Содержание статьи

Pandas предоставляет удобные инструменты для работы с табличными данными в Python, включая чтение файлов CSV, Excel и баз данных SQL. В Jupyter Notebook каждая ячейка позволяет выполнять код пошагово, что упрощает тестирование и анализ данных.
Создание DataFrame в pandas начинается с импорта библиотеки и загрузки данных. Для CSV-файлов используется pd.read_csv(‘имя_файла.csv’), для Excel – pd.read_excel(‘имя_файла.xlsx’). После загрузки можно просматривать первые строки с помощью head() и получать сводную информацию через info() и describe().
Фильтрация данных выполняется через условия на столбцы: df[df[‘столбец’] > значение]. Для объединения таблиц применяются методы merge() и concat(). Агрегирование позволяет быстро считать сумму, среднее, минимум или максимум с помощью groupby().
Сохранение обработанных данных осуществляется в привычные форматы: df.to_csv(‘новый_файл.csv’, index=False) или df.to_excel(‘новый_файл.xlsx’, index=False). Эти шаги помогают фиксировать промежуточные результаты и делиться ими с коллегами без потери структуры данных.
Установка и импорт pandas в Jupyter Notebook
Для начала работы с pandas в Jupyter Notebook требуется установка библиотеки. В командной строке или в ячейке Jupyter выполните !pip install pandas. Если используется Anaconda, библиотека уже установлена, достаточно проверить версию через conda list pandas.
После установки pandas импортируется стандартным способом: import pandas as pd. Это позволяет использовать сокращение pd для вызова всех функций библиотеки. Рекомендуется сразу проверять версию: pd.__version__, чтобы убедиться, что установлена актуальная сборка, совместимая с вашим проектом.
Если библиотека не устанавливается из-за прав доступа, используйте !pip install —user pandas. На Linux и Mac возможна установка через менеджер пакетов conda: conda install pandas, что гарантирует совместимость с другими библиотеками Anaconda.
Создание и просмотр DataFrame из разных источников
DataFrame в pandas можно создавать из словарей, списков или NumPy массивов. Например, df = pd.DataFrame({‘Имя’: [‘Анна’, ‘Иван’], ‘Возраст’: [25, 30]}) формирует таблицу с указанными столбцами. Для больших наборов данных предпочтительно использовать CSV или Excel файлы: pd.read_csv(‘данные.csv’) и pd.read_excel(‘данные.xlsx’, sheet_name=’Лист1′).
При загрузке данных из SQL базы применяется pd.read_sql_query(‘SELECT * FROM таблица’, соединение), где соединение создается через SQLAlchemy или sqlite3. Для JSON формата подходит pd.read_json(‘данные.json’), а для парсинга веб-данных используется pd.read_html(‘ссылка_на_таблицу’).
Просмотр первых строк осуществляется с помощью df.head(10), а последних – df.tail(10). Для быстрой оценки структуры таблицы используется df.info(), а для анализа числовых данных – df.describe(). Эти методы помогают понять типы столбцов, наличие пропусков и диапазон значений.
Фильтрация и выборка данных по условиям
Фильтрация данных в pandas выполняется через булевы выражения на столбцах. Например, df[df[‘Возраст’] > 30] выбирает строки, где значение столбца ‘Возраст’ больше 30. Для нескольких условий используется оператор & для «И» и | для «ИЛИ»: df[(df[‘Возраст’] > 30) & (df[‘Город’] == ‘Москва’)].
Выбор конкретных столбцов после фильтрации выполняется через список: df.loc[df[‘Возраст’] > 30, [‘Имя’, ‘Город’]]. Метод query() позволяет писать условия в виде строки: df.query(«Возраст > 30 and Город == ‘Москва'»), что повышает читаемость при сложных фильтрах.
Для поиска уникальных значений используется df[‘Статус’].unique(), а подсчет количества элементов – df[‘Статус’].value_counts(). Это помогает быстро оценивать распределение категориальных данных.
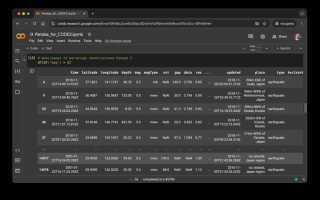
Пример визуального представления выбранных данных в таблице:
| Имя | Возраст | Город |
|---|---|---|
| Иван | 35 | Москва |
| Анна | 42 | Москва |
| Олег | 38 | Москва |
Для работы с пропущенными значениями применяется df[df[‘Зарплата’].notnull()], а для фильтрации по строковому совпадению – df[df[‘Должность’].str.contains(‘инженер’)]. Эти методы позволяют формировать точные выборки для последующего анализа.
Группировка данных и вычисление агрегатов
Метод groupby() позволяет объединять строки по значению одного или нескольких столбцов. Например, df.groupby(‘Отдел’)[‘Зарплата’].mean() вычисляет среднюю зарплату по каждому отделу. Для нескольких агрегатов используется agg(): df.groupby(‘Отдел’)[‘Зарплата’].agg([‘mean’,’max’,’sum’]).
Группировка по нескольким столбцам выполняется так: df.groupby([‘Отдел’,’Город’])[‘Зарплата’].sum(), что дает суммарную зарплату для каждой комбинации отдела и города. Для работы с числовыми данными полезен describe() после группировки: df.groupby(‘Отдел’)[‘Возраст’].describe(), позволяя получить минимум, максимум, среднее и квартильные значения.
Для подсчета количества элементов применяется size() или count(). Разница в том, что count() учитывает только непустые значения, а size() возвращает общее количество строк в группе. Это важно при работе с пропущенными данными.
