Содержание статьи

ISO 8859 1 (Latin-1) использует 8-битную кодировку, поддерживая 191 печатный символ для западноевропейских языков. В таблице присутствуют латинские буквы верхнего и нижнего регистра, цифры, знаки пунктуации и специальные символы, включая умляуты и акценты. Символы занимают диапазон кодов от 0x00 до 0xFF, что обеспечивает прямое отображение без дополнительных преобразований в средах, ориентированных на западноевропейскую письменность.
При создании веб-страниц рекомендуется указывать charset=ISO-8859-1 в HTML для корректного отображения текста в браузерах. Электронная почта и протоколы передачи данных, использующие Latin-1, сохраняют совместимость с текстами на английском, немецком, французском, испанском и португальском, при этом минимизируя риск искажений символов.
При необходимости преобразования ISO 8859 1 в UTF-8 следует использовать стандартные инструменты конвертации, такие как iconv в PHP, encode(‘utf-8’) в Python или команды системных утилит, чтобы сохранить правильное отображение специальных символов. Проверка текста перед и после конвертации предотвращает появление замещающих символов или некорректных кодов.
В базах данных и текстовых редакторах рекомендуется явное указание кодировки ISO 8859 1 для полей и документов, чтобы исключить несовпадение при импорте и экспорте данных. Для проверки корректности отображения символов можно использовать визуальный контроль и автоматизированные средства анализа байтовых последовательностей.
ISO 8859 1: описание и применение кодировки
ISO 8859 1, или Latin-1, представляет собой 8-битную кодировку, предназначенную для представления символов западноевропейских языков. Она включает латинские буквы верхнего и нижнего регистра, цифры, знаки пунктуации и специальные символы, такие как акценты и умляуты. Диапазон кодов от 0x00 до 0xFF обеспечивает прямую поддержку 191 печатного символа.
Применение ISO 8859 1 актуально для веб-страниц, электронных писем и текстовых документов, где требуется сохранение совместимости с текстами на английском, французском, немецком, испанском и португальском. Для корректного отображения рекомендуется указывать charset=ISO-8859-1 в HTML и настройках почтовых клиентов.
В базах данных поля, содержащие текст на западноевропейских языках, следует создавать с указанием кодировки ISO 8859 1. Это снижает вероятность искажений при импорте или экспорте данных. Для преобразования текста в UTF-8 применяются функции iconv в PHP или encode(‘utf-8’) в Python.
| Диапазон кодов | Тип символов | Применение |
|---|---|---|
| 0x00–0x1F | Управляющие символы | Служебные функции, форматирование текста |
| 0x20–0x7F | Стандартные латинские символы | Английский текст, цифры, базовая пунктуация |
| 0x80–0x9F | Расширенные управляющие символы | Редко используются, могут вызывать несовместимость |
| 0xA0–0xFF | Специальные символы и буквы с диакритикой | Тексты западноевропейских языков, корректное отображение акцентов |
Перед конвертацией текста из ISO 8859 1 в другую кодировку рекомендуется проверять байтовые последовательности с помощью специализированных утилит, чтобы избежать появления некорректных символов или замещающих знаков. Настройка текстовых редакторов и баз данных на поддержку ISO 8859 1 обеспечивает стабильность отображения и совместимость при обмене данными.
Совместимость ISO 8859 1 с другими кодировками

ISO 8859 1 напрямую совместима с ASCII для диапазона 0x00–0x7F, что обеспечивает корректное отображение стандартных латинских символов и цифр. Диапазон 0xA0–0xFF не входит в ASCII, поэтому при передаче текста в системы, поддерживающие только ASCII, символы с диакритикой и специальные знаки могут быть искажены.
При работе с UTF-8 символы ISO 8859 1 занимают два байта, что требует конвертации. Для перевода рекомендуется использовать функции iconv в PHP или encode(‘utf-8’) в Python. Обратная конвертация из UTF-8 в ISO 8859 1 возможна только для символов, включённых в Latin-1; символы вне диапазона будут заменены на замещающие или удалены.
