Содержание статьи

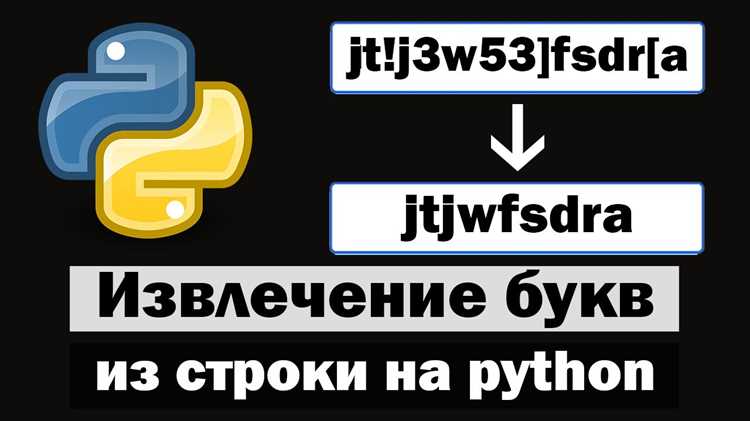
При обработке текстов часто требуется оставить только буквы, удалив цифры, знаки пунктуации и другие символы. Такая очистка полезна при анализе данных, подготовке текстов к машинному обучению или нормализации пользовательского ввода.
В Python задачу можно решить несколькими способами: через регулярные выражения, использование методов строк и функций проверки символов. Каждый из них подходит для разных задач – от фильтрации коротких строк до работы с большими текстовыми файлами.
Особое внимание стоит уделить обработке русского и латинского алфавитов. При неправильной настройке шаблонов регулярных выражений часть символов может быть удалена ошибочно. Поэтому важно понимать, как задать диапазоны букв в Unicode и проверить результат выполнения на тестовых данных.
Также полезно сравнить производительность разных подходов, чтобы выбрать оптимальный вариант для конкретных объёмов данных и форматов входных файлов.
Использование регулярных выражений для фильтрации строк
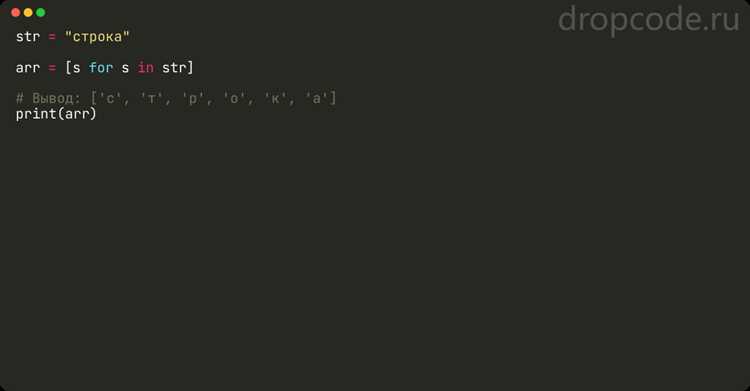
Регулярные выражения позволяют быстро удалить из строки все символы, кроме букв. Для этого используется модуль re, входящий в стандартную библиотеку Python. Основной приём – поиск и замена символов, не относящихся к алфавиту.
Базовый пример: re.sub(r'[^A-Za-zА-Яа-я]’, », text). Выражение в квадратных скобках определяет диапазоны допустимых символов – латиницу и кириллицу. Символ ^ означает отрицание, поэтому замена удаляет всё, что не является буквой.
Если нужно сохранить пробелы между словами, шаблон можно изменить: re.sub(r'[^A-Za-zА-Яа-я ]’, », text). Это удобно при обработке предложений, когда важно не объединять слова.
Для работы с другими языками и алфавитами лучше использовать флаг re.UNICODE, который учитывает национальные символы. Например: re.sub(r'[^\\p{L}]’, », text, flags=re.UNICODE) при использовании библиотеки regex, поддерживающей категории Unicode.
Перед применением регулярных выражений рекомендуется протестировать шаблон на небольших выборках данных. Это помогает убедиться, что удаляются только ненужные символы, а буквы из разных алфавитов сохраняются корректно.
