Содержание статьи

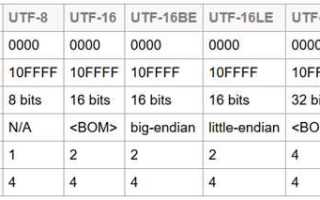
UTF-8 использует переменную длину кодирования: от 1 до 4 байт на символ. Один байт получают кодовые точки от U+0000 до U+007F, включая все базовые символы ASCII. Трёхбайтовую последовательность формируют, например, буквы кириллицы, охватывающие диапазон U+0400–U+04FF. Эмодзи и ряд редких письменностей занимают 4 байта.
Знание точного размера символов позволяет заранее оценить объём данных при сериализации строк, подготовке файлов и сетевых запросов. Для расчёта достаточно определить кодовую точку и сопоставить её с диапазонами UTF-8. Это исключает ошибки при работе с ограничениями длины и квотами.
Практическая проверка размера включает анализ байтовой последовательности или использование функций языка программирования, которые возвращают длину строки в байтах. Такой подход помогает корректно обрабатывать смешанные наборы символов, где соседствуют ASCII, кириллица и эмодзи.
Диапазоны Unicode и соответствие длине закодированных последовательностей
Кодовые точки от U+0000 до U+007F занимают 1 байт и совпадают с ASCII. Символы из диапазонов U+0080–U+07FF требуют 2 байта. Это касается, например, латиницы с диакритикой и ряда знаков пунктуации.
Трёхбайтовые последовательности формируются для кодовых точек U+0800–U+FFFF. В этот диапазон входят кириллица, греческий алфавит, арабское письмо и многие служебные символы. Такой размер устойчиво сохраняется для всех знаков, не выходящих за пределы BMP.
Кодовые точки U+10000–U+10FFFF получают 4 байта. Это затрагивает эмодзи, музыкальные символы, исторические письменности и дополнительные математические знаки. При обработке строк, содержащих такие символы, важно учитывать, что один визуальный знак может занимать в четыре раза больше места, чем базовый ASCII.
Для проверки длины достаточно определить диапазон кодовой точки: он однозначно укажет, сколько байт потребуется в UTF-8. Это позволяет корректно планировать объём данных при работе с файлами, сетевыми пакетами и буферизацией.
Определение размера конкретного символа по его кодовой точке
Размер символа в UTF-8 определяется диапазоном его кодовой точки. Если значение находится в пределах U+0000–U+007F, потребуется 1 байт. Кодовые точки U+0080–U+07FF занимают 2 байта, поскольку для их представления используется расширенная форма с дополнительными битами префикса.
Диапазон U+0800–U+FFFF формирует 3-байтовые записи. К нему относятся большинство современных письменностей, включая кириллицу. При анализе таких символов важно учитывать, что они увеличивают итоговый объём строки по сравнению с ASCII-набором.
Кодовые точки выше U+10000 всегда требуют 4 байта. Эмодзи и дополнительные блоки Unicode попадают именно в этот диапазон. Перед обработкой текста стоит вычислить кодовую точку и сопоставить её с границами диапазонов, чтобы заранее определить размер и избежать ошибок при выделении памяти, проверке лимитов и работе с сетевыми протоколами.
Правила формирования одно-, двух-, трёх- и четырёхбайтовых записей
Однобайтовая запись используется при кодовых точках U+0000–U+007F. Формат представляет собой один байт без префиксных битов, где старший бит равен 0, а остальные содержат значение кодовой точки.
Двухбайтовая последовательность применяется для диапазона U+0080–U+07FF. Первый байт начинается с битового шаблона 110xxxxx, второй – с 10xxxxxx. Значение кодовой точки распределяется по свободным разрядам обоих байтов.
Трёхбайтовая форма охватывает диапазон U+0800–U+FFFF. Первый байт использует шаблон 1110xxxx, а два последующих – 10xxxxxx. Такая структура требуется для письменностей, чьи кодовые точки перестают помещаться в двухбайтовый формат.
