Содержание статьи

ORM (Object-Relational Mapping) – это технология, которая переводит данные из реляционных баз в объекты языка программирования и обратно. Она позволяет работать с таблицами и строками как с объектами, что сокращает необходимость вручную писать SQL-запросы.
С помощью ORM разработчики могут создавать, изменять и удалять записи через методы классов, а не через прямые запросы. Например, в Python библиотека SQLAlchemy позволяет описывать структуру таблиц через классы и автоматически синхронизировать изменения с базой данных.
ORM поддерживает связи между таблицами: один-к-одному, один-ко-многим и многие-ко-многим. Это упрощает работу с сложными структурами данных и позволяет строить запросы с объединениями и фильтрацией без глубокого знания SQL.
Использование ORM помогает стандартизировать код и снизить риск ошибок при работе с базой. Однако стоит учитывать нагрузку на производительность при больших объемах данных и сложных запросах – иногда прямой SQL может быть быстрее.
Как ORM упрощает работу с базой данных
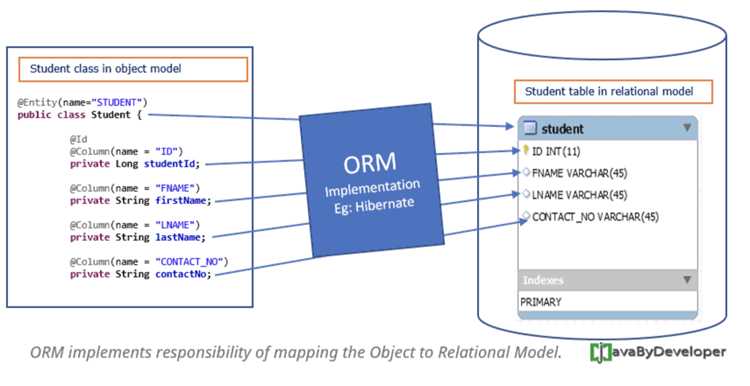
ORM переводит таблицы базы данных в объекты и атрибуты, что позволяет управлять данными через методы классов. Например, вместо написания INSERT INTO users (name, email) VALUES (‘Иван’, ‘ivan@mail.com’) достаточно создать объект User(name=’Иван’, email=’ivan@mail.com’) и вызвать метод save().
С помощью ORM можно строить фильтры и сортировки без написания SQL. В Django ORM запрос User.objects.filter(active=True).order_by(‘last_login’) возвращает активных пользователей, отсортированных по дате последнего входа.
Связи между таблицами становятся методами объекта. Для связи «один-ко-многим» достаточно определить атрибут ForeignKey, после чего можно получать связанные записи через свойства объекта без дополнительных JOIN-запросов.
ORM автоматически обрабатывает транзакции и защиту от SQL-инъекций. Например, при изменении нескольких связанных объектов ORM создаёт атомарные операции и подставляет параметры безопасно, что снижает риск ошибок и уязвимостей.
Примеры популярных библиотек ORM для разных языков
Для Python часто используют SQLAlchemy, которая поддерживает декларативное описание моделей и сложные запросы с объединениями и подзапросами. В Django ORM реализованы готовые методы для фильтрации, агрегации и работы с связями между таблицами.
Для PHP популярны Eloquent в Laravel и Doctrine. Eloquent позволяет описывать модели через классы и использовать цепочку методов для построения запросов, а Doctrine обеспечивает высокий контроль над схемой базы и поддерживает кэширование.
Для Java активно применяются Hibernate и MyBatis. Hibernate автоматически синхронизирует объекты с базой, поддерживает транзакции и кэш второго уровня, а MyBatis сочетает возможности ORM с ручной настройкой SQL для сложных операций.
В C# стандартным инструментом является Entity Framework. Он позволяет создавать модели через Code First или Database First, управлять миграциями и строить LINQ-запросы, которые транслируются в SQL.
Механизм преобразования объектов в таблицы и обратно

ORM использует маппинг, который связывает поля класса с колонками таблицы. Например, в SQLAlchemy атрибут name = Column(String) соответствует колонке name в базе, а значение объекта автоматически сохраняется при вызове метода commit().
При чтении данных ORM создаёт экземпляры классов на основе строк таблицы. Запрос session.query(User).filter(User.id==1).first() вернёт объект User с заполненными атрибутами, что позволяет работать с ним как с обычным объектом Python.
ORM также поддерживает автоматическую конвертацию типов данных: строки, числа и даты из SQL преобразуются в соответствующие типы языка программирования. Это исключает ошибки при обработке данных и упрощает передачу объектов между слоями приложения.
При изменении атрибутов объекта ORM отслеживает изменения и формирует соответствующие SQL-запросы для обновления таблиц. Такой подход позволяет синхронизировать состояние объектов и базы без ручного написания INSERT, UPDATE или DELETE.
Настройка связей между таблицами через ORM
ORM позволяет задавать связи между таблицами через свойства классов. Основные типы связей – один-к-одному, один-ко-многим и многие-ко-многим. Для каждого типа связи ORM создаёт соответствующие внешние ключи и методы для доступа к связанным объектам.
Пример связи «один-ко-многим» в Python с SQLAlchemy:
| Класс | Описание |
|---|---|
| User | Определён с атрибутом posts = relationship(«Post», back_populates=»author») |
| Post | Имеет author_id = Column(Integer, ForeignKey(‘user.id’)) и author = relationship(«User», back_populates=»posts») |
Для связи «многие-ко-многим» ORM создаёт промежуточную таблицу. Например, в Django ORM достаточно использовать ManyToManyField, после чего доступ к связанным объектам осуществляется через методы add(), remove() и all().
