Содержание статьи

Многие приложения, связанные с обработкой аудиофайлов или музыкальных библиотек, требуют хранения информации о жанре треков. В проектах на Python это обычно решается через работу с базой данных, словарями или отдельными моделями в фреймворках. Точное определение формата данных помогает избежать ошибок при последующем поиске и фильтрации композиций.
Для хранения жанров можно использовать класс с атрибутами, JSON-структуру или отдельную таблицу в базе данных. Конкретная реализация зависит от архитектуры проекта: локальный скрипт без UI, веб-приложение на Django или API на FastAPI. Важно заранее определить список жанров, чтобы избежать дублирования и несовместимых вариантов, например “rock” и “рок” одновременно.
Дополнительно требуется продумать обработку пользовательского ввода: валидацию, нормализацию регистра, контроль длины строки. Если приложение взаимодействует со сторонними сервисами, удобнее опираться на стандартизированные названия жанров – ID3, MusicBrainz или собственный ограниченный словарь внутри проекта.
Определение структуры данных для жанров в Python-коде

Для хранения жанров подойдёт структура данных, обеспечивающая быстрый доступ по имени и возможность расширения набора свойств. Базовый вариант – список словарей, где каждый элемент описывает жанр: название, описание и связанные теги. Такой формат легко сериализуется в JSON и подходит для небольших проектов.
Если требуется строгая типизация и контроль над полями, рекомендуется использовать dataclasses. Они обеспечивают удобное создание объектов жанров и поддержку аннотаций типов. Это облегчает обработку данных при масштабировании проекта.
Пример полей для жанра музыки:
| Поле | Тип | Назначение |
|---|---|---|
| name | str | Краткое название жанра |
| description | str | Характерные особенности звучания |
| tags | list[str] | Категории для фильтрации и поиска |
Для проектов с обширным каталогом музыки и связями между жанрами лучше применять ORM-модель, где каждый жанр имеет уникальный идентификатор и может быть связан с треками и поджанрами. Такой подход облегчает работу с базами данных и исключает дублирование записей.
Добавление новых жанров через пользовательский ввод

Приём ввода: поле ввода ограничьте по длине – минимум 2, максимум 50 символов. Отклоняйте пустые строки и строки, состоящие только из пробелов. Ограничение по общему количеству жанров: рекомендуем хранить не более 200–500 записей в пользовательской базе; рост числа жанров влияет на навигацию и поиск.
Проверка символов: разрешайте буквы (включая диакритику), цифры, пробел, дефис и апостроф. Для надёжной валидации применяйте проверку по символам (например, для каждого символа проверять .isalpha() или цифру) и нормализацию Юникода с помощью NFKD для удаления диакритики перед сохранением контрольной формы.
Нормализация перед сравнениями: создавайте нормализованную форму – приводите к нижнему регистру, убирайте лишние пробелы (сворачивайте множественные в один), удаляйте управляющие символы и нормализуйте Юникод. Для сравнения и поиска используйте именно эту форму (например, norm_name); отображаемое имя оставляйте в исходном регистре или в Title Case по желанию интерфейса.
Защита от дублей: перед сохранением ищите совпадения по нормализованной форме. Дополнительная мера – сравнение по «соседству» (levenshtein) для обнаружения опечаток: при расстоянии ≤2 показывайте пользователю предупреждение с предложением выбрать существующий жанр.
Сохранение и целостность: для файлового хранения используйте JSON/CSV с атомарной заменой файла (запись во временный файл → fs.replace). Для реляционной БД создайте уникальный индекс по нормализованному имени: CREATE UNIQUE INDEX idx_genres_norm ON genres(norm_name); Это защитит от конкурентных вставок.
UX: показывайте превью результата и пример использования (сколько треков найдётся с таким жанром) до окончательного подтверждения. При массовом добавлении применяйте пакетную валидацию и отчёт о неуспешных записях с причинами.
Права и модерация: разделяйте роли – обычный пользователь может предложить жанр, модератор – одобрить. Для автоматической публикации разрешайте только простые случаи; сложные или редкие названия переводите в очередь модерации.
Логирование и откат: фиксируйте кто, когда и с каким исходным текстом добавил жанр. Храните историю изменений и поддерживайте возможность отката (удаление или объединение жанров), а также связывайте операции с транзакциями базы данных.
Сохранение жанров в JSON или CSV файле
Используйте JSON для структурированных записей (вложенные поля, списки), CSV – для простых таблиц (только поля верхнего уровня). Файлы называйте однозначно: genres.json или genres.csv.
Рекомендуемая схема полей (универсальная): id (int), name (строка, до 100 символов), slug (строка, латиница, дефисы, до 100), description (строка, до 1000), aliases (список строк), related_genres (список id), created_at (ISO 8601), active (bool).
JSON: храните каждый жанр как объект в массиве. При сериализации в Python используйте json.dump(data, fp, ensure_ascii=False, indent=2) для читабельности и корректной кодировки. Пример объекта:
{«id»: 42, «name»: «Synthwave», «slug»: «synthwave», «description»: «Ретроэлектронная эстетика», «aliases»: [«Retrowave»], «related_genres»: [7, 13], «created_at»: «2025-11-16T21:00:00+02:00», «active»: true}.
CSV: сохраняйте только плоские поля. Для списка aliases/related_genres используйте JSON-строку в поле или разделитель ‘;’ – второе предпочтительнее для совместимости, но JSON-строка проще парсится обратно. Открывайте файл с open(path, "w", newline="", encoding="utf-8") и используйте csv.DictWriter с явным fieldnames.
Атомарная запись: сначала записывайте в временный файл (например, genres.json.tmp), затем переименовывайте в конечное имя. При одновременном доступе используйте блокировку (портативные библиотеки filelock) или переключитесь на SQLite/DB при росте конкуренции.
Валидация: проверяйте формат перед сохранением. Для JSON используйте jsonschema или pydantic; для CSV – проверку наличия обязательных полей и длины строк. Ограничения: name и slug – не более 100 символов, description – не более 1000, список aliases – до 20 элементов.
Производительность и масштаб: для файла менее 10 000 записей файловая система приемлема. При росте >10 000 записей или частых записях переходите на базу данных. Для резервных копий делайте ежедневное инкрементное копирование и храните версии файлов с меткой времени.
Кодировка и формат: всегда UTF-8 без BOM, переносы строк ‘\n’. Для CSV используйте запятую как разделитель по умолчанию, экранирование полей через кавычки. Документируйте схему в README рядом с файлом.
Загрузка и использование жанров при запуске программы