Четырёхбайтовая запись предназначена для U+10000–U+10FFFF. Первый байт следует шаблону 11110xxx, остальные три начинаются с 10xxxxxx. Перед обработкой таких символов стоит учитывать повышенную длину последовательности, поскольку она напрямую влияет на объём передаваемых и сохраняемых данных.
Обработка кириллицы и её типичные размеры в UTF-8
Кириллица располагается в диапазоне U+0400–U+04FF и кодируется тремя байтами. Все буквы русского алфавита, включая Ё (U+0401) и ё (U+0451), неизменно попадают в трёхбайтовую форму. Это влияет на итоговый объём строк: текст из 1000 символов занимает около 3000 байт без учёта служебных знаков и пробелов.
Для расчёта размера кириллических символов удобно использовать проверку диапазона кодовой точки. Если символ принадлежит блоку Basic Multilingual Plane и находится в пределах U+0800–U+FFFF, он будет записан в трёхбайтовом виде.
- Базовые буквы: 3 байта каждая.
- Расширенные символы из соседних блоков, например знаки древнеславянского письма, могут занимать 4 байта (если их код выше U+10000).
- Комбинируемые диакритические знаки добавляют свою длину: каждый такой модификатор закодирован отдельной последовательностью.
При работе с кириллическими строками рекомендуется заранее учитывать трёхбайтовый формат, чтобы корректно задавать лимиты в базах данных, сетевых протоколах и буферных структурах.
Особенности кодирования эмодзи и редких письменностей
Эмодзи и большинство редких письменностей располагаются выше U+10000 и формируют четырёхбайтовые последовательности. Такой размер связан с необходимостью размещения большого объёма знаков вне пределов BMP. Любой символ из дополнительных плоскостей Unicode автоматически получает четырёхбайтовую запись в UTF-8.
При работе с эмодзи важно учитывать дополнительные элементы: модификаторы цвета кожи, вариационные селекторы и связующие символы ZWJ. Каждый компонент кодируется собственной последовательностью, что увеличивает суммарную длину итогового графического знака.
| Тип символа | Диапазон Unicode | Длина в UTF-8 |
|---|---|---|
| Базовые эмодзи | U+1F300–U+1FAFF | 4 байта |
| Исторические письменности | U+10000–U+10FFF | 4 байта |
| Модификаторы тона кожи | U+1F3FB–U+1F3FF | 4 байта |
| Вариационные селекторы | U+FE00–U+FE0F | 3 байта |
Для точного подсчёта полезно анализировать каждый элемент составного символа отдельно: итоговая длина определяется суммой всех последовательностей. Такой подход исключает ошибки при формировании сообщений, работающих с жёсткими ограничениями по размеру.
Проверка длины UTF-8-последовательности в программном коде
Длина строки в UTF-8 отличается от количества символов: один графический знак может занимать от 1 до 4 байт. Для корректного подсчёта в коде нужно учитывать фактическое количество байтов, а не только символов.
В Python для получения размера в байтах используется метод encode(‘utf-8’) с последующим len():
len(text.encode(‘utf-8’)) возвращает точное количество байтов, включая эмодзи и кириллические символы.
В JavaScript применяют TextEncoder:
new TextEncoder().encode(text).length вычисляет размер UTF-8-последовательности для любого текста, независимо от блоков Unicode.
Для языков с ручным управлением памятью, например C/C++, рекомендуется обходить строку посимвольно, проверяя первые биты каждого байта для определения длины последовательности:
- 0xxxxxxx – 1 байт
- 110xxxxx – 2 байта
- 1110xxxx – 3 байта
- 11110xxx – 4 байта
Такая проверка предотвращает ошибки при выделении памяти, работе с сетевыми пакетами и сохранении текстов в ограниченные буферы.
