Slnx SQLite представляет собой легковесную встроенную базу данных, ориентированную на хранение структурированных данных прямо внутри приложений. Она не требует отдельного серверного процесса, что упрощает развертывание и сокращает задержки при доступе к информации.
Основное назначение Slnx SQLite – локальное хранение данных в приложениях для настольных систем, мобильных устройств и встроенных решений. Благодаря поддержке транзакций и атомарных операций, база обеспечивает целостность данных даже при внезапных сбоях.
Для работы с Slnx SQLite рекомендуется заранее спроектировать структуру таблиц, учитывая типы данных и индексацию. Это позволяет ускорить выполнение запросов и снизить нагрузку на ресурсы. При необходимости обработки больших объёмов данных важно использовать пакетные операции и ограничения на размер выборок.
Особенности работы включают поддержку стандартного SQL, механизм блокировок при одновременном доступе и возможность интеграции с различными языками программирования. Встроенные функции для поиска и фильтрации данных позволяют минимизировать дополнительную нагрузку на приложение и повышают управляемость базы.
Slnx SQLite назначение и особенности работы
Slnx SQLite предназначена для встроенного хранения данных в приложениях, где требуется высокая скорость доступа без организации отдельного сервера баз данных. Она подходит для мобильных и настольных приложений, а также для прототипирования и небольших корпоративных решений.
Ключевые особенности работы включают поддержку транзакций, атомарность операций и сохранение целостности данных при аварийных завершениях приложений. База использует однопоточную запись с многопоточной возможностью чтения, что важно учитывать при проектировании параллельных процессов.
Для оптимальной работы с Slnx SQLite рекомендуется тщательно выбирать типы данных для колонок, использовать индексы на полях, активно участвующих в фильтрации и сортировке, и применять пакетные операции для вставки больших объёмов данных. Также важно контролировать размер базы и периодически проводить vacuum для освобождения пространства.
Ниже приведена таблица с основными характеристиками и ограничениями Slnx SQLite:
| Характеристика | Описание |
|---|---|
| Тип хранения | Файл на диске, не требует сервера |
| Поддержка SQL | Стандартные SELECT, INSERT, UPDATE, DELETE, JOIN |
| Транзакции | Полная атомарность и поддержка ACID |
| Многопоточность | Одновременное чтение, одиночная запись |
| Индексация | Создание индексов для ускорения выборок |
| Объём базы | До нескольких терабайт при оптимальном управлении |
Использование Slnx SQLite позволяет создавать приложения с автономной работой, быстрым доступом к данным и минимальными требованиями к инфраструктуре, что делает её удобной для широкого спектра практических задач.
Что такое Slnx SQLite и где применяется
Основные сферы применения Slnx SQLite включают:
- Мобильные приложения для хранения пользовательских данных и настроек.
- Настольные программы, где требуется локальная база без сетевого сервера.
- Встроенные устройства и IoT, где важен компактный размер базы.
- Прототипирование и тестирование приложений с быстрым развертыванием.
- Резервное хранение и кэширование данных в системах с высокой нагрузкой на чтение.
Рекомендации по применению:
- Проектировать структуру таблиц с учётом индексов для ускорения выборок.
- Использовать пакетные операции для массовых вставок данных.
- Контролировать размер базы и периодически выполнять vacuum для оптимизации пространства.
- Применять ограничения и проверки целостности данных через схемы таблиц.
- Разрабатывать с учётом однопоточной записи и многопоточного чтения, чтобы избежать блокировок.
Slnx SQLite позволяет создавать автономные, компактные и управляемые решения для различных платформ без дополнительной серверной инфраструктуры.
Установка и подключение Slnx SQLite к проекту
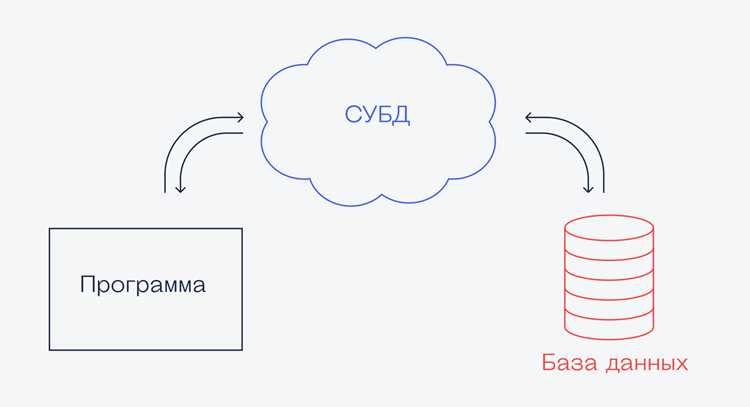
Для интеграции Slnx SQLite в проект необходимо скачать соответствующий пакет с официального репозитория или использовать менеджер пакетов, поддерживаемый выбранным языком программирования. На большинстве платформ доступна предварительно скомпилированная библиотека, совместимая с 32- и 64-битными системами.