Совместимость с Windows-1252 высокая, так как эта кодировка расширяет ISO 8859 1, добавляя несколько графических символов и знаков валют. При миграции текстов между этими кодировками стоит учитывать различия в диапазоне 0x80–0x9F, где Windows-1252 содержит отображаемые символы, а ISO 8859 1 – управляющие.
Для веб-приложений рекомендуется проверять кодировку загружаемых данных и явно указывать charset в HTTP-заголовках и HTML. Это предотвращает появление некорректных символов при смешанном использовании ISO 8859 1 и UTF-8, особенно в многоязычных проектах.
Поддержка символов латиницы и специальных знаков

ISO 8859 1 охватывает полный набор латинских букв для западноевропейских языков, включая буквы с диакритикой и умляуты. Диапазон символов разбит на стандартные ASCII-символы и расширенные знаки:
- Диапазон 0x20–0x7F: латинский алфавит верхнего и нижнего регистра, цифры, базовая пунктуация.
- Диапазон 0xA0–0xFF: специальные символы, буквы с акцентами, умляуты, знаки валют, дроби и математические символы.
Для правильного отображения текста с диакритикой следует убедиться, что используемые шрифты поддерживают весь набор символов Latin-1. При работе с текстовыми файлами и базами данных рекомендуется:
- Указывать кодировку ISO 8859 1 при сохранении файлов.
- Проверять совместимость с системами, использующими UTF-8, и выполнять конвертацию через iconv или аналогичные инструменты.
- Использовать функции проверки наличия символов в диапазоне 0xA0–0xFF, чтобы предотвратить ошибки отображения в приложениях, не поддерживающих расширенные знаки.
Поддержка специальных символов в ISO 8859 1 позволяет корректно отображать тексты на английском, французском, немецком, испанском и португальском языках без дополнительных библиотек или расширений.
Использование ISO 8859 1 в веб-разработке

ISO 8859 1 применяется в веб-разработке для корректного отображения текстов на западноевропейских языках. Для HTML-документов рекомендуется указывать кодировку с помощью мета-тега: <meta charset=»ISO-8859-1″>. Это гарантирует правильное отображение букв с диакритикой и специальных символов в браузерах.
При работе с сервером важно настроить HTTP-заголовки Content-Type с указанием charset=ISO-8859-1. Это предотвращает некорректное отображение текста при передаче данных между сервером и клиентом.
Для форм ввода и обработки пользовательских данных необходимо проверять, что отправляемый текст соответствует диапазону ISO 8859 1. Символы вне диапазона 0x00–0xFF могут приводить к замещающим символам или ошибкам при сохранении в базу данных.
При интеграции с JavaScript и сторонними библиотеками стоит учитывать, что многие современные функции по умолчанию используют UTF-8. В таких случаях требуется конвертация текста из ISO 8859 1 с помощью функций TextEncoder или серверных инструментов, чтобы сохранить корректное отображение всех символов.
Настройка текстовых редакторов для ISO 8859 1

Для работы с ISO 8859 1 необходимо установить кодировку документа в настройках текстового редактора. В большинстве редакторов, таких как Notepad++, Sublime Text или Visual Studio Code, это делается через меню Encoding с выбором ISO-8859-1 или Latin-1.
При создании новых файлов рекомендуется сразу указывать кодировку ISO 8859 1, чтобы избежать искажения символов с диакритикой при сохранении. Для существующих файлов следует использовать функцию конвертации кодировки редактора, проверяя корректность отображения всех специальных символов.
Для работы с проектами, где смешаны UTF-8 и ISO 8859 1, полезно включить отображение скрытых символов и контроль байтового диапазона, чтобы выявить символы, несовместимые с Latin-1. Это особенно важно при подготовке текстов для веб-страниц, баз данных и электронных писем.
Некоторые редакторы поддерживают автоматическое определение кодировки при открытии файла. Рекомендуется отключать эту функцию для проектов с ISO 8859 1, чтобы избежать неправильной интерпретации символов и замены их на некорректные при сохранении.