При запуске приложения список жанров необходимо загрузить в память, чтобы исключить постоянные обращения к файлу и ускорить обработку запросов пользователя. Для этого используются стандартные модули Python: json или csv – в зависимости от выбранного формата хранения.
Если жанры хранятся в формате JSON, загрузка выполняется через json.load():
with open("genres.json", "r", encoding="utf-8") as file:
genres = json.load(file)
Для CSV используется модуль csv с чтением через csv.reader() или DictReader:
with open("genres.csv", newline="", encoding="utf-8") as file:
reader = csv.reader(file)
genres = [row[0] for row in reader]
Рекомендуется реализовать функцию инициализации, которая автоматически загрузит жанры при старте и предоставит доступ через единый объект. Такой подход облегчает поддержку кода и исключает ситуацию, когда части программы работают с разрозненными копиями данных.
Валидация жанров: проверка уникальности и формата

Перед сохранением названия жанра выполняется проверка на дублирование. Для этого используется поиск совпадений в текущем списке жанров с учетом регистра: «Rock» и «rock» считаются одним значением. Удобно приводить строку к нижнему регистру методом .lower() перед сравнением.
Формат названия ограничивается буквами, цифрами и пробелами. Запрещаются спецсимволы и пустые строки. Для контроля структуры подойдёт регулярное выражение: r'^[A-Za-zА-Яа-я0-9 ]+$'. Оно блокирует ввод недопустимых значков.
Дополнительный фильтр: минимальная длина 2 символа, максимальная зависит от целей проекта, но обычно достаточно 30–40. Любые лишние пробелы по краям удаляются функцией .strip().
Ошибки передаются пользователю в виде понятных сообщений: «Такой жанр уже есть», «Недопустимые символы», «Слишком короткое название». Такая схема предотвращает накопление мусорных данных и поддерживает единый формат записей.
Создание меню выбора жанров в консольном приложении
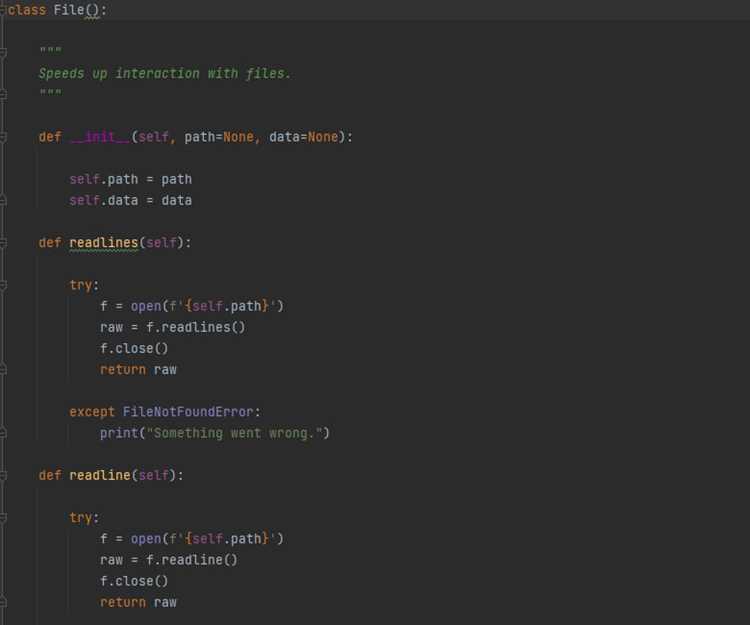
Для удобного выбора музыкальных жанров в консольном приложении можно использовать структурированный список с нумерацией или буквами. Это позволяет пользователю легко ориентироваться и вводить соответствующий номер или символ.
Пример подхода:
- Создать список доступных жанров в виде массива Python:
genres = ["Рок", "Поп", "Джаз", "Классика", "Хип-хоп"] - Вывести меню с нумерацией:
for i, genre in enumerate(genres, 1): print(f"{i}. {genre}") - Запросить ввод пользователя и проверить корректность:
choice = input("Выберите номер жанра: ") if choice.isdigit() and 1 <= int(choice) <= len(genres): selected_genre = genres[int(choice) - 1] print(f"Вы выбрали: {selected_genre}") else: print("Неверный ввод")
Для расширения функционала можно добавить:
