Содержание статьи

В SQL часто возникает задача подсчета строк, которые содержат одинаковые значения в одном или нескольких столбцах. Для таких операций применяется комбинация функций COUNT и GROUP BY, позволяющая сгруппировать данные и определить количество повторов. Например, подсчет количества заказов каждого клиента в таблице Orders позволяет выявить самых активных покупателей.
Для фильтрации групп по количеству повторений используется HAVING. Это позволяет не только подсчитать дублирующиеся значения, но и выбрать только те, которые встречаются более заданного числа раз. Такой подход актуален при анализе инвентаря, выявлении часто повторяющихся ошибок в логах или подсчете повторов транзакций.
При работе с несколькими столбцами можно комбинировать их в GROUP BY, чтобы подсчитать уникальные сочетания значений. Например, в таблице продаж можно определить количество транзакций по комбинации Продукт + Регион, что дает более точную картину распределения продаж по регионам.
Подзапросы позволяют создавать промежуточные агрегаты для сложных случаев подсчета. Это особенно полезно при анализе больших таблиц с множеством условий фильтрации и объединений. Подсчет строк с одинаковыми значениями становится инструментом контроля качества данных и оптимизации отчетности.
Использование COUNT для подсчета повторяющихся значений

Функция COUNT позволяет определить количество строк в таблице, соответствующих заданному условию. Для подсчета повторяющихся значений используется совместно с GROUP BY, что позволяет агрегировать строки по выбранному столбцу.
Пример подсчета количества заказов каждого клиента в таблице Orders:
| SQL-запрос |
|---|
|
SELECT CustomerID, COUNT(*) AS OrderCount FROM Orders GROUP BY CustomerID; |
В результате получаем таблицу, где каждый клиент представлен один раз, а в колонке OrderCount указано число заказов:
| CustomerID | OrderCount |
|---|---|
| 1 | 5 |
| 2 | 3 |
| 3 | 8 |
Для подсчета уникальных значений в столбце применяется COUNT(DISTINCT столбец). Например, чтобы узнать количество уникальных продуктов, заказанных каждым клиентом:
| SQL-запрос |
|---|
|
SELECT CustomerID, COUNT(DISTINCT ProductID) AS UniqueProducts FROM Orders GROUP BY CustomerID; |
Такой подход помогает быстро выявлять дублирующиеся записи, контролировать повторяющиеся транзакции и анализировать разнообразие данных в таблицах. Для больших объемов данных рекомендуется использовать индексы на колонках, участвующих в подсчете, чтобы ускорить выполнение запросов.
Группировка данных с помощью GROUP BY

Оператор GROUP BY позволяет объединять строки с одинаковыми значениями в выбранных столбцах и выполнять агрегатные функции, такие как COUNT, SUM, AVG. Это ключевой инструмент для подсчета повторяющихся значений и анализа распределения данных.
Пример подсчета количества заказов по каждому продукту в таблице Orders:
SELECT ProductID, COUNT(*) AS OrderCount
FROM Orders
GROUP BY ProductID;
Результат показывает, сколько раз каждый продукт встречается в заказах. Для более сложного анализа можно группировать по нескольким столбцам одновременно. Например, чтобы подсчитать количество заказов каждого продукта по регионам:
SELECT Region, ProductID, COUNT(*) AS OrderCount
FROM Orders
GROUP BY Region, ProductID;
Использование GROUP BY совместно с агрегатными функциями позволяет быстро выявлять повторяющиеся записи, определять популярные товары, анализировать активность клиентов по категориям и регионам. Для оптимизации запросов рекомендуется создавать индексы на колонках, участвующих в группировке, особенно при работе с большими таблицами.
Применение HAVING для фильтрации групп по количеству
Оператор HAVING позволяет фильтровать группы данных после применения GROUP BY. В отличие от WHERE, который работает на уровне отдельных строк, HAVING проверяет агрегатные значения, такие как COUNT, SUM или AVG.
Пример фильтрации клиентов, которые сделали более 5 заказов:
SELECT CustomerID, COUNT(*) AS OrderCount
FROM Orders
GROUP BY CustomerID
HAVING COUNT(*) > 5;
Применение HAVING позволяет:
- Выделять группы с высокой активностью, например, клиентов с большим числом заказов.
- Отслеживать популярные товары по количеству продаж.
- Фильтровать дублирующиеся записи для анализа качества данных.
- Анализировать транзакции с повторяющимися значениями для выявления аномалий.
Для комбинированного анализа можно использовать несколько условий с логическими операторами:
SELECT ProductID, COUNT(*) AS SaleCount
FROM Orders
GROUP BY ProductID
HAVING COUNT(*) > 10 AND COUNT(*) < 50;
Это позволяет фокусироваться на продуктах с средним уровнем продаж, исключая редкие и чрезмерно популярные позиции. Использование HAVING повышает точность аналитики при работе с агрегированными данными.
Подсчет уникальных значений с DISTINCT

