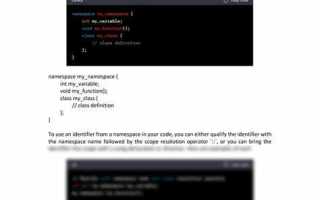
Namespace в C представляет собой механизм, который позволяет группировать идентификаторы – функции, переменные и структуры – под единым именем. Это упрощает управление большим кодом и предотвращает конфликты имен, особенно при работе с несколькими библиотеками.
Создание собственного Namespace выполняется с помощью ключевого слова namespace, за которым следует уникальное имя. Внутри блока можно объявлять любые элементы программы, которые будут доступны только через полное имя Namespace или с использованием директивы using.
Применение Namespace особенно важно при разработке крупных проектов, где пересечение имен неизбежно. Рекомендуется создавать отдельные Namespace для каждой функциональной области и четко документировать их назначение, чтобы другие разработчики могли быстро ориентироваться в коде.
Вложенные Namespace позволяют структурировать код более детально, разделяя логические блоки внутри одной области. Для передачи Namespace между файлами используется директива #include и полное имя идентификатора, что сохраняет изоляцию и предотвращает случайное переопределение.
Что такое Namespace в C и как его использовать

Namespace в C позволяет объединять идентификаторы – функции, переменные, структуры и классы – под уникальным именем, чтобы избежать конфликтов при подключении сторонних библиотек или при работе с большим количеством модулей. Объявление Namespace начинается с ключевого слова namespace, после которого указывается имя и фигурные скобки для блока кода.
Пример создания Namespace:
namespace MathOperations {
int add(int a, int b) {
return a + b;
}
int multiply(int a, int b) {
return a * b;
}
}
Для доступа к элементам Namespace используется полное имя или директива using. Прямое указание полного имени уменьшает вероятность ошибок при совпадении имен:
int result = MathOperations::add(5, 3);
Использование директивы using позволяет упростить запись, но увеличивает риск конфликтов, если в проекте несколько Namespace содержат идентичные имена:
using namespace MