Содержание статьи

Автоувеличение поля идентификатора избавляет от ручного контроля последовательности записей и снижает риск дублирования ключей. В SQL оно реализуется по-разному: в MySQL используется AUTO_INCREMENT, в PostgreSQL – SERIAL или GENERATED AS IDENTITY, в SQL Server – IDENTITY. Понимание различий помогает выбрать корректный синтаксис под конкретную СУБД.
При создании таблицы важно указать тип данных, способный хранить диапазон будущих значений. Для больших массивов записей лучше использовать BIGINT, чтобы избежать переполнения счётчика. Если таблица уже существует, автоувеличение можно добавить с помощью изменения структуры без пересоздания данных.
Полезно проверять текущее значение счётчика и задавать стартовое число, если требуется сохранить порядок данных после миграций или импорта. Некоторые СУБД позволяют изменять шаг увеличения, что требуется в сценариях распределённой записи или интеграции нескольких источников.
Выбор типа поля для автоувеличения в разных СУБД
При настройке автоувеличения ключа важно учитывать тип данных, поддерживаемый конкретной СУБД. В MySQL для таких задач чаще применяется INT или BIGINT с модификатором AUTO_INCREMENT. INT подходит для таблиц с объёмом до нескольких сотен миллионов строк, а BIGINT выбирают при долгосрочном росте без риска переполнения.
В PostgreSQL применяются типы SERIAL, BIGSERIAL или конструкции GENERATED BY DEFAULT AS IDENTITY. SERIAL формирует связанный последовательный счётчик, а вариант с IDENTITY позволяет управлять параметрами генерации без привязки к отдельной последовательности.
SQL Server использует типы INT и BIGINT совместно с директивой IDENTITY(seed, increment). Выбор между ними определяется предполагаемым пределом записей: INT рассчитан на диапазон до 2 147 483 647, BIGINT – до 9 223 372 036 854 775 807.
Выбор типа следует связывать с объёмом данных, частотой вставок и требованиями к длительному хранению. Недооценка диапазона приводит к остановке вставок из-за переполнения счётчика, поэтому лучше предусмотреть запас.
Создание автоинкремента при создании таблицы
При формировании таблицы автоувеличение ID задаётся на этапе объявления поля. В MySQL используется конструкция AUTO_INCREMENT, позволяющая автоматически генерировать новое значение при каждой вставке. В PostgreSQL применяются варианты SERIAL, BIGSERIAL или выражение GENERATED AS IDENTITY, где поведение генерации задаётся прямо в определении столбца. В SQL Server параметр IDENTITY указывается вместе с типом поля и задаёт стартовое значение и шаг.
Ниже приведены примеры синтаксиса в разных СУБД:
| СУБД | Пример определения столбца |
|---|---|
| MySQL | id INT AUTO_INCREMENT PRIMARY KEY |
| PostgreSQL (SERIAL) | id SERIAL PRIMARY KEY |
| PostgreSQL (IDENTITY) | id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY |
| SQL Server | id INT IDENTITY(1,1) PRIMARY KEY |
Перед выбором конструкции важно сопоставить диапазон значений с предполагаемым объёмом данных. При росте таблицы выше возможностей INT лучше сразу использовать BIGINT, чтобы избежать необходимости переноса данных или изменения структуры позже.
Настройка автоувеличения ID в уже существующей таблице

В MySQL добавление автоинкремента выполняется через изменение структуры столбца: ALTER TABLE users MODIFY id INT NOT NULL AUTO_INCREMENT. Команда доступна только при отсутствии дубликатов и наличии индексирования. Если первичный ключ отсутствует, его потребуется назначить вручную, иначе автогенерация значений не будет работать.
В PostgreSQL механизм зависит от выбранного подхода. Для существующего поля можно создать отдельную последовательность: CREATE SEQUENCE users_id_seq, затем указать её как источник новых значений через ALTER TABLE users ALTER COLUMN id SET DEFAULT nextval('users_id_seq'). При желании перевести столбец в режим IDENTITY используется команда ALTER TABLE users ALTER COLUMN id ADD GENERATED BY DEFAULT AS IDENTITY, что позволяет отказаться от ручного управления последовательностью.
В SQL Server столбец нельзя изменить напрямую, поэтому применяется обходной метод: создаётся временное поле с параметром IDENTITY, данные копируются, исходный столбец удаляется, а временный переименовывается. Такой подход сохраняет текущие значения и позволяет включить автоувеличение без изменения остальной структуры таблицы.
После активации автоинкремента полезно синхронизировать стартовое значение со следующим доступным числом. В MySQL это выполняется командой ALTER TABLE users AUTO_INCREMENT = X, в PostgreSQL – через изменение параметров последовательности, а в SQL Server – при помощи DBCC CHECKIDENT.
Установка начального значения и шага автоинкремента
В MySQL стартовое значение задаётся через параметр таблицы: ALTER TABLE orders AUTO_INCREMENT = 5000. Это применяют при миграциях, когда новые записи должны начинаться с определённого диапазона. Шаг увеличения задаётся глобально через переменную auto_increment_increment, однако изменение влияет на всю инстанцию, поэтому его используют только при необходимости распределённой генерации.
В PostgreSQL управление параметрами выполняет последовательность. Команда ALTER SEQUENCE orders_id_seq RESTART WITH 5000 задаёт новое стартовое число, а параметр INCREMENT BY определяет шаг. Последовательность остаётся независимой от структуры таблицы, поэтому изменения не влияют на другие поля.
SQL Server использует директиву IDENTITY, где параметры задаются при создании столбца. Для изменения стартового значения применяется DBCC CHECKIDENT('orders', RESEED, 5000). Изменить шаг без пересоздания столбца невозможно, поэтому при необходимости другого интервала создают новое поле с нужными параметрами.
Проверка текущего состояния счётчика ID
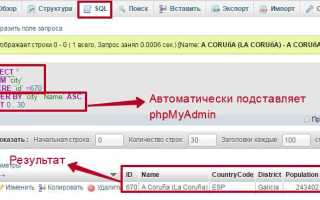
Контроль значения автоинкремента помогает избежать конфликтов при вставке новых записей. В MySQL для этого используют команду:
SHOW TABLE STATUS LIKE 'orders'– столбец Auto_increment показывает следующее значение.
В PostgreSQL проверка выполняется через системную последовательность:
SELECT last_value, increment_by FROM orders_id_seq;– показывает текущее число и шаг автоувеличения.- Если требуется оценить значение для конкретной колонки без прямого доступа к последовательности, используют
SELECT max(id) FROM orders;и сверяют с параметрами последовательности.
В SQL Server применяют встроенную функцию:
DBCC CHECKIDENT('orders', NORESEED);– возвращает текущее состояние идентичности и предупреждает о возможных конфликтах.- Для анализа нескольких таблиц удобно использовать
SELECT IDENT_CURRENT('orders');– возвращает последнее сгенерированное значение ID.
Регулярная проверка особенно важна после массового импорта данных или восстановления резервных копий, чтобы корректно синхронизировать счётчик с существующими записями.
Сброс и изменение значения автоинкремента
В MySQL сброс счётчика выполняется командой ALTER TABLE orders AUTO_INCREMENT = 1. Новое значение должно быть больше или равно максимальному существующему ID, иначе возникнет ошибка вставки. Для корректной последовательности после удаления всех записей достаточно установить автоинкремент в 1.
В PostgreSQL изменение текущего значения последовательности выполняется через ALTER SEQUENCE orders_id_seq RESTART WITH 1000. Это позволяет начать генерацию новых ID с указанного числа без изменения существующих записей. Для контроля шага автоувеличения используется параметр INCREMENT BY.
SQL Server применяет команду DBCC CHECKIDENT('orders', RESEED, 1000), которая изменяет текущее значение идентичности столбца. Новое значение становится следующим при вставке, поэтому перед выполнением рекомендуется проверить максимальный ID в таблице: SELECT MAX(id) FROM orders;.
Сброс и изменение автоинкремента целесообразно при переносе данных, очистке таблицы или подготовке тестовых наборов, чтобы гарантировать непрерывность последовательности без конфликтов.