- Цикл, позволяющий повторно выбирать жанры без перезапуска программы.
- Возможность добавления новых жанров через отдельный пункт меню.
- Сортировку жанров по алфавиту для быстрого поиска.
- Подсказки по вводу, например, сообщение о допустимых номерах или буквах.
Такое меню обеспечивает понятный интерфейс для взаимодействия с пользователем и упрощает обработку выбранного жанра в дальнейшем коде приложения.
Вопрос-ответ:
Какая структура данных лучше всего подходит для хранения жанров в Python-проекте?
Для хранения жанров часто используют списки или множества. Списки удобны, если важен порядок добавления жанров и возможны дубликаты, которые потом можно фильтровать. Множества подходят для автоматического исключения повторов, что упрощает проверку уникальности. Для более сложных проектов используют словари, где жанр может быть ключом, а значениями – дополнительные характеристики, например, описание или популярность.
Как проверить уникальность нового жанра перед его добавлением в проект?
Чтобы убедиться, что жанр не повторяется, можно сравнивать его с уже существующими элементами в списке или множестве. В случае со списком проверка выполняется с помощью оператора in, например: if genre not in genres_list. Если используется множество, попытка добавить дубликат автоматически игнорируется. Можно также привести строки к одному регистру и удалить лишние пробелы для точной проверки совпадений.
Как сделать меню выбора жанров для консольного приложения на Python?
Меню можно реализовать с помощью цикла, который выводит все доступные жанры с индексами. Пользователь вводит номер выбранного жанра, и программа сопоставляет ввод с элементом списка. Например: for i, genre in enumerate(genres_list, 1): print(f"{i}. {genre}"). Такой подход позволяет легко расширять список жанров и добавлять новые функции, например, удаление или фильтрацию.
Можно ли сохранять список жанров между запусками программы?
Да, для этого используют файлы в формате JSON или CSV. JSON удобен для хранения структурированных данных, включая описания и дополнительные параметры жанров. CSV подходит для простого списка. Для сохранения используется модуль json или csv. При запуске программы файл загружается в память, а при добавлении нового жанра обновляется и сохраняется обратно на диск.
Как добавить возможность пользователю вводить новые жанры через консоль?
Для этого используют функцию input(). Программа запрашивает ввод жанра, проверяет его на пустую строку и уникальность. Если данные корректны, жанр добавляется в структуру данных и при необходимости сохраняется в файл. Дополнительно можно очищать ввод от лишних пробелов и приводить его к одному регистру, чтобы избежать дубликатов, написанных по-разному.