Содержание статьи

Семантическое ядро – это структурированный набор поисковых запросов, отражающих реальные формулировки пользователей и связь этих формулировок с разделами сайта. Ошибки на этапе подбора запросов приводят к нерелевантному трафику, просадке поведенческих метрик и неправильной архитектуре страниц. Поэтому работа с ядром начинается не с инструментов, а с анализа тематики, типов спроса и логики поиска.
Для сбора данных используются источники с разной природой: поисковые подсказки, отчёты Яндекс Wordstat и Google Keyword Planner, данные из Google Search Console, а также выгрузки запросов конкурентов. Каждый источник даёт свой срез: подсказки показывают формулировки, Wordstat – частотность и сезонность, консоль – фактические показы сайта. Игнорирование хотя бы одного из них искажает картину спроса.
После сбора запросы группируются не по словам, а по поисковому намерению. Информационные, коммерческие и навигационные запросы не смешиваются в одном кластере, даже если совпадают по лексике. Проверка интента проводится через анализ выдачи: типы страниц в ТОП-10, наличие блоков с товарами, статей, калькуляторов, фильтров.
Финальный этап – очистка и приоритизация. Из ядра исключаются дубликаты, нерелевантные формулировки, запросы с нулевым потенциалом показов. Оставшиеся группы соотносятся с существующими или планируемыми страницами. Если под кластер нельзя логично создать отдельную страницу, он перераспределяется или удаляется. Такой подход позволяет получить ядро, которое напрямую используется в структуре сайта и контенте, а не остаётся формальной таблицей.
Формулирование задач сайта и ожидаемых действий посетителей

Определение семантического ядра начинается с чёткого понимания целей сайта. Для каждого раздела необходимо зафиксировать ключевую задачу: привлечение новых клиентов, конверсия в покупку, сбор лидов, предоставление информации или удержание аудитории. Без этого невозможно корректно соотнести запросы пользователей с конкретными страницами.
Следующий шаг – анализ ожидаемых действий посетителей. Для интернет-магазина это оформление заказа или добавление товара в корзину, для корпоративного сайта – отправка заявки или скачивание презентации, для информационного ресурса – просмотр статей и подписка на обновления. Каждое действие фиксируется и учитывается при группировке поисковых запросов.
При составлении ядра следует разделять запросы по типу намерения: транзакционные для конверсий, информационные для изучения продукта и навигативные для быстрого доступа к разделам сайта. Каждое намерение связывается с конкретной страницей и соответствующим элементом интерфейса, что повышает релевантность и эффективность продвижения.
Рекомендовано создавать карту взаимодействий пользователя: последовательность шагов от запроса до целевого действия. Это позволяет выявить пробелы в структуре сайта, несоответствия между запросами и контентом, а также формирует основу для дальнейшего расширения семантического ядра с учётом реальных сценариев поведения аудитории.
Сбор исходных поисковых запросов по тематике проекта

Запросы собираются без фильтрации, фиксируются все вариации: с опечатками, с географической привязкой, с уточняющими словами. Это позволяет на следующем этапе правильно сгруппировать их по кластерам и типам поискового намерения. Для удобства сбор ведётся в таблицах с колонками: фраза, частотность, сезонность, источник.
При сборе важно учитывать сезонные и региональные особенности. Частотность одного и того же запроса может различаться в зависимости от региона и времени года. Поэтому собираются данные по ключевым городам и кварталам, чтобы планировать контент и рекламные кампании с точностью до конкретного периода.
Фиксация всей собранной базы в едином формате обеспечивает последующую обработку: удаление дублей, анализ интента, формирование кластеров и распределение запросов по страницам. Такой системный подход сокращает риски пропуска значимых запросов и повышает точность семантического ядра.
Поиск дополнительных запросов через подсказки и похожие формулировки

После первичного сбора запросов важно расширить ядро за счёт подсказок поисковых систем и вариантов с похожей лексикой. Используются инструменты автодополнения в Яндексе и Google, блок «Похожие запросы» и отчёты конкурентов. Эти данные выявляют низкочастотные и длиннохвостые формулировки, которые часто приводят релевантный трафик.
Каждую найденную подсказку проверяют по частотности и сезонности через Wordstat или Keyword Planner. Если формулировка имеет стабильный или растущий спрос, её включают в предварительный список. Важна фильтрация нерелевантных вариантов: проверяется соответствие запросу целевой страницы и соответствие интенту пользователя.
Для систематизации применяются алгоритмы расширения: добавление синонимов, вариаций склонений, географических уточнений и терминов отрасли. Например, запрос «купить велосипед» дополняется «велосипед недорого», «горный велосипед Москва», «электровелосипед для города». Такой подход повышает точность кластеризации и эффективность дальнейшего распределения запросов по страницам.
После формирования расширенного списка проводится этап сверки с уже собранными запросами, удаляются дубли и формируются новые группы. Это позволяет охватить полный спектр пользовательских формулировок и обеспечить семантическое ядро, соответствующее реальному поисковому поведению аудитории.
Отбор запросов по частотности и смысловой нагрузке