После установки необходимо подключить библиотеку к проекту:
- Для C# или .NET проектов используется NuGet-пакет System.Data.SQLite, подключаемый через консоль или графический интерфейс Visual Studio.
- Для Python проектов применяется пакет pysqlite3, устанавливаемый через pip с командой pip install pysqlite3.
- Для C/C++ проектов подключается статическая или динамическая библиотека SQLite с указанием пути к заголовочным файлам и бинарным файлам при сборке.
После подключения рекомендуется проверить работоспособность, создав тестовую базу и таблицу, и выполнив простой запрос SELECT. Это позволит убедиться, что библиотека корректно интегрирована и готова к использованию.
При работе с проектами на нескольких платформах важно учитывать разницу в путях подключения и совместимости версий библиотек, чтобы избежать ошибок при компиляции и запуске приложения.
Структура базы данных и поддерживаемые типы данных

База данных Slnx SQLite хранится в одном файле, который содержит таблицы, индексы, представления и триггеры. Основной элемент структуры – таблица, каждая из которых состоит из колонок с определёнными типами данных и ограничениями.
Slnx SQLite поддерживает следующие типы данных:
- INTEGER – целые числа, используются для идентификаторов и счётчиков.
- REAL – числа с плавающей запятой, применяются для хранения точных измерений или финансовых данных.
- TEXT – строковые значения, подходят для имён, адресов, JSON и XML.
- BLOB – бинарные данные, например изображения или документы.
- NUMERIC – числа с возможностью автоматического преобразования в INTEGER или REAL при необходимости.
При проектировании таблиц рекомендуется:
- Использовать INTEGER для первичных ключей с автогенерацией значений через AUTOINCREMENT.
- Создавать индексы на колонках, активно участвующих в выборках и фильтрах.
- Применять ограничения NOT NULL, UNIQUE и CHECK для обеспечения целостности данных.
- Минимизировать использование BLOB для больших объектов, чтобы не снижать производительность.
Структура базы данных Slnx SQLite позволяет гибко управлять схемой, масштабировать таблицы и поддерживать быстрый доступ к данным при локальном хранении.
Создание таблиц и управление схемой данных

Создание таблиц в Slnx SQLite выполняется с помощью команды CREATE TABLE, где указываются имена колонок, типы данных и ограничения. Каждая таблица должна иметь уникальный первичный ключ, чаще всего в виде INTEGER с AUTOINCREMENT.
Для управления схемой данных используются следующие подходы:
- Добавление и удаление колонок через ALTER TABLE, с ограничением на изменение существующих типов данных.
- Создание индексов для ускорения поиска и сортировки с помощью CREATE INDEX.
- Применение ограничений NOT NULL, UNIQUE и CHECK для поддержания целостности информации.
- Использование внешних ключей через FOREIGN KEY для связей между таблицами.
Рекомендации при проектировании схемы:
- Планировать таблицы с учётом типов запросов и объёмов данных, чтобы минимизировать необходимость изменения схемы в будущем.
- Использовать нормализацию для уменьшения дублирования информации и повышения управляемости базы.
- При больших объёмах данных предпочтительно разбивать таблицы на логические блоки и применять индексацию только на ключевых колонках.
Грамотное создание таблиц и управление схемой данных обеспечивает быстрый доступ, контроль целостности и масштабируемость Slnx SQLite в рамках приложений.
Выполнение запросов и работа с результатами

В Slnx SQLite выполнение запросов осуществляется с использованием стандартного SQL: SELECT, INSERT, UPDATE, DELETE и JOIN. Результаты запросов возвращаются в виде набора строк, которые можно обрабатывать программно в выбранном языке.
Основные рекомендации по работе с запросами:
- Использовать подготовленные выражения (prepared statements) для предотвращения SQL-инъекций и ускорения повторного выполнения запросов.
- Применять фильтры WHERE и сортировку ORDER BY для уменьшения объёма возвращаемых данных и повышения скорости обработки.
- При работе с большими таблицами использовать LIMIT и OFFSET для постраничной загрузки результатов.
- Объединять таблицы через JOIN только при необходимости, чтобы минимизировать нагрузку на память и процессор.
Рекомендации по обработке результатов:
- Сохранять полученные строки в структуру данных, подходящую для последующей фильтрации или агрегации.
- При частых выборках использовать индексы и кэширование для ускорения повторных запросов.