Проблемы при обмене данными между кодировками
При передаче текста между системами с разными кодировками возникают искажения символов. ISO 8859 1 поддерживает диапазон 0x00–0xFF, и символы за его пределами при конвертации в Latin-1 заменяются на замещающие знаки или теряются.
Особенно часто возникают ошибки при обмене с UTF-8. Символы ISO 8859 1, содержащие диакритические знаки, занимают два байта в UTF-8. При некорректной интерпретации текста появляются «кракозябры» или неправильные символы. Для предотвращения ошибок следует использовать функции конвертации, такие как iconv в PHP или encode/decode в Python.
Проблемы могут возникать и при работе с Windows-1252, где диапазон 0x80–0x9F содержит графические символы, отсутствующие в ISO 8859 1. При миграции текстов важно проверять каждый символ на соответствие Latin-1, чтобы исключить искажения.
Для корректного обмена данными рекомендуется:
- Явно указывать кодировку при сохранении и загрузке файлов.
- Проверять текст на наличие символов вне диапазона ISO 8859 1 перед конвертацией.
- Использовать серверные и клиентские функции для безопасного преобразования между кодировками.
Конвертация текстов из ISO 8859 1 в UTF-8
ISO 8859 1 использует 8-битные коды символов, а UTF-8 применяет переменное количество байтов. Для корректного преобразования необходимо использовать функции, которые учитывают расширенные символы Latin-1, чтобы сохранить диакритические знаки и специальные символы.
В PHP применяется функция iconv(‘ISO-8859-1’, ‘UTF-8′, $text’), которая преобразует текст и сохраняет все символы в допустимом диапазоне UTF-8. В Python используется text.encode(‘ISO-8859-1’).decode(‘utf-8’) или библиотека codecs для последовательного преобразования.
Перед конвертацией рекомендуется проверить текст на наличие символов из диапазона 0x80–0x9F, так как при переносе между ISO 8859 1 и Windows-1252 они могут отличаться. Это предотвращает появление некорректных знаков или «кракозябр».
Для больших файлов и баз данных лучше выполнять пакетную конвертацию с контролем ошибок и логированием, чтобы выявлять строки, содержащие символы вне диапазона ISO 8859 1. После преобразования важно проверить отображение текста в конечной системе или приложении.
Применение ISO 8859 1 в базах данных
ISO 8859 1 используется в базах данных для хранения текстов на западноевропейских языках. При создании таблиц рекомендуется явно указывать кодировку для текстовых полей, чтобы предотвратить искажения при вставке или извлечении данных.
- В MySQL для поля типа CHAR или VARCHAR задается кодировка latin1 с collation latin1_swedish_ci по умолчанию.
- В PostgreSQL текстовые поля могут хранить ISO 8859 1, если база настроена с соответствующей локалью, например en_US.ISO-8859-1.
- При миграции из UTF-8 в ISO 8859 1 следует проверять символы на соответствие диапазону 0x00–0xFF, чтобы избежать замещающих знаков.
Для корректной работы с базой данных важно:
- Явно указывать кодировку при подключении к базе через драйвер или библиотеку.
- Проверять текст перед вставкой на наличие символов, отсутствующих в Latin-1.
- Использовать конвертацию через iconv или встроенные функции СУБД при необходимости перевода текстов в UTF-8 или обратно.
- Включать логирование ошибок при вставке данных с неподдерживаемыми символами.
Следование этим рекомендациям обеспечивает стабильное хранение и извлечение текстов на западноевропейских языках без искажения символов и потери информации.
Проверка корректности отображения символов
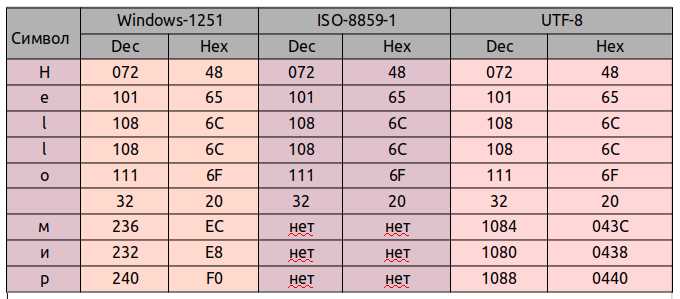
Проверка текста на соответствие ISO 8859 1 позволяет выявить символы, которые не входят в диапазон 0x00–0xFF и могут вызвать искажения при отображении или сохранении. Особенно важно контролировать диакритические знаки и специальные символы.