Типичные ошибки при работе с автоувеличением ID и их причины

В PostgreSQL ошибка возникает при неправильной синхронизации последовательности после массового импорта данных. Если последовательность не обновлена, попытка вставки приводит к конфликту duplicate key value violates unique constraint. Для исправления используют SELECT setval('sequence_name', (SELECT MAX(id) FROM table));.
SQL Server генерирует ошибки при несоответствии значения идентичности и максимального ID в таблице. Попытка вставки нового значения, меньшего текущего счётчика, вызывает нарушение ограничения PRIMARY KEY. Решается командой DBCC CHECKIDENT('table', RESEED, MAX_ID).
Дополнительные ошибки включают превышение диапазона типа данных, попытку изменить автоинкремент без пересоздания столбца в SQL Server и конфликт шага увеличения при распределённых системах. Планирование типа поля, шага и начального значения позволяет избежать большинства проблем.
Вопрос-ответ:
Можно ли добавить автоувеличение к уже существующему столбцу с данными?
Да, но перед этим необходимо убедиться, что все существующие значения уникальны и не содержат NULL. В MySQL это выполняется через ALTER TABLE table_name MODIFY id INT NOT NULL AUTO_INCREMENT. В PostgreSQL создают последовательность и привязывают её к столбцу через ALTER TABLE ... ALTER COLUMN SET DEFAULT nextval(...). В SQL Server столбец с автоинкрементом создают как новый временный, затем копируют данные и переименовывают его.
Как задать конкретное стартовое значение для автоинкремента?
В MySQL стартовое значение меняется командой ALTER TABLE table_name AUTO_INCREMENT = X. В PostgreSQL используют ALTER SEQUENCE sequence_name RESTART WITH X. В SQL Server применяется DBCC CHECKIDENT('table_name', RESEED, X). При этом X должно быть больше или равно текущему максимальному ID, чтобы избежать конфликтов.
Какие типы данных лучше использовать для автоувеличения ID?
Для таблиц с небольшим количеством записей достаточно INT, который поддерживает значения до 2 147 483 647. Для больших объёмов данных или долгосрочного хранения рекомендуется BIGINT, диапазон которого до 9 223 372 036 854 775 807. Выбор типа зависит от предполагаемой нагрузки и продолжительности использования таблицы.
Почему иногда после импорта данных новые ID дублируются?
В PostgreSQL это связано с несинхронизированной последовательностью. После вставки существующих данных последовательность продолжает генерировать значения с начала диапазона, что вызывает конфликты. Для исправления используют команду SELECT setval('sequence_name', (SELECT MAX(id) FROM table));, чтобы последовательность соответствовала текущему максимуму.
Можно ли изменить шаг автоинкремента для уже существующей таблицы?
В MySQL шаг изменяется глобальной переменной auto_increment_increment, что повлияет на все таблицы в базе. В PostgreSQL шаг настраивается через ALTER SEQUENCE sequence_name INCREMENT BY N. В SQL Server изменить шаг без пересоздания столбца невозможно, поэтому при необходимости нового шага создают отдельный столбец с нужным параметром IDENTITY.
Как добавить автоувеличение ID к существующей таблице без потери данных?
В MySQL это делается командой ALTER TABLE table_name MODIFY id INT NOT NULL AUTO_INCREMENT, при условии, что все значения уникальны. В PostgreSQL создают последовательность и привязывают её к столбцу через ALTER TABLE table_name ALTER COLUMN id SET DEFAULT nextval('sequence_name'). В SQL Server столбец с автоинкрементом создают как новый, копируют данные, удаляют старый столбец и переименовывают новый.
Как проверить текущее значение автоинкремента и скорректировать его при необходимости?
В MySQL текущий счётчик можно увидеть через SHOW TABLE STATUS LIKE 'table_name', столбец Auto_increment покажет следующее значение. В PostgreSQL используют SELECT last_value FROM sequence_name; и при необходимости изменяют через ALTER SEQUENCE sequence_name RESTART WITH X. В SQL Server проверка выполняется через DBCC CHECKIDENT('table_name', NORESEED);, а корректировка — через DBCC CHECKIDENT('table_name', RESEED, X);, где X — новое стартовое значение.