Оператор DISTINCT используется для исключения повторяющихся значений в столбцах при подсчете. Совместно с COUNT он позволяет определить точное количество уникальных записей.
Пример подсчета различных продуктов, заказанных каждым клиентом в таблице Orders:
SELECT CustomerID, COUNT(DISTINCT ProductID) AS UniqueProducts
FROM Orders
GROUP BY CustomerID;
В результате отображается количество уникальных товаров на клиента, что помогает анализировать разнообразие заказов и выявлять клиентов с широким ассортиментом покупок.
Для подсчета уникальных комбинаций нескольких столбцов можно использовать конструкцию:
SELECT COUNT(DISTINCT ProductID, Region) AS UniqueProductRegions
FROM Orders;
Это позволяет определить уникальные сочетания продукта и региона или клиента и категории, что важно для анализа распределения продаж и оптимизации складских запасов. При больших таблицах рекомендуется создавать индексы на используемых столбцах, чтобы ускорить выполнение запросов с DISTINCT.
Сравнение нескольких столбцов при подсчете повторов
Подсчет повторяющихся значений в нескольких столбцах позволяет выявлять дублированные записи и анализировать уникальные сочетания данных. Для этого используется GROUP BY с перечислением нескольких столбцов и агрегатная функция COUNT.
Пример подсчета количества заказов по комбинации продукта и региона в таблице Orders:
SELECT ProductID, Region, COUNT(*) AS OrderCount
FROM Orders
GROUP BY ProductID, Region;
Результат позволяет:
- Определять, какие продукты продаются в каких регионах чаще всего.
- Выявлять комбинации данных с высокой повторяемостью для анализа инвентаря.
- Исключать дублированные записи при подготовке отчетов.
Для фильтрации групп по количеству повторов применяется HAVING:
SELECT ProductID, Region, COUNT(*) AS OrderCount
FROM Orders
GROUP BY ProductID, Region
HAVING COUNT(*) > 10;
Такой подход помогает концентрироваться на значимых сочетаниях данных, ускоряет анализ и повышает точность отчетности при работе с большими таблицами.
Использование подзапросов для сложных подсчетов
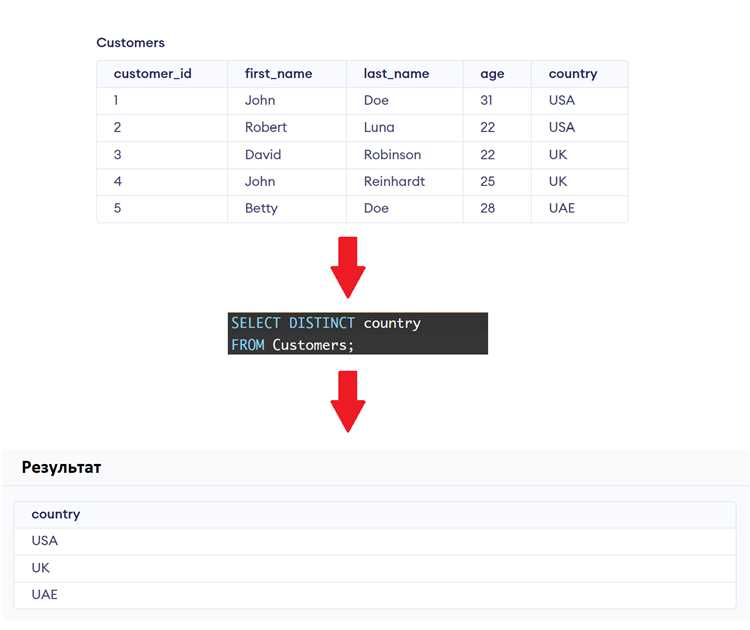
Подзапросы позволяют выполнять подсчет строк с одинаковыми значениями в случаях, когда требуется предварительная фильтрация или агрегирование данных. Они используются внутри FROM, WHERE или SELECT для создания промежуточных наборов данных.
Пример подсчета клиентов, которые сделали более одного заказа с конкретным продуктом:
SELECT CustomerID, COUNT(*) AS OrderCount
FROM Orders
WHERE ProductID IN (
SELECT ProductID
FROM Orders
GROUP BY ProductID
HAVING COUNT(*) > 1
)
GROUP BY CustomerID;
Использование подзапросов позволяет:
- Сочетать условия на нескольких уровнях агрегирования.
- Фокусироваться на повторяющихся значениях только в выбранных подмножествах данных.
- Сравнивать результаты различных агрегатов между собой.
- Избегать дублирования логики при сложных аналитических запросах.
Для оптимизации рекомендуется использовать индексы на колонках, участвующих в подзапросах, и ограничивать выборку только необходимыми столбцами. Это ускоряет выполнение запросов и снижает нагрузку на сервер при работе с большими таблицами.
Примеры практических задач с повторяющимися строками

Подсчет повторяющихся строк позволяет решать реальные задачи анализа данных и контроля информации в таблицах. Примеры практического применения:
- Анализ активности клиентов: подсчет количества заказов каждого клиента для выявления самых активных покупателей.
SELECT CustomerID, COUNT(*) AS OrderCount FROM Orders GROUP BY CustomerID;
- Выявление популярных товаров: определение продуктов, которые чаще всего заказывают, чтобы оптимизировать запасы.
SELECT ProductID, COUNT(*) AS SaleCount FROM Orders GROUP BY ProductID HAVING COUNT(*) > 10;
- Контроль повторяющихся транзакций: поиск дублированных записей в финансовых операциях или логах.
SELECT TransactionID, COUNT(*) AS DuplicateCount FROM Transactions GROUP BY TransactionID HAVING COUNT(*) > 1;
- Анализ распределения по категориям: подсчет уникальных сочетаний категорий и регионов для маркетинговых отчетов.
SELECT CategoryID, Region, COUNT(*) AS Count FROM Orders GROUP BY CategoryID, Region;
Применение этих методов позволяет принимать решения на основе точных данных, выявлять закономерности и контролировать качество информации в базе.