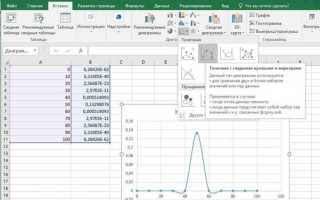
Анализ распределения данных позволяет выявить закономерности и аномалии в наборах данных. В pandas для этого используются методы DataFrame.plot.hist() и Series.plot.kde(), которые позволяют строить гистограммы и графики плотности. Корректная настройка параметров, таких как количество корзин (bins) и диапазон значений, критична для точного отображения структуры данных.
Перед построением распределения важно очистить данные от пропусков и некорректных значений, так как они могут исказить результат. Использование методов dropna() или fillna() позволяет управлять отсутствующими данными. Кроме того, приведение типов столбцов к числовым через astype() облегчает вычисления и визуализацию.
Гистограмма показывает частоту появления значений, а график плотности (KDE) визуализирует непрерывное распределение, что особенно полезно для выявления скрытых закономерностей. Для сравнения нескольких распределений можно строить наложенные графики или использовать параметр alpha для прозрачности, чтобы легко оценить различия между наборами данных.
Анализ распределения данных позволяет определить выбросы, тренды и асимметрию, что важно для последующих вычислительных операций и моделирования. Правильный выбор параметров визуализации и предварительная обработка данных обеспечивают точное представление структуры информации и упрощают интерпретацию результатов.
Загрузка и подготовка данных для анализа распределения
Для анализа распределения данных необходимо корректно загрузить набор и убедиться в его готовности к обработке. В pandas это выполняется через функции read_csv(), read_excel() и read_json(). Рекомендуется сразу задавать ключевые параметры:
- dtype – принудительное определение типов столбцов для числовых и категориальных данных;
- usecols – выбор только нужных столбцов для ускорения анализа;
- parse_dates – автоматическое преобразование колонок с датами для дальнейшего агрегирования.
После загрузки важно выявить и обработать пропуски и некорректные значения:
- Подсчет пропусков: df.isna().sum();
- Удаление строк с пропущенными значениями: df.dropna();
- Заполнение пропусков средним, медианой или конкретным значением через df.fillna();
- Проверка дубликатов: df.duplicated().sum() и удаление через drop_duplicates().
Приведение типов данных к числовым или категориальным через astype() позволяет корректно строить гистограммы и графики плотности. Для подготовки распределения рекомендуется:
- Фильтровать экстремальные значения, выходящие за допустимый диапазон;
- Оценить диапазон и разброс данных через df.describe() для выбора подходящего количества корзин (bins) при построении гистограммы;
- Проверить единообразие единиц измерения и привести их к общему стандарту при необходимости.
Такая подготовка данных обеспечивает точность построения распределений и минимизирует искажения при визуализации и последующем анализе.
Построение гистограммы с помощью pandas
Гистограмма в pandas строится с помощью метода DataFrame.plot.hist() или Series.plot.hist(). Основные параметры для настройки графика:
- bins – количество корзин; рекомендуется выбирать на основе дисперсии данных или использовать правило Стерджеса для автоматического расчета;
- range – диапазон отображаемых значений, что помогает исключить выбросы и сосредоточиться на основной массе данных;
- density – нормализация частот, если нужно сравнивать распределения с разным количеством наблюдений;
- color и alpha – настройка цвета и прозрачности для улучшения визуального восприятия.
Перед построением гистограммы рекомендуется убедиться, что данные приведены к числовому типу и отсутствуют пропуски. Для этого используют astype(float) и dropna(). Если анализируется несколько столбцов, можно строить наложенные гистограммы, задавая параметр alpha для каждого столбца.
Для точного отображения распределения следует выбирать подходящее количество корзин: слишком мало скроет детали, слишком много создаст «шум». Также полезно использовать log=True для оси Y при сильной асимметрии данных.
Гистограмма позволяет быстро выявить пики, симметрию и наличие выбросов, что является основой для последующего анализа и визуализации плотности распределения.
Настройка интервалов и количества корзин (bins) в гистограмме
Параметр bins определяет, на сколько интервалов делится диапазон данных при построении гистограммы. Правильный выбор количества корзин позволяет выявить структуру распределения без излишнего шума. В pandas можно задать bins как конкретное число или список границ интервалов.
Для автоматического расчета количества корзин применяют правила:
- Правило Стерджеса: bins = 1 + log2(N), где N – количество наблюдений;
- Правило квадратного корня: bins ≈ √N, удобно для небольших наборов данных;
- Метод Фридмана-Дьяконова: bins = 2 * IQR * N^(-1/3), подходит при наличии выбросов, где IQR – межквартильный размах.
Параметр range позволяет ограничить анализируемый диапазон значений, исключая экстремальные выбросы, что делает гистограмму более информативной. Для гистограмм с высокой асимметрией данных рекомендуется использовать логарифмическую шкалу оси Y через log=True.
Если требуется сравнение нескольких распределений, важно задать одинаковые границы корзин через bins и range, чтобы визуальная интерпретация была корректной. Применение density=True нормализует частоты и позволяет оценивать вероятностное распределение, а не абсолютные значения.
