацию предупреждений для некритических нарушений, влияющих на поведение программы.
Тестирование системы обработки ошибок проводится на искусственно созданных неправильных примерах кода, что позволяет убедиться в точности диагностики и корректности формирования сообщений для пользователя.
Интеграция стандартной библиотеки функций и модулей

Каждый модуль должен включать:
- Определение функций с указанием типов аргументов и возвращаемого значения.
- Реализацию функций на C с обработкой ошибок и проверкой типов входных данных.
- Документацию для разработчиков, описывающую назначение и правила использования.
Для удобства подключения модулей рекомендуется:
- Создавать таблицу зарегистрированных функций, доступных компилятору и интерпретатору.
- Реализовать динамическую или статическую загрузку модулей в зависимости от размера программы и требований к памяти.
- Обеспечить контроль конфликтов имен при добавлении новых функций и структур.
Тестирование библиотек должно включать проверку всех функций на корректность работы с типами данных, обработку исключительных ситуаций и совместимость с другими модулями, чтобы гарантировать стабильность работы программ, написанных на новом языке.
Тестирование языка на примерах и отладка программ
Тестирование нового языка направлено на проверку корректности работы лексического анализатора, парсера, интерпретатора и стандартной библиотеки. Оно должно включать разнообразные сценарии использования.
Рекомендуется выполнять следующие шаги:
- Создание тестовых программ: короткие скрипты для проверки отдельных конструкций, функции с различными типами данных, вложенные циклы и условия.
- Проверка синтаксиса: тесты на корректное распознавание операторов, блоков кода, функций и выражений.
- Проверка типов: тестирование присваиваний, вызовов функций, арифметических и логических операций с разными типами данных.
Для отладки рекомендуется:
- Использовать пошаговое выполнение кода с возможностью отслеживания значений переменных и состояния стека вызовов.
- Реализовать логирование действий интерпретатора или генератора кода для анализа последовательности выполнения команд.
- Составлять отчеты о найденных ошибках с указанием точной позиции в исходном коде и возможных причин.
Регулярное тестирование на разнообразных примерах позволяет выявить нестандартные случаи использования и ошибки интеграции модулей, обеспечивая стабильность и предсказуемость поведения языка.
Вопрос-ответ:
Какие шаги необходимы для создания собственного языка программирования на C?
Создание языка начинается с проектирования синтаксиса и структуры команд, после чего разрабатывается лексический анализатор для преобразования текста программы в токены. Затем строится парсер, который формирует дерево разбора, определяются типы данных и правила их совместимости. Следующий этап — реализация интерпретатора или генератора кода на C, интеграция стандартной библиотеки функций и модулей, а также организация обработки ошибок. Завершающий этап — тестирование и отладка на различных примерах кода.
Как правильно выбрать синтаксис для нового языка?
При выборе синтаксиса нужно определить ключевые слова, операторы, правила именования идентификаторов и структуру блоков кода. Рекомендуется описать грамматику формально, чтобы избежать двусмысленностей при разборе кода. Также важно учитывать поддержку типов данных, вложенность функций и порядок выполнения команд.
Зачем нужен лексический анализатор и как его реализовать?
Лексический анализатор преобразует исходный текст программы в последовательность токенов для синтаксического анализа. Для реализации используют таблицы символов, регулярные выражения для распознавания ключевых слов, операторов и литералов, а также структуры данных для хранения типа токена и его позиции. Необходимо предусмотреть обработку пробелов, комментариев и некорректных символов с выдачей диагностических сообщений.
Какие методы тестирования и отладки применяются при разработке языка?
Тестирование проводится на коротких и длинных программах с разными комбинациями операторов, функций и типов данных. Проверяют корректность работы лексического анализатора, парсера, интерпретатора и стандартной библиотеки. Для отладки используют пошаговое выполнение кода, логирование действий интерпретатора и отчеты об ошибках с указанием позиции и причины сбоя. Тесты включают как корректные, так и намеренно ошибочные примеры кода.