Настройка связей через ORM упрощает построение запросов с объединениями и обеспечивает корректное удаление и обновление связанных данных без ручного управления внешними ключами.
Использование запросов ORM вместо SQL
ORM позволяет строить запросы к базе через методы и атрибуты объектов, что уменьшает необходимость прямого написания SQL. В Django ORM запрос User.objects.filter(is_active=True) возвращает только активных пользователей, автоматически формируя соответствующий SQL SELECT.
Для сортировки и агрегации ORM предоставляет встроенные методы. Пример: User.objects.filter(age__gte=18).order_by(‘-last_login’) формирует SQL с WHERE и ORDER BY без ручного вмешательства.
При использовании связей ORM автоматически создаёт JOIN-запросы. Например, Post.objects.select_related(‘author’).filter(author__is_staff=True) возвращает посты, авторы которых имеют права staff, формируя SQL с INNER JOIN.
Методы ORM также обеспечивают безопасную подстановку параметров, снижая риск SQL-инъекций. В SQLAlchemy можно писать session.query(User).filter(User.email==email_input), где ORM корректно экранирует значение email_input.
Проблемы производительности при работе с ORM
Некоторые ORM по умолчанию загружают все поля объекта, включая большие текстовые или бинарные данные, даже если они не нужны. Это увеличивает время выполнения и расход памяти.
Сложные запросы с множественными объединениями и фильтрациями через ORM могут генерировать SQL с подзапросами, которые выполняются медленнее оптимизированных ручных запросов. В таких случаях рекомендуется использовать методы select_related или prefetch_related для уменьшения числа запросов.
Кэширование результатов ORM и ограничение выборки через limit и offset помогает снизить нагрузку, но требует контроля за актуальностью данных, чтобы избежать получения устаревших объектов.
Сценарии, когда ORM лучше не применять
ORM подходит для большинства стандартных операций с базой, но есть случаи, когда прямой SQL или другие подходы предпочтительнее:
- Работа с очень большими объёмами данных. Массовые вставки или обновления миллионов строк через ORM могут быть медленнее, чем через BULK INSERT или оптимизированные SQL-запросы.
- Сложные аналитические запросы с множественными объединениями и агрегациями. ORM может генерировать неоптимальный SQL, который тормозит выполнение.
- Высокочастотные транзакции в реальном времени, где каждая миллисекунда важна. Ручной SQL позволяет тонко оптимизировать индексы и план выполнения.
- Использование специфических возможностей СУБД, которых нет в абстракции ORM. Например, полнотекстовый поиск в PostgreSQL или специфические функции MySQL.
- Сценарии миграции и синхронизации схем больших баз с минимальными изменениями. ORM может создавать лишние ALTER-запросы, увеличивая время обновления.
Вопрос-ответ:
Что такое ORM и для чего он нужен в программировании?
ORM (Object-Relational Mapping) — это технология, которая преобразует данные из реляционной базы в объекты языка программирования. Она позволяет работать с таблицами и строками как с обычными объектами, упрощая создание, изменение и удаление записей без прямого написания SQL.
Какие типы связей между таблицами поддерживаются ORM?
Основные типы связей, которые поддерживают ORM, включают: один-к-одному, один-ко-многим и многие-ко-многим. Эти связи задаются через свойства класса и автоматически создают внешние ключи и методы доступа к связанным объектам, упрощая объединение данных и работу с зависимостями.
Как ORM помогает безопасно работать с базой данных?
ORM автоматически экранирует значения, подставляемые в запросы, что снижает риск SQL-инъекций. Кроме того, большинство библиотек ORM поддерживают управление транзакциями, обеспечивая атомарность операций и корректное сохранение изменений.
Когда использование ORM может негативно сказаться на производительности?
Производительность может снижаться при работе с большими объёмами данных, частыми обращениями к связанным объектам (N+1 запросы) и сложными объединениями. В таких случаях рекомендуется применять методы кэширования, выборки только необходимых полей и оптимизированные SQL-запросы напрямую.
Какие библиотеки ORM популярны для разных языков программирования?
Для Python популярны SQLAlchemy и Django ORM, для PHP — Eloquent и Doctrine, для Java — Hibernate и MyBatis, для C# — Entity Framework. Каждая библиотека предоставляет инструменты для описания моделей, управления связями и построения запросов без ручного написания SQL.
Как ORM упрощает работу с базой данных для разработчика?
ORM позволяет работать с таблицами как с объектами, поэтому вместо ручного написания SQL можно создавать, изменять и удалять записи через методы классов. Это сокращает количество ошибок, ускоряет разработку и упрощает чтение кода. Например, в Python SQLAlchemy создание нового пользователя выполняется через объект User(name=’Иван’, email=’ivan@mail.com’) и метод save(), без прямого SQL-запроса.
Какие ограничения или недостатки могут возникнуть при использовании ORM?
Основные ограничения связаны с производительностью и сложными запросами. При работе с большим количеством записей или сложными объединениями ORM может генерировать большое количество SQL-запросов (N+1 проблема), что замедляет выполнение. В таких случаях лучше использовать прямой SQL, оптимизировать выборку через select_related и prefetch_related или комбинировать ORM с ручными запросами для тяжёлых операций.