Визуализация плотности распределения через метод plot.kde()

Метод plot.kde() строит график оценки плотности вероятности (KDE) для числовых данных. Он позволяет увидеть непрерывное распределение без жесткого деления на корзины, как в гистограмме. Основные параметры для настройки:
| Параметр | Описание |
|---|---|
| bw_method | Ширина сглаживания. Значение ‘scott’ или ‘silverman’ автоматически выбирает оптимальное сглаживание. Меньшее значение увеличивает детализацию пиков, большее сглаживает шум. |
| ind | Массив точек, на которых вычисляется плотность. Можно увеличить число точек для более плавной линии графика. |
| ax | Ось matplotlib для наложения нескольких KDE графиков в одной диаграмме. |
| fill | Если True, область под кривой будет залита цветом, облегчая визуальное восприятие плотности. |
Перед построением графика рекомендуется удалить пропуски с помощью dropna() и привести столбцы к числовому типу через astype(float). Для сравнения нескольких распределений используют одинаковый диапазон значений и параметр ax для наложения кривых.
KDE помогает выявить скрытые пики и асимметрию, которые не всегда видны на гистограмме. С помощью bw_method можно контролировать уровень детализации и адаптировать визуализацию к размеру выборки и размаху данных.
Сравнение нескольких распределений в одной диаграмме

Для одновременного анализа нескольких наборов данных в pandas используют наложенные гистограммы или KDE-графики. В гистограммах задают одинаковые параметры bins и range, чтобы сравнение было корректным. Параметр alpha позволяет регулировать прозрачность, чтобы видеть перекрытия между распределениями.
Пример построения наложенной гистограммы:
- df[‘столбец1’].plot.hist(bins=20, alpha=0.5) – первый набор данных;
- df[‘столбец2’].plot.hist(bins=20, alpha=0.5) – второй набор данных;
- Использование legend() для подписей распределений.
Для KDE-графиков применяют plot.kde() с общим объектом оси ax:
- Все кривые строятся на одинаковом диапазоне оси X для корректного сравнения;
- Параметр bw_method выбирается одинаковый для всех распределений, чтобы визуализация была сопоставимой;
- При необходимости добавляется fill=True для наглядного отображения перекрытий.
Сравнение нескольких распределений позволяет выявить смещение, различие в дисперсии и пики данных. Использование одинаковых параметров корзин, диапазонов и сглаживания гарантирует точную интерпретацию графиков и облегчает количественный анализ различий.
Выявление аномалий и выбросов через распределение данных
Для количественного определения выбросов применяют межквартильный размах (IQR):
- Вычисляется Q1 (25-й перцентиль) и Q3 (75-й перцентиль);
- Находится IQR = Q3 — Q1;
- Значения ниже Q1 — 1.5*IQR или выше Q3 + 1.5*IQR считаются выбросами.
Альтернативно используют стандартное отклонение: значения, выходящие за пределы ±3σ от среднего, могут считаться аномальными. Для визуального контроля применяют сочетание гистограммы и KDE, чтобы одновременно оценить плотность данных и наличие экстремальных значений.
После выявления аномалий можно фильтровать данные через boolean indexing или преобразовывать их с помощью clip() для минимизации влияния на анализ распределения и построение моделей.
Вопрос-ответ:
Как построить гистограмму в pandas для одного столбца с числовыми данными?
Для одного столбца используют метод Series.plot.hist(). Важно задать количество корзин через bins и диапазон значений через range. Если данные содержат пропуски, их предварительно удаляют с помощью dropna(), а столбец приводят к числовому типу через astype(float).
Что такое KDE и как построить график плотности распределения в pandas?
KDE (Kernel Density Estimate) показывает непрерывную оценку распределения. Для построения используют метод plot.kde(). Параметр bw_method регулирует сглаживание, а fill=True позволяет закрасить область под кривой. Перед построением удаляют пропуски и приводят данные к числовому типу.
Как правильно выбрать количество корзин (bins) для гистограммы?
Количество корзин зависит от числа наблюдений и размаха данных. Можно использовать правило Стерджеса (bins = 1 + log2(N)), квадратный корень (bins ≈ √N) или метод Фридмана-Дьяконова (bins = 2 * IQR * N^(-1/3)). Также стоит учитывать наличие выбросов и структуру распределения.
Можно ли сравнивать несколько распределений на одной диаграмме в pandas?
Да, используют наложенные гистограммы или KDE-графики. Для корректного сравнения задают одинаковые bins и range. Параметр alpha регулирует прозрачность, а ax позволяет строить несколько кривых на одном графике. Это помогает увидеть различия в пиках и ширине распределений.
Как выявить выбросы с помощью распределения данных?
Для выявления выбросов применяют межквартильный размах (IQR) или стандартное отклонение. Значения ниже Q1 — 1.5*IQR или выше Q3 + 1.5*IQR считаются аномальными. Альтернативно берут значения за пределами ±3σ от среднего. После этого можно фильтровать или корректировать выбросы через boolean indexing или clip().
Как в pandas построить гистограмму для нескольких столбцов и правильно настроить прозрачность?
Для нескольких столбцов используют метод DataFrame.plot.hist() с одинаковыми параметрами bins и range. Параметр alpha задает прозрачность, чтобы перекрывающиеся гистограммы были видны. Например, df[[‘столбец1′,’столбец2’]].plot.hist(bins=20, alpha=0.5) строит наложенные гистограммы с прозрачными столбцами.
Какие методы позволяют выявить выбросы через распределение данных в pandas?
Выбросы выявляют с помощью межквартильного размаха (IQR) или стандартного отклонения. В первом случае вычисляют Q1 и Q3, затем значения ниже Q1 — 1.5*IQR или выше Q3 + 1.5*IQR считают выбросами. При использовании стандартного отклонения берут точки за пределами ±3σ от среднего. После идентификации аномалии можно фильтровать или корректировать через boolean indexing или метод clip().