Применение агрегатов к нескольким столбцам одновременно: df.groupby(‘Отдел’).agg({‘Зарплата’:’mean’,’Возраст’:’max’}). Такой подход упрощает получение разных статистик в одной таблице и снижает необходимость создавать отдельные вычисления для каждого столбца.
Объединение и соединение нескольких таблиц
Для объединения таблиц по строкам используется pd.concat(). Например, pd.concat([df1, df2], ignore_index=True) соединяет две таблицы с одинаковыми столбцами и сбрасывает индексы. Можно объединять и по столбцам: pd.concat([df1, df2], axis=1), что добавляет новые столбцы к существующему DataFrame.
Соединение таблиц по ключевым столбцам выполняется через merge(). Пример: pd.merge(df1, df2, on=’ID’, how=’inner’) возвращает строки, где значения столбца ‘ID’ совпадают в обеих таблицах. Параметр how принимает значения: ‘inner’, ‘left’, ‘right’, ‘outer’, влияя на тип объединения и включение непересекающихся данных.
Для соединений с разными именами ключевых столбцов используется left_on и right_on: pd.merge(df1, df2, left_on=’ID1′, right_on=’ID2′, how=’left’). Это позволяет объединять таблицы с несоответствующими названиями колонок без изменения исходных данных.
При работе с большими наборами данных полезно проверять дубликаты после объединения: df.duplicated().sum(). Для сохранения результата применяется df.to_csv(‘объединенный_файл.csv’, index=False) или df.to_excel(‘объединенный_файл.xlsx’, index=False), что фиксирует структуру и значения объединенной таблицы.
Сохранение изменений и экспорт данных в файлы
После обработки данных в pandas результаты можно сохранить для дальнейшего использования или передачи коллегам. Основные форматы – CSV, Excel и JSON. Выбор формата зависит от структуры данных и требований к совместимости.
Примеры экспорта:
- CSV: df.to_csv(‘файл.csv’, index=False, sep=’;’) – сохраняет таблицу без индекса и с указанным разделителем.
- Excel: df.to_excel(‘файл.xlsx’, sheet_name=’Данные’, index=False) – позволяет задавать имя листа и исключить индекс.
- JSON: df.to_json(‘файл.json’, orient=’records’, force_ascii=False) – сохраняет данные в виде списка словарей, сохраняет кириллицу без кодирования.
Для последовательного сохранения промежуточных результатов удобно использовать нумерацию файлов: df.to_csv(f’шаг_{i}.csv’, index=False), где i – номер шага анализа. Это помогает вернуться к любому этапу без повторного вычисления.
Если требуется сохранять только часть таблицы:
- Выбранные столбцы: df[[‘Имя’,’Возраст’]].to_csv(‘выборка.csv’, index=False).
- Фильтрованные строки: df[df[‘Возраст’] > 30].to_excel(‘старше_30.xlsx’, index=False).
При работе с большими файлами можно использовать параметр chunksize для поэтапной записи, что уменьшает нагрузку на память: df.to_csv(‘большой_файл.csv’, chunksize=10000). Это ускоряет сохранение и предотвращает зависания при работе с объемными данными.
Вопрос-ответ:
Как загрузить CSV-файл в Jupyter с помощью pandas?
Для загрузки CSV-файла используется функция pd.read_csv(‘имя_файла.csv’). Она считывает данные в объект DataFrame, где строки и столбцы соответствуют исходной таблице. Если разделитель отличается от запятой, укажите параметр sep, например: pd.read_csv(‘файл.csv’, sep=’;’). После загрузки удобно просмотреть первые строки с помощью df.head() и оценить типы столбцов через df.info().
Как отфильтровать данные по нескольким условиям?
Фильтрация выполняется через булевы выражения. Для нескольких условий используйте операторы & для «И» и | для «ИЛИ». Например, df[(df[‘Возраст’] > 30) & (df[‘Город’] == ‘Москва’)] вернет строки, где возраст больше 30 и город Москва. Для текстовых столбцов можно применять метод str.contains: df[df[‘Должность’].str.contains(‘инженер’)], чтобы выбрать все позиции с этим словом.
Какие способы существуют для объединения двух DataFrame?
Для объединения таблиц по строкам используется pd.concat([df1, df2], ignore_index=True). Если требуется объединить по ключевым столбцам, применяют pd.merge(df1, df2, on=’ID’, how=’inner’). Параметр how определяет тип соединения: ‘inner’ — пересечение, ‘left’ — все строки левого DataFrame, ‘right’ — правого, ‘outer’ — объединение всех строк. Для объединения с разными именами ключевых столбцов используют left_on и right_on.
Как вычислить среднее, максимум и количество элементов по группам?
Для группировки применяется groupby(). Например, df.groupby(‘Отдел’)[‘Зарплата’].agg([‘mean’,’max’,’count’]) вернет среднюю зарплату, максимальную и количество сотрудников в каждом отделе. Для нескольких столбцов можно передать словарь: df.groupby(‘Отдел’).agg({‘Зарплата’:’mean’,’Возраст’:’max’}), что создаст агрегированные показатели по каждому столбцу одновременно.
Как сохранить изменения в Excel или CSV после обработки данных?
Для сохранения данных используется метод to_csv или to_excel. Например, df.to_csv(‘результат.csv’, index=False, sep=’;’) сохраняет таблицу без индекса и с указанным разделителем. В Excel: df.to_excel(‘результат.xlsx’, sheet_name=’Данные’, index=False). Если нужно сохранить только выбранные столбцы или фильтрованные строки, можно использовать срезы: df[[‘Имя’,’Возраст’]].to_csv(‘выборка.csv’, index=False) или df[df[‘Возраст’]>30].to_excel(‘старше_30.xlsx’, index=False).