Содержание статьи

В Python термин substring обозначает подстроку – часть строки, полученную по заданным границам или условиям. Работа с подстроками применяется при обработке пользовательского ввода, анализе логов, разборе файлов, проверке форматов данных и автоматизации текстовых задач. Любая строка в Python является последовательностью символов, что позволяет обращаться к её отдельным фрагментам напрямую.
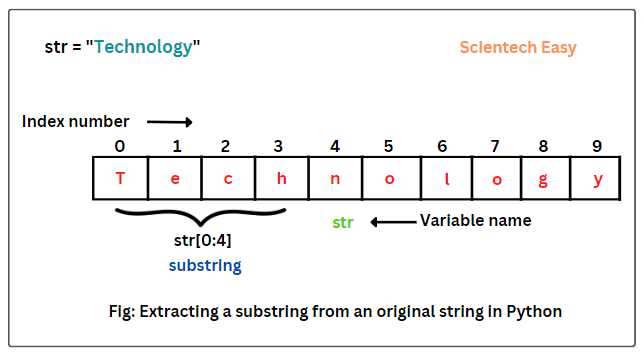
Базовый способ получения подстроки – срезы строк. Они используют индексирование и позволяют указать начальную позицию, конечную границу и шаг. Например, выражение text[2:5] вернёт фрагмент строки с индексами 2, 3 и 4. При этом Python не выдаёт ошибку, если границы выходят за длину строки, что упрощает работу с динамическими данными.
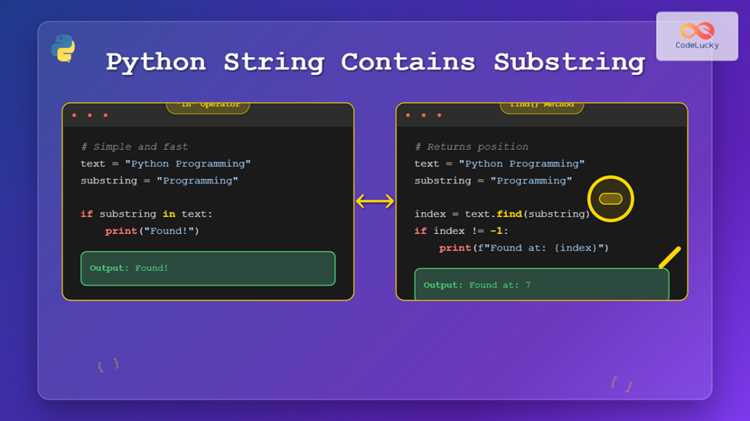
Помимо срезов, подстроки часто извлекаются через встроенные методы строк: find(), index(), split(), replace(). Они применяются, когда требуется найти нужный фрагмент по содержимому, а не по позиции. Оператор in используется для быстрой проверки наличия подстроки без получения её индекса.
При работе с кириллицей и другими Unicode-символами Python оперирует символами, а не байтами, поэтому подстроки корректно обрабатываются вне зависимости от языка текста. Это позволяет безопасно извлекать фрагменты строк из русскоязычных данных, JSON-файлов и HTML-кода без дополнительных преобразований.
Substring в Python: значение и способы применения
Строки в Python являются неизменяемыми объектами, поэтому любая операция с подстрокой возвращает новый объект str, а не изменяет исходную строку.
Основные способы получения и использования подстрок:
- срезы строк с указанием начального и конечного индекса;
- поиск подстроки и извлечение по найденной позиции;
- проверка наличия подстроки в строке;
- разделение строки на части и работа с отдельными фрагментами.
Срез строки – базовый механизм работы с подстроками. Синтаксис: строка[start:end:step]. Индекс start включается, end – нет.
text = "Python substring example"
part = text[7:16] # 'substring'Если start или end опущены, Python использует начало или конец строки. Отрицательные индексы позволяют обращаться к символам с конца.
last_word = text[-7:] # 'example'Для поиска подстроки применяются методы find(), rfind() и index(). Они возвращают позицию первого символа подстроки.
find()– возвращает-1, если подстрока не найдена;index()– вызывает исключениеValueErrorпри отсутствии подстроки;rfind()– ищет с конца строки.
pos = text.find("sub")
if pos != -1:
result = text[pos:pos + 9]Для проверки наличия подстроки используется оператор in. Он работает быстрее и читаемее, чем ручной поиск индекса.