После сбора и расширения базы запросов проводится их фильтрация по частотности и смысловой нагрузке. Частотность определяет реальный объём поиска, а смысловая нагрузка показывает, насколько запрос соответствует целям сайта. Исключаются формулировки с нулевой или низкой релевантностью, а также дубли и случайные сочетания слов.
Для наглядности удобно использовать таблицу с ключевыми метриками:
| Запрос | Частотность | Смысловая нагрузка | Тип интента |
|---|---|---|---|
| купить ноутбук | 12 500 | Высокая – целевой продукт | Транзакционный |
| как выбрать ноутбук | 3 800 | Средняя – подготовка к покупке | Информационный |
| ремонт ноутбука | 1 200 | Высокая – конкретная потребность | Транзакционный |
| ноутбук дешево | 2 400 | Высокая – коммерческий интерес | Транзакционный |
Запросы с высокой смысловой нагрузкой распределяются по приоритетам для каждой страницы. Низкочастотные, но точные формулировки включаются для увеличения охвата длиннохвостыми запросами. Такой отбор формирует ядро, где каждая фраза напрямую влияет на привлечение целевой аудитории и эффективность SEO.
Исключение лишних, пересекающихся и нерелевантных запросов
После первичного отбора и расширения семантического ядра проводится чистка запросов. Цель – удалить дубли, пересечения между кластерами и формулировки, не соответствующие тематике сайта. Это повышает точность распределения запросов по страницам и предотвращает внутреннюю конкуренцию за позиции в поиске.
Алгоритм очистки включает несколько шагов:
- Идентификация дубликатов и очень близких по смыслу формулировок. Например, «купить смартфон» и «смартфон купить» объединяются в одну запись с сохранением частотности.
- Проверка соответствия запросов целям страниц. Запросы, не относящиеся к предлагаемым товарам, услугам или контенту, исключаются.
- Анализ пересечений между кластерами. Если один запрос подходит для нескольких разделов, выбирается наиболее релевантный, остальные перенаправляются или удаляются.
- Фильтрация низкочастотных или случайных формулировок без целевого интента, которые не принесут трафика или конверсий.
Рекомендуется использовать таблицы для визуального контроля:
- Колонка с запросом
- Частотность
- Тип интента
- Примечания: удаление, объединение, перераспределение
Регулярная проверка на пересечения и нерелевантность поддерживает актуальность ядра при добавлении новых страниц и корректировке структуры сайта. Это обеспечивает точное соответствие запросов фактическим целям и повышает эффективность продвижения.
Разделение запросов по страницам и типам контента
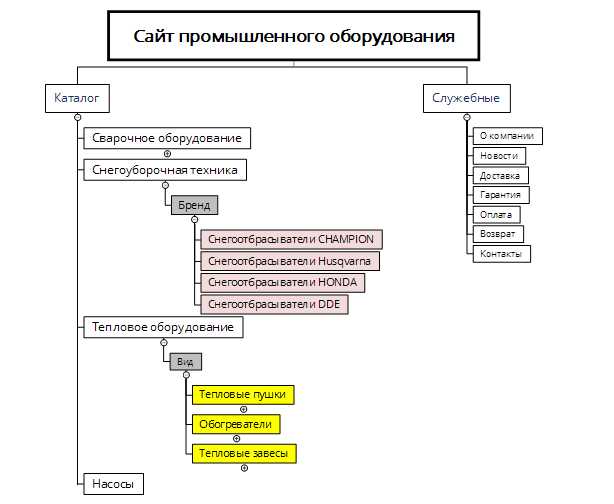
После очистки и фильтрации запросов формируется этап распределения по страницам и типам контента. Цель – привязать каждую поисковую формулировку к конкретной странице, обеспечивая максимальную релевантность и улучшая поведенческие показатели.
Распределение проводится по алгоритму:
- Классификация запросов по типу интента:
- Транзакционные – для страниц с товаром, услугой или формой заявки.
- Информационные – для статей, инструкций, обзоров.
- Навигационные – для категорий, разделов сайта, конкретных брендов.
- Привязка к существующим страницам:
- Сопоставление запроса с тематикой страницы.
- Выбор страницы с максимально подходящей структурой и контентом.
- Создание новых страниц при необходимости:
- Если запрос не покрывается существующими разделами, планируется отдельная страница.
- Определяется тип контента: статья, лендинг, категория, FAQ.
- Формирование кластеров для групп похожих запросов:
- Объединение длиннохвостых и низкочастотных формулировок в один кластер.
- Назначение основного запроса для каждой страницы.
В результате формируется карта соответствия запросов страницам и типам контента, которая служит основой для контент-плана, SEO-оптимизации и дальнейшего расширения ядра без дублирования усилий.
Оценка готовности семантического ядра для работы с сайтом
После распределения запросов по страницам и типам контента необходимо проверить полноту и качество семантического ядра. Основные критерии готовности включают:
- Полнота покрытия: каждый ключевой продукт, услуга или тема сайта должны иметь связанные запросы. Отсутствие запросов для важного раздела указывает на необходимость доработки.
- Соответствие интенту: для каждой страницы запросы должны отражать реальные действия пользователя – покупка, изучение информации, навигация по разделам.
- Чистота данных: исключены дубли, нерелевантные и пересекающиеся формулировки, минимизировано пересечение кластеров.
- Баланс частотности: ядро содержит как высокочастотные, так и низкочастотные запросы, что обеспечивает стабильный трафик и охват длиннохвостых формулировок.
- Готовность к интеграции: каждая группа запросов привязана к странице и типу контента, есть карта распределения для SEO и контент-плана.
Рекомендуется провести контрольную проверку через таблицу или визуальную карту, где отображены все кластеры, страницы и типы интента. Если выявлены пробелы или несоответствия, ядро корректируется до полного соответствия структуре сайта и целям продвижения. Только после этого семантическое ядро считается готовым к использованию в работе с сайтом.
Вопрос-ответ:
Что такое семантическое ядро сайта и зачем оно нужно?
Семантическое ядро — это набор поисковых запросов, по которым пользователи находят сайт. Оно отражает реальный интерес аудитории и помогает правильно структурировать страницы, распределять контент и формировать целевую аудиторию. Без ядра сложно создать релевантный контент и настроить продвижение.
Какие источники использовать для сбора поисковых запросов?
Основные источники: поисковые подсказки Яндекса и Google, отчёты Wordstat и Keyword Planner, Google Search Console для текущих показов сайта, а также данные конкурентов. Использование всех этих источников позволяет собрать разнообразные формулировки и выявить востребованные темы.
Как правильно группировать запросы по страницам сайта?
Запросы группируются по типу интента: транзакционные, информационные и навигационные. Каждая группа привязывается к странице с соответствующим контентом. При необходимости создаются новые страницы для запросов, которые не покрываются существующими разделами. Это помогает избежать дублирования и повысить релевантность страниц.
Каким образом отбираются запросы по частотности и смысловой нагрузке?
Сначала оценивается частотность каждого запроса с помощью инструментов аналитики. Затем проверяется смысловая нагрузка: насколько запрос соответствует продуктам, услугам или информации на сайте. Исключаются дубли, нерелевантные формулировки и низкочастотные случайные сочетания слов, а точные длиннохвостые запросы включаются для расширения охвата.
Как понять, что семантическое ядро готово к использованию на сайте?
Готовое ядро должно полностью покрывать все темы сайта, содержать запросы с разным интентом и частотностью, быть очищенным от дубликатов и нерелевантных формулировок, а также иметь распределение по страницам и типам контента. Проверка через таблицу или карту кластеров позволяет убедиться, что каждый запрос связан с целевой страницей и может быть использован для оптимизации.
Как правильно разделить поисковые запросы на кластеры для сайта?
Разделение запросов проводится по типу пользовательского интента: транзакционные, информационные и навигационные. Каждая группа привязывается к конкретной странице или разделу сайта. Длиннохвостые и низкочастотные запросы объединяются в кластеры для увеличения охвата без создания лишних страниц. Такой подход позволяет избежать дублирования контента и повысить релевантность страниц.
Какие ошибки чаще всего допускают при формировании семантического ядра?
Частые ошибки включают сбор запросов без учёта интента, игнорирование низкочастотных формулировок, отсутствие фильтрации дублей и нерелевантных фраз. Также встречается неправильное распределение запросов по страницам, что приводит к внутренней конкуренции за позиции в поиске. Чтобы этого избежать, важно проверять каждую группу запросов на соответствие целям сайта и типу контента.