Удаление небуквенных символов через метод isalpha()
Метод isalpha() проверяет, состоит ли символ только из букв. Его можно использовать для фильтрации текста без подключения дополнительных модулей. Подход подходит для коротких строк и простых задач по очистке данных.
Пример кода: ».join(ch for ch in text if ch.isalpha()). Здесь генератор проходит по каждому символу строки и добавляет его в результат только при условии, что isalpha() возвращает True. В итоге остаются только буквы, включая символы национальных алфавитов, поддерживаемых Unicode.
Чтобы сохранить пробелы между словами, можно добавить проверку: ».join(ch for ch in text if ch.isalpha() or ch == ‘ ‘). Такой вариант удобен для текстов, где важно сохранить структуру предложений.
Метод работает быстро на небольших объёмах данных, но при обработке больших файлов предпочтительнее использовать регулярные выражения, поскольку они выполняются на уровне компилированного шаблона и быстрее справляются с множественными проверками.
При необходимости можно комбинировать isalpha() с другими методами, например, lower() для приведения текста к единому регистру перед анализом.
Работа с кириллическими и латинскими буквами в одной строке
При обработке текстов, где встречаются и русские, и английские символы, важно корректно определить диапазоны букв. Ошибки в регулярных выражениях или фильтрации могут привести к удалению части символов.
Для одновременной поддержки двух алфавитов можно использовать выражение: re.sub(r'[^A-Za-zА-Яа-я]’, », text). Диапазоны A–Z и А–Я включают латиницу и кириллицу, при этом исключаются цифры, пробелы и знаки пунктуации.
Если требуется оставить пробелы между словами, добавляют их в шаблон:
- re.sub(r'[^A-Za-zА-Яа-я ]’, », text) – сохраняет пробелы;
- re.sub(r'[^A-Za-zА-Яа-я\n]’, », text) – сохраняет переходы строк.
Для более точной работы с символами Unicode можно подключить библиотеку regex и использовать категорию \p{L}, которая включает все буквы любого алфавита:
- import regex
- regex.sub(r'[^\p{L}]’, », text)
Такой подход удобен, если данные содержат смешанные языки, например имена пользователей или технические термины. При необходимости можно добавить фильтрацию по регистру или нормализацию текста с помощью модуля unicodedata.
Очистка текстовых данных в списках и словарях
При работе с коллекциями важно применять очистку текста ко всем элементам, не нарушая структуру данных. Для этого удобно использовать генераторы списков и словарные включения, совмещённые с функциями фильтрации.
Пример для списка строк:
cleaned = [re.sub(r'[^A-Za-zА-Яа-я]’, », item) for item in data]. Каждая строка в списке очищается отдельно, а результат сохраняется в новой коллекции. Такой способ подходит для предварительной обработки текстов перед анализом или индексированием.
Для словарей можно использовать словарное включение:
cleaned = {k: re.sub(r'[^A-Za-zА-Яа-я]’, », v) for k, v in data.items()}. Это позволяет удалить лишние символы из значений без изменения ключей. Если нужно фильтровать и ключи, используется аналогичная конструкция с очисткой k.
При очистке больших структур стоит избегать повторных вызовов re.sub() внутри циклов без компиляции шаблона. Оптимальнее предварительно создать объект pattern = re.compile(r'[^A-Za-zА-Яа-я]’) и затем применять pattern.sub(», text) для каждого элемента. Это заметно ускоряет обработку при больших объёмах данных.
При необходимости можно добавить проверку типов, чтобы не вызывать фильтрацию на числовых или пустых элементах: if isinstance(v, str). Это особенно полезно при работе со смешанными структурами, содержащими не только строки.
Удаление лишних символов в файлах и вводе пользователя

Для обработки текстовых файлов удобно использовать стандартные функции чтения и записи. После загрузки содержимого можно применить регулярное выражение для удаления небуквенных символов. Пример:
with open(‘input.txt’, ‘r’, encoding=’utf-8′) as f:
text = f.read()
cleaned = re.sub(r'[^A-Za-zА-Яа-я]’, », text)
with open(‘output.txt’, ‘w’, encoding=’utf-8′) as f:
f.write(cleaned)
Такой подход сохраняет структуру файла и позволяет быстро очищать большие объёмы данных. При необходимости можно добавить фильтрацию пробелов или строковых переводов, изменив шаблон под конкретный формат данных.