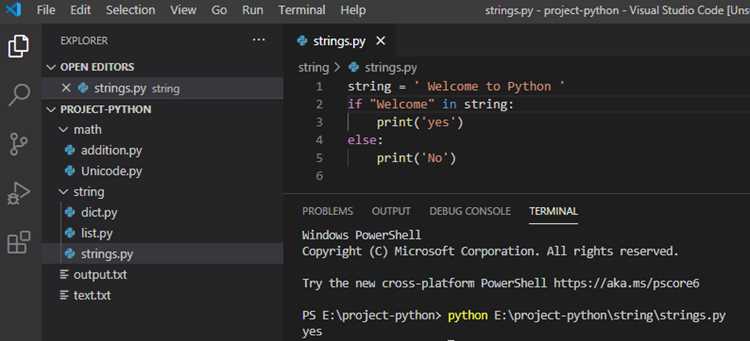
if "Python" in text:
print("Подстрока найдена")Методы строк часто применяются для извлечения подстрок по логическим условиям:
split()– разбивает строку на список подстрок по разделителю;partition()– делит строку на три части: до, разделитель, после;replace()– заменяет одну подстроку другой, возвращая новую строку.
domain = "user@example.com".split("@")[1]Подстроки активно используются при обработке данных:
- парсинг логов, URL, email-адресов;
- валидация и нормализация пользовательского ввода;
- извлечение значений из текстовых конфигураций;
- анализ файлов CSV и текстовых отчётов.
При работе с большими строками рекомендуется минимизировать количество операций среза и копирования, так как каждая подстрока создаёт новый объект и потребляет дополнительную память.
Понятие подстроки в строках Python и области применения
Строки в Python являются неизменяемыми. Это означает, что извлечение подстроки всегда создаёт новый объект в памяти, а исходная строка остаётся без изменений. Данный факт следует учитывать при обработке больших объёмов текстовых данных.
Формирование подстрок выполняется несколькими способами:
Срезы строк – основной и самый предсказуемый механизм. Синтаксис использует числовые индексы символов, начиная с нуля. Конечный индекс не включается в результат.
value = "abcdef"[1:4] # 'bcd'
Поддержка отрицательных индексов позволяет обращаться к символам с конца строки, что удобно при обработке суффиксов и фиксированных окончаний.
Поиск подстрок применяется, когда границы фрагмента заранее неизвестны. Методы find() и index() возвращают позицию первого вхождения, после чего подстрока извлекается через срез.
start = text.find(":")
result = text[start + 1:]
Для логической проверки наличия фрагмента используется оператор in. Он не возвращает позицию, но работает быстрее и упрощает условия.
if ".py" in filename:
Методы обработки строк позволяют работать с подстроками без явного указания индексов:
split() – разделяет строку по разделителю и возвращает список подстрок.
partition() – разбивает строку на три логические части.
replace() – формирует новую строку с заменой одной подстроки на другую.
Подстроки активно используются в прикладных задачах:
анализ логов – выделение дат, кодов ошибок, IP-адресов;
обработка пользовательского ввода – извлечение параметров, проверка форматов;
работа с путями и именами файлов – получение расширений, каталогов;
парсинг сетевых данных – обработка URL, HTTP-заголовков, email.
При интенсивной работе со строками рекомендуется сокращать число промежуточных подстрок и по возможности использовать встроенные методы, так как они оптимизированы на уровне интерпретатора.
Получение подстроки через срезы: синтаксис start:end:step
Срезы строк в Python – прямой способ получения подстроки по индексам символов. Общий синтаксис: строка[start:end:step], где каждый параметр задаёт границы и порядок выборки символов.
