Содержание статьи

Работа с большими наборами данных в pandas часто требует разделения исходного датафрейма на несколько частей для удобства обработки. Например, датафрейм с 1 миллионом строк может быть разбит на 10 частей по 100 тысяч строк каждая, чтобы ускорить выполнение агрегаций или параллельную обработку.
Разделение по условиям позволяет выделять подмножества данных на основе значений конкретного столбца. Например, можно создать отдельные датафреймы для каждого региона или категории товара, что упрощает анализ и визуализацию.
Функции pandas и numpy предоставляют несколько способов дробления данных. Метод `iloc` подходит для точного деления по индексам, `groupby` – для разделения по уникальным значениям столбцов, а `numpy.array_split` позволяет равномерно распределять строки при дроблении больших таблиц.
Разделение датафрейма на части также полезно при сохранении данных в разные файлы. Это упрощает работу с CSV, Excel или Parquet, особенно когда размер исходного файла превышает возможности памяти. Рекомендуется заранее оценивать размер частей и выбирать подходящий метод разделения в зависимости от задачи.
Как разделить датафрейм на равные части по количеству строк
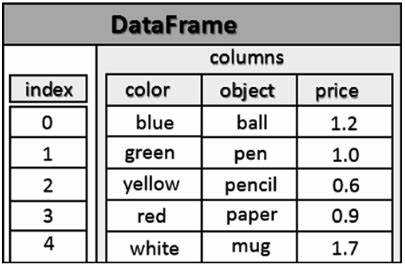
Для разбиения датафрейма на равные части по количеству строк используют метод `numpy.array_split`. Если датафрейм содержит 1 миллион строк, а необходимо получить 5 частей, `numpy.array_split(df, 5)` создаст список из пяти подтаблиц по примерно 200 тысяч строк каждая.
При работе с небольшими остатками строк последняя часть может содержать меньше строк, чем остальные. Для строгого равенства стоит использовать `iloc` с вычисленным диапазоном индексов. Например, длину части можно вычислить как `part_size = len(df) // n_parts` и создавать срезы `df.iloc[i*part_size:(i+1)*part_size]` для первых n-1 частей, а последнюю – `df.iloc[(n_parts-1)*part_size:]`.
Важно учитывать, что при разбиении больших датафреймов стоит избегать копирования всего объекта в памяти. В таких случаях лучше использовать генераторы или обработку по частям, чтобы минимизировать нагрузку на память и ускорить обработку.
Рекомендуется проверять целостность данных после разбиения: сумма строк всех частей должна совпадать с количеством строк исходного датафрейма. Это исключает потерю или дублирование строк при построении подтаблиц.
Использование условий для фильтрации и создания подтаблиц
Фильтрация датафрейма по условиям позволяет формировать подтаблицы с конкретными характеристиками. Например, `df[df[‘Возраст’] > 30]` создаёт подтаблицу с пользователями старше 30 лет, а `df[df[‘Регион’] == ‘Москва’]` выделяет все строки, относящиеся к Москве.
Можно комбинировать несколько условий с помощью логических операторов: `&` для «и», `|` для «или». Пример: `df[(df[‘Возраст’] > 30) & (df[‘Регион’] == ‘Москва’)]` создаёт подтаблицу для пользователей старше 30 лет, проживающих в Москве.
Для фильтрации по списку значений применяется метод `isin`: `df[df[‘Категория’].isin([‘A’, ‘B’, ‘C’])]` формирует подтаблицу с категориями A, B и C. Это удобно для работы с большим числом значений и исключает необходимость многократного сравнения.
При создании подтаблиц рекомендуется использовать `.copy()`, чтобы изменения в новой таблице не влияли на исходный датафрейм. Например, `subset = df[df[‘Возраст’] > 30].copy()` гарантирует независимость подтаблицы при дальнейших преобразованиях.
Разделение датафрейма по уникальным значениям столбца
Разделение по уникальным значениям столбца позволяет формировать отдельные подтаблицы для каждого уникального элемента. Например, в столбце `Регион` можно выделить отдельные датафреймы для каждой области или города.
Алгоритм действий обычно включает следующие шаги:
- Получение уникальных значений столбца: unique_values = df[‘Регион’].unique().
- Итерация по значениям и формирование подтаблиц:
sub_dfs = {val: df[df[‘Регион’] == val].copy() for val in unique_values}. - При необходимости сохранение каждой подтаблицы в отдельный файл для дальнейшего анализа или передачи.
Метод `groupby` позволяет одновременно работать с агрегированными данными для каждой группы и хранить отдельные подтаблицы:
- Создание объекта группировки: grouped = df.groupby(‘Регион’).
- Доступ к отдельной группе: moscow_df = grouped.get_group(‘Москва’).
- Перебор всех групп для автоматического разделения и сохранения:
for name, group in grouped: group.to_csv(f'{name}.csv’, index=False).
Разделение по уникальным значениям особенно полезно для сегментированного анализа, построения отдельных отчётов и подготовки данных для моделей машинного обучения, где группы обрабатываются независимо.
Функция `numpy.array_split` для дробления больших датафреймов
Функция `numpy.array_split` позволяет разбивать датафреймы на заданное число частей, сохраняя порядок строк. Например, `parts = np.array_split(df, 4)` создаёт список из четырёх подтаблиц примерно одинакового размера, даже если общее количество строк не делится нацело.