- Для вставки или обновления больших объёмов данных применять транзакции, чтобы уменьшить количество операций записи на диск.
- Проверять результаты выполнения запросов на наличие ошибок и обрабатывать исключения для сохранения целостности данных.
Соблюдение этих рекомендаций позволяет оптимально использовать возможности Slnx SQLite для быстрого выполнения запросов и управления результатами.
Обработка ошибок и защита данных в Slnx SQLite

В Slnx SQLite ошибки при работе с базой данных могут возникать на этапе выполнения запросов, вставки или обновления данных, а также при нарушении ограничений схемы. Для корректной обработки рекомендуется использовать транзакции и блоки try-catch или аналогичные механизмы выбранного языка.
Рекомендации по обработке ошибок:
- Осуществлять проверку возвращаемых кодов выполнения запросов и обрабатывать их соответствующим образом.
- Использовать транзакции для группирования нескольких операций, чтобы при возникновении ошибки выполнить ROLLBACK и вернуть базу в исходное состояние.
- Логировать ошибки с указанием SQL-запроса и контекста выполнения для последующего анализа.
Механизмы защиты данных включают:
- Применение ограничений NOT NULL, UNIQUE и CHECK для контроля допустимых значений.
- Использование внешних ключей (FOREIGN KEY) для поддержания целостности связей между таблицами.
- Шифрование файлов базы данных и управление правами доступа к файлам для предотвращения несанкционированного чтения или изменения данных.
- Регулярное резервное копирование базы для восстановления данных в случае сбоев или повреждений.
Следование этим рекомендациям обеспечивает сохранность информации, предотвращает потерю данных и минимизирует влияние ошибок на работу приложения с Slnx SQLite.
Оптимизация хранения и особенностей работы с большими объёмами данных
При работе с большими объёмами данных в Slnx SQLite важно минимизировать нагрузку на диск и память. Оптимизация начинается с правильного проектирования схемы таблиц и выбора типов данных.
Рекомендации по оптимизации хранения:
- Использовать компактные типы данных, например INTEGER вместо TEXT для идентификаторов.
- Создавать индексы только на колонках, активно используемых в фильтрах и сортировках, чтобы уменьшить расход памяти и ускорить выборки.
- Разбивать большие таблицы на логические блоки или использовать отдельные базы для разных модулей приложения.
- Периодически выполнять VACUUM для освобождения неиспользуемого пространства и дефрагментации базы.
Особенности работы с большими объёмами данных:
- Вставки и обновления рекомендуется выполнять пакетно внутри транзакций, чтобы снизить количество операций записи.
- Чтение данных лучше организовывать постранично через LIMIT и OFFSET, избегая загрузки всей таблицы в память.
- Использовать подготовленные выражения (prepared statements) для повторяющихся запросов, что снижает накладные расходы на парсинг SQL.
- Контролировать одновременный доступ потоков: однопоточная запись и многопоточное чтение предотвращают блокировки и замедление работы.
Применение этих подходов обеспечивает устойчивую работу Slnx SQLite с большими объёмами данных и поддерживает высокую скорость выполнения запросов при локальном хранении.
Вопрос-ответ:
Для каких типов приложений лучше всего подходит Slnx SQLite?
Slnx SQLite хорошо подходит для мобильных и настольных приложений, где необходима локальная база данных без установки серверного ПО. Она удобна для небольших корпоративных систем, прототипов и встроенных устройств, где требуется быстрый доступ к данным в одном файле без организации отдельного сервера.
Как правильно проектировать таблицы в Slnx SQLite для больших объёмов данных?
При проектировании таблиц следует заранее определить типы данных и первичные ключи, использовать индексы для колонок, которые участвуют в фильтрации и сортировке, и разбивать большие таблицы на логические блоки. Для массовых операций вставки и обновления рекомендуется применять транзакции, чтобы снизить нагрузку на диск и ускорить обработку.
Какие меры защиты данных доступны в Slnx SQLite?
Для защиты данных используются ограничения целостности (NOT NULL, UNIQUE, CHECK), внешние ключи для связи между таблицами и возможность шифрования файлов базы. Регулярное резервное копирование позволяет восстановить данные при повреждении файла или сбое приложения.
Какие ошибки чаще всего возникают при работе с Slnx SQLite и как их обрабатывать?
Наиболее частые ошибки связаны с нарушением ограничений таблиц, попыткой записи в заблокированный файл и синтаксическими ошибками SQL. Рекомендуется использовать транзакции для группы операций, проверять коды выполнения запросов, обрабатывать исключения через try-catch и вести журнал ошибок с указанием контекста выполнения, чтобы быстро выявлять причины сбоев.