Параметр start указывает индекс первого символа подстроки. Нумерация начинается с нуля. Если start не задан, выборка начинается с начала строки.
text = "substring"
part = text[3:] # 'string'
Параметр end определяет индекс, до которого выполняется срез. Символ с этим индексом в результат не включается. При отсутствии end подстрока берётся до конца строки.
part = text[:6] # 'substr'
Параметр step задаёт шаг выборки символов. Он позволяет пропускать символы или получать подстроку в обратном порядке.
text[::2] # 'sbsrn'
text[::-1] # 'gnirtsbus'
Отрицательные значения start и end отсчитываются от конца строки. Это удобно при работе с суффиксами и фиксированной длиной данных.
filename = "report_2024.pdf"
ext = filename[-3:] # 'pdf'
Срезы не вызывают исключений при выходе индексов за границы строки. Python автоматически ограничивает диапазон, что упрощает обработку динамических данных.
"abc"[0:100] # 'abc'
Следует учитывать, что каждый срез создаёт новый объект str. При многократной обработке больших строк предпочтительно минимизировать количество срезов или использовать встроенные методы, такие как split() и partition(), которые выполняются быстрее на уровне интерпретатора.
Работа с отрицательными индексами и границами строки
Отрицательные индексы в Python позволяют обращаться к символам строки, отсчитывая позицию с конца. Индекс -1 указывает на последний символ, -2 – на предпоследний. Такой подход удобен при обработке строк переменной длины.
text = "configuration"
last_char = text[-1] # 'n'
Отрицательные индексы активно используются в срезах для извлечения суффиксов и фиксированных фрагментов в конце строки.
suffix = text[-4:] # 'tion'
При комбинировании положительных и отрицательных границ Python корректно вычисляет диапазон, если start логически расположен левее end.
part = text[2:-3] # 'figur'
Если начальный индекс больше или равен конечному, результатом среза будет пустая строка, без возникновения исключения.
"data"[3:1] # ''
Выход индексов за фактические границы строки не приводит к ошибке. Интерпретатор автоматически ограничивает диапазон допустимыми значениями.
"abc"[-10:5] # 'abc'
Отрицательный шаг в срезе изменяет направление обхода строки. В этом случае start должен быть больше end, иначе подстрока не будет получена.
reversed_text = text[::-1] # 'noitarugifnoc'
Для выборки подстроки в обратном порядке с заданными границами необходимо явно задавать оба индекса.
segment = text[-1:-6:-1] # 'noita'
При использовании отрицательных индексов рекомендуется явно проверять логику диапазонов, особенно при динамическом формировании границ, чтобы избежать скрытых ошибок и получения пустых результатов.
Поиск и извлечение подстрок с помощью методов find, index, in
Методы find() и index() позволяют определить позицию первой подстроки в строке. find() возвращает -1, если подстрока не найдена, а index() вызывает ValueError.
text = "python substring example"
pos = text.find("substring") # 7
pos_index = text.index("substring") # 7
С помощью найденного индекса подстроку можно извлечь через срез:
sub = text[pos:pos + len("substring")] # 'substring'
Метод rfind() выполняет поиск с конца строки, что удобно при наличии нескольких одинаковых подстрок.
text.rfind("e") # 22
Оператор in проверяет наличие подстроки и возвращает True или False. Он не предоставляет позиции, но работает быстрее и удобен для условий.
if "python" in text:
print("Подстрока найдена")
Для извлечения нескольких вхождений подстрок можно комбинировать find() с циклом и сдвигом индекса:
start = 0
while True:
pos = text.find("e", start)
if pos == -1:
break
print(text[pos:pos+1])
start = pos + 1
При динамическом поиске и извлечении рекомендуется проверять возвращаемое значение find(), чтобы избежать ошибок при срезах и некорректных индексах.
Извлечение фрагментов строки по условиям и шаблонам
Извлечение подстрок по условиям позволяет выбирать символы или последовательности, удовлетворяющие определённым критериям. В Python применяются методы строк и регулярные выражения.