При работе с большими датафреймами этот метод снижает нагрузку на память, так как возвращает ссылки на части исходного массива, а не полное копирование всех данных. Это ускоряет последующую обработку и агрегацию.
Рекомендуется использовать `array_split` в сочетании с генераторами или списковыми включениями для автоматического создания подтаблиц и их сохранения. Например:
- Разбить датафрейм на части: parts = np.array_split(df, 10).
- Перебрать части и сохранить: for i, part in enumerate(parts): part.to_csv(f’part_{i}.csv’, index=False).
- Проверить количество строк в каждой части с помощью len(part) для контроля равномерности распределения.
Этот подход удобен при параллельной обработке больших наборов данных, позволяя одновременно запускать вычисления по нескольким частям датафрейма без блокировки памяти.
Создание подтаблиц с помощью случайной выборки строк
Случайная выборка строк позволяет формировать подтаблицы для тестирования моделей, проведения анализа или проверки алгоритмов без работы с полным датафреймом. В pandas применяется метод sample. Например, df_sample = df.sample(n=5000, random_state=42) создаёт подтаблицу из 5000 случайных строк с фиксированным генератором случайных чисел для воспроизводимости.
Для выборки определённой доли строк используют параметр frac: df_sample = df.sample(frac=0.1, random_state=42) создаст подтаблицу из 10% строк исходного датафрейма.
Случайная выборка особенно полезна при создании обучающих и тестовых подтаблиц для машинного обучения. Пример структуры подтаблицы с выборкой можно представить так:
| ID | Имя | Возраст | Регион | Категория |
|---|---|---|---|---|
| 1023 | Алексей | 29 | Москва | A |
| 1145 | Мария | 35 | Санкт-Петербург | B |
| 1198 | Иван | 42 | Новосибирск | C |
При работе с большими наборами данных рекомендуется сохранять случайные подтаблицы в отдельные файлы, чтобы повторно использовать их без необходимости повторной выборки, например, с помощью df_sample.to_csv(‘sample.csv’, index=False).
Объединение и сохранение разделённых частей в отдельные файлы
После разделения датафрейма на части часто возникает необходимость сохранить их в отдельные файлы для дальнейшей обработки или передачи. В pandas используется метод to_csv или to_parquet. Например, part.to_csv(‘part_1.csv’, index=False) сохраняет подтаблицу без индексов.
Если необходимо объединить несколько частей обратно в один датафрейм, применяется pd.concat: df_full = pd.concat([part1, part2, part3], ignore_index=True). Параметр ignore_index=True гарантирует корректную переиндексацию строк после объединения.
Для автоматизации сохранения большого числа частей удобно использовать цикл:
- Создать список частей: parts = np.array_split(df, 5).
- Сохранить каждую часть:
for i, part in enumerate(parts): part.to_csv(f’part_{i+1}.csv’, index=False).
При работе с файлами формата Parquet рекомендуется использовать параметр engine=’pyarrow’ для поддержки больших таблиц. Такой подход облегчает совместную работу с командами и ускоряет обработку данных в аналитических системах.
Вопрос-ответ:
Как разделить датафрейм pandas на несколько равных частей по строкам?
Для разбиения датафрейма на равные части используют функцию numpy.array_split. Если нужно разделить 1 миллион строк на 5 частей, выполняют parts = np.array_split(df, 5). Каждая часть будет содержать примерно 200 тысяч строк. Для строгого деления без остатка применяют iloc с вычисленным размером части и срезами.
Можно ли создавать подтаблицы по конкретным условиям столбцов?
Да, pandas позволяет фильтровать данные по условиям. Например, df[df[‘Возраст’] > 30] создаёт подтаблицу пользователей старше 30 лет. Для комбинации условий используют логические операторы: & для «и», | для «или». Пример: df[(df[‘Возраст’] > 30) & (df[‘Регион’] == ‘Москва’)].
Как разделить датафрейм по уникальным значениям столбца и сохранить подтаблицы?
Сначала получают уникальные значения: unique_values = df[‘Регион’].unique(). Затем формируют словарь подтаблиц: sub_dfs = {val: df[df[‘Регион’] == val].copy() for val in unique_values}. Каждую подтаблицу можно сохранить отдельно: sub_dfs[‘Москва’].to_csv(‘moscow.csv’, index=False). Метод groupby позволяет автоматизировать разделение и сохранение для всех групп.
Для чего использовать случайную выборку строк при разделении датафрейма?
Случайная выборка применяется для создания тестовых подтаблиц или уменьшенных версий данных для анализа. Метод df.sample(n=5000, random_state=42) формирует подтаблицу из 5000 случайных строк с фиксированным генератором случайных чисел. Параметр frac позволяет выбрать определённую долю строк, например 10% всего датафрейма.
Как объединять части датафрейма и сохранять их в отдельные файлы?
Для объединения используют pd.concat([part1, part2], ignore_index=True), чтобы восстановить исходный порядок и переиндексировать строки. Для сохранения каждой части применяют метод to_csv или to_parquet. При большом числе частей удобно использовать цикл: for i, part in enumerate(parts): part.to_csv(f’part_{i+1}.csv’, index=False). Такой подход упрощает обработку и передачу данных.