Для обработки пользовательского ввода можно использовать встроенную функцию input() и применять фильтрацию сразу после получения данных:
text = input(‘Введите текст: ‘)
filtered = re.sub(r'[^A-Za-zА-Яа-я]’, », text)
print(filtered)
Если ввод содержит смешанные языки, стоит использовать модуль regex с категорией \p{L}, что позволит сохранить буквы любого алфавита. Это полезно при создании интерфейсов, где пользователи вводят имена или комментарии на разных языках.
При работе с большими файлами рекомендуется читать и обрабатывать текст построчно, чтобы снизить нагрузку на память: for line in f:. Такой способ обеспечивает стабильную работу даже при обработке гигабайтных данных.
Сравнение разных способов удаления символов по скорости выполнения
Существует несколько подходов к удалению небуквенных символов: использование регулярных выражений, метода isalpha() и генераторов списков. Каждый из них имеет особенности по скорости выполнения на разных объёмах данных.
Регулярные выражения подходят для больших текстов, особенно при компиляции шаблона через re.compile(). Компилированный объект выполняется быстрее, чем повторный вызов re.sub() без компиляции, особенно при обработке миллионов символов.
Метод isalpha() с генератором строк работает быстрее на коротких строках и при фильтрации небольших списков. Его преимущество – отсутствие необходимости подключения дополнительных модулей и высокая читаемость кода.
Для очень больших текстов оптимально использовать комбинированный подход: чтение файла построчно, компиляция регулярного выражения и применение его к каждой строке. Такой метод экономит память и ускоряет обработку по сравнению с обработкой всего файла целиком через генератор списков.
При тестировании производительности рекомендуется использовать модуль timeit, чтобы замерить реальные затраты времени для каждого метода. На практике регулярные выражения выигрывают при обработке свыше 105 символов, а isalpha() лучше для интерактивного ввода и небольших текстовых блоков.
Вопрос-ответ:
Как удалить из строки все символы, кроме букв, с помощью регулярных выражений?
Для удаления всех небуквенных символов в Python используется модуль re. Простейший способ: re.sub(r'[^A-Za-zА-Яа-я]’, », text). Выражение в квадратных скобках задаёт диапазоны латинских и кириллических букв, а символ ^ указывает на отрицание, поэтому удаляются все символы, не являющиеся буквами.
Можно ли сохранить пробелы между словами при удалении лишних символов?
Да, пробелы можно оставить, изменив шаблон регулярного выражения: re.sub(r'[^A-Za-zА-Яа-я ]’, », text). Пробел добавляется в диапазон разрешённых символов, что позволяет сохранить разбиение на слова при фильтрации текста.
В чём разница между использованием isalpha() и регулярных выражений для очистки строки?
Метод isalpha() проверяет каждый символ отдельно и подходит для коротких строк и интерактивного ввода: ».join(ch for ch in text if ch.isalpha()). Регулярные выражения лучше работают с большими объёмами данных и позволяют задавать сложные шаблоны, включая сохранение пробелов или символов разных алфавитов.
Как обработать текстовые данные в списках и словарях, чтобы удалить все символы кроме букв?
Для списков используют генераторы: [re.sub(r'[^A-Za-zА-Яа-я]’, », item) for item in data]. Для словарей применяют словарное включение: {k: re.sub(r'[^A-Za-zА-Яа-я]’, », v) for k, v in data.items()}. Такой подход позволяет очистить все элементы коллекции без изменения её структуры.
Как ускорить обработку больших файлов при удалении небуквенных символов?
Рекомендуется читать файл построчно и использовать скомпилированное регулярное выражение: pattern = re.compile(r'[^A-Za-zА-Яа-я]’), затем применять pattern.sub(», line) к каждой строке. Это уменьшает нагрузку на память и ускоряет фильтрацию, особенно на файлах размером несколько сотен мегабайт или гигабайт.