Для простых условий используются методы split(), partition() и генераторы списков. Например, извлечение всех слов длиной больше 3 символов:
text = "python is a versatile language"
words = [word for word in text.split() if len(word) > 3]
# ['python', 'versatile', 'language']
Метод partition() разделяет строку на три части по первому вхождению разделителя:
text = "user:admin:active"
before, sep, after = text.partition(":")
# before='user', sep=':', after='admin:active'
Для более сложных шаблонов используется модуль re, который позволяет задавать регулярные выражения и извлекать совпадения.
| Метод | Описание | Пример |
|---|---|---|
| re.search() | Находит первое совпадение по шаблону | m = re.search(r'\d+', 'item123') |
| re.findall() | Возвращает все совпадения в виде списка | re.findall(r'\d+', 'item123 code456') |
| re.match() | Проверяет совпадение в начале строки | re.match(r'item', 'item123') |
| re.sub() | Заменяет совпадения на указанный текст | re.sub(r'\d+', '#', 'item123') |
Регулярные выражения позволяют извлекать подстроки по сложным условиям: цифры, буквы, наборы символов, фиксированные форматы.
При обработке больших текстов рекомендуется заранее компилировать шаблоны через re.compile() для повышения производительности и повторного использования.
Особенности подстрок при работе с Unicode и кириллицей
Строки в Python 3 хранятся в формате Unicode, что позволяет корректно работать с кириллицей и другими многобайтовыми символами без необходимости дополнительных кодировок. Каждый символ строки имеет индекс, который учитывает именно символ, а не количество байт.
Извлечение подстрок через срезы работает одинаково для латиницы и кириллицы:
text = "Привет мир"
sub = text[0:6] # 'Привет'
Методы поиска find(), index() и оператор in корректно обрабатывают кириллические символы:
if "мир" in text:
pos = text.find("мир") # 7
При работе с Unicode важно учитывать нормализацию символов. Например, символы с диакритикой могут существовать в разных формах (составной и комбинированной), что влияет на сравнение подстрок.
Использование модуля unicodedata позволяет стандартизировать строки перед поиском или срезами:
import unicodedata
normalized = unicodedata.normalize('NFC', text)
Функции len(), срезы и методы строк учитывают символы, а не байты, поэтому при работе с кириллицей и другими многобайтовыми алфавитами стандартные операции остаются корректными.
Рекомендации при работе с подстроками в Unicode:
- Использовать нормализацию через
unicodedata.normalizeдля сравнения подстрок. - Избегать прямого обращения к байтам строки при обработке Unicode.
- Для проверки принадлежности символов использовать методы
isalpha(),isdigit(), которые учитывают Unicode. - При регулярных выражениях применять флаг
re.UNICODEдля корректной работы с кириллицей.
Вопрос-ответ:
Что такое подстрока в Python и чем она отличается от обычной строки?
Подстрока — это часть строки, состоящая из последовательных символов исходного текста. В Python отдельного типа substring нет, подстроки формируются через срезы, методы поиска или разделения строк. Она всегда является новым объектом str, а исходная строка остаётся неизменной.
Как извлечь подстроку с помощью срезов и как работает синтаксис start:end:step?
Срез строки задаётся как строка[start:end:step]. start — индекс первого символа, end — индекс символа, до которого берём срез (не включительно), step — шаг. Можно использовать отрицательные индексы для обращения к символам с конца. Например, text[1:5] извлечёт символы со второго по пятый, а text[::-1] вернёт строку в обратном порядке.
В чём разница между методами find() и index() при поиске подстрок?
Оба метода возвращают индекс первого вхождения подстроки. Отличие в обработке отсутствия подстроки: find() возвращает -1, если подстрока не найдена, а index() вызывает исключение ValueError. Для безопасного извлечения рекомендуется сначала проверять результат find().
Можно ли работать с кириллическими подстроками так же, как с латинскими?
Да, строки в Python хранятся в формате Unicode, поэтому с кириллицей срезы, поиск и методы str работают корректно. При сравнении или нормализации текста с диакритикой желательно использовать unicodedata.normalize(). Методы isalpha() и регулярные выражения с флагом re.UNICODE учитывают кириллицу.
Как извлечь фрагменты строки по определённым условиям или шаблонам?
Для простых условий используют split(), partition() и генераторы списков. Для более сложных шаблонов применяются регулярные выражения через модуль re. Методы re.search() и re.findall() позволяют находить соответствия по заданной структуре, а re.sub() — заменять их. Это удобно для обработки чисел, кодов, email-адресов и других повторяющихся шаблонов.