Для визуальной проверки рекомендуется создавать таблицу с критическими символами и их кодами, чтобы сравнивать отображение в разных приложениях:
| Символ | Код ISO 8859 1 | Диапазон | Примечание |
|---|---|---|---|
| é | 0xE9 | Расширенный | Французская буква с акцентом |
| ñ | 0xF1 | Расширенный | Испанская буква с тильдой |
| € | не входит | – | Знак евро отсутствует в ISO 8859 1 |
| Ü | 0xDC | Расширенный | Немецкая буква с умляутом |
Для автоматической проверки текста используют скрипты, которые анализируют байтовые значения и выявляют символы вне диапазона ISO 8859 1. После выявления проблемных символов рекомендуется либо заменить их на допустимые, либо выполнить конвертацию текста в UTF-8 с сохранением корректного отображения.
Вопрос-ответ:
Что такое ISO 8859 1 и для каких языков она предназначена?
ISO 8859 1, также известная как Latin-1, представляет собой 8-битную кодировку, предназначенную для отображения текстов на западноевропейских языках, включая английский, французский, немецкий, испанский и португальский. Она поддерживает латинские буквы верхнего и нижнего регистра, цифры, знаки пунктуации и специальные символы с диакритикой.
В чем разница между ISO 8859 1 и UTF-8?
ISO 8859 1 использует фиксированную 8-битную таблицу символов с диапазоном 0x00–0xFF, что позволяет отображать только ограниченный набор символов. UTF-8 применяет переменное количество байтов для каждого символа и поддерживает все языки мира, включая восточноевропейские и азиатские. При конвертации текста из ISO 8859 1 в UTF-8 необходимо учитывать диакритические символы, чтобы они отображались корректно.
Как настроить веб-страницу для корректного отображения ISO 8859 1?
Для HTML-документов следует указывать кодировку в мета-теге: . Также рекомендуется настраивать HTTP-заголовки Content-Type с параметром charset=ISO-8859-1. Это обеспечивает правильное отображение букв с акцентами и специальных символов в браузерах, исключая появление некорректных знаков.
Какие проблемы возникают при обмене данными между ISO 8859 1 и другими кодировками?
При передаче текста между системами с разными кодировками символы, отсутствующие в ISO 8859 1, заменяются на замещающие знаки или теряются. Наиболее частые ошибки возникают при обмене с UTF-8 и Windows-1252, особенно в диапазоне 0x80–0x9F. Для предотвращения искажений рекомендуется проверять текст на наличие неподдерживаемых символов и использовать функции конвертации, такие как iconv или аналогичные инструменты.
Как использовать ISO 8859 1 в базах данных?
ISO 8859 1 применяют для хранения текстов на западноевропейских языках. В MySQL текстовые поля задаются с кодировкой latin1 и collation latin1_swedish_ci. В PostgreSQL используется локаль, поддерживающая ISO-8859-1, например en_US.ISO-8859-1. Перед вставкой данных следует проверять текст на символы вне диапазона 0x00–0xFF и при необходимости выполнять конвертацию, чтобы избежать искажений при хранении и извлечении информации.
Как проверить, что текст корректно отображается в ISO 8859 1?
Для проверки корректности отображения текста в ISO 8859 1 необходимо убедиться, что все символы находятся в диапазоне 0x00–0xFF. Для этого можно использовать визуальный контроль, сравнивая текст в разных редакторах, и автоматические скрипты, которые анализируют байтовые значения. Особое внимание следует уделить символам с диакритикой и знакам из диапазона 0x80–0x9F, так как они могут отображаться по-разному в Windows-1252 и других кодировках. При выявлении несовместимых символов их можно заменить на допустимые или выполнить конвертацию текста в UTF-8 с сохранением всех корректных знаков.