Распространённые ошибки при подсчёте байтов и способы их избежать
Одна из частых ошибок – использование длины строки по символам вместо байтов. В UTF-8 один символ может занимать от 1 до 4 байт. len(text) в Python или string.length в JavaScript вернут количество символов, а не байтов, что приводит к недооценке размера.
Игнорирование составных символов, таких как эмодзи с модификаторами или диакритикой, также вызывает ошибки. Каждый компонент кодируется отдельной последовательностью, увеличивая общий объём данных. Рекомендуется проверять длину через encode(‘utf-8’) или TextEncoder.
Ещё одна ошибка – некорректная обработка многоязычных строк в системах с ограничением на размер буфера. Прямое копирование символов без учёта их байтовой длины может привести к обрезке данных и повреждению текста.
Для предотвращения ошибок следует:
- Всегда определять размер строки в байтах, а не в символах.
- Учитывать составные символы и модификаторы.
- Проверять диапазоны кодовых точек при ручной обработке UTF-8.
- Использовать встроенные функции языка для вычисления длины UTF-8-последовательности.
Вопрос-ответ:
Сколько байт занимает символ кириллицы в UTF-8?
Буквы русского алфавита, включая Ё и ё, кодируются трёхбайтовыми последовательностями, так как их кодовые точки находятся в диапазоне U+0400–U+04FF. Это означает, что каждый символ занимает 3 байта, независимо от того, это гласная или согласная буква.
Почему эмодзи занимают больше места, чем обычные буквы?
Эмодзи располагаются в диапазоне U+1F300–U+1FAFF и формируют четырёхбайтовые последовательности. Если эмодзи комбинируется с модификаторами, например тона кожи или вариационными селекторами, каждый компонент кодируется отдельной последовательностью, увеличивая общий размер символа в байтах.
Как определить, сколько байт займёт конкретный символ UTF-8?
Необходимо проверить кодовую точку символа. Если она лежит в диапазоне U+0000–U+007F, символ занимает 1 байт. Диапазон U+0080–U+07FF соответствует 2 байтам, U+0800–U+FFFF — 3 байтам, а U+10000–U+10FFFF — 4 байтам. Такой подход позволяет заранее планировать размер строки при сохранении или передаче данных.
Можно ли использовать длину строки в символах для оценки размера UTF-8?
Нет, длина строки по символам не показывает количество байтов. В UTF-8 один символ может занимать от 1 до 4 байт. Для точного расчёта следует использовать методы, которые возвращают количество байтов, например len(text.encode(‘utf-8’)) в Python или new TextEncoder().encode(text).length в JavaScript.
Какие ошибки чаще всего встречаются при подсчёте байтов UTF-8 и как их избежать?
Частая ошибка — использовать количество символов вместо байтов, что приводит к недооценке размера строк. Также встречается игнорирование составных символов, таких как эмодзи с модификаторами. Чтобы избежать ошибок, рекомендуется вычислять длину через функции кодирования UTF-8, учитывать диапазон кодовых точек и проверять составные символы отдельно.
Почему один и тот же символ может занимать разное количество байтов в UTF-8?
UTF-8 использует переменную длину кодирования. Символы с кодами от U+0000 до U+007F занимают 1 байт, от U+0080 до U+07FF — 2 байта, от U+0800 до U+FFFF — 3 байта, а кодовые точки выше U+10000 — 4 байта. Например, латинская буква «A» — 1 байт, а эмодзи 🌍 — 4 байта. Поэтому один и тот же визуальный знак, если он комбинирован с модификаторами, может потребовать больше байтов.
Как проверить, сколько байт занимает строка с разными языками и символами?
В языках программирования существуют встроенные функции для подсчёта байтов UTF-8. В Python используют len(text.encode(‘utf-8’)), а в JavaScript — new TextEncoder().encode(text).length. Такие методы учитывают все символы, включая кириллицу, эмодзи и составные знаки, что позволяет точно определить объём памяти или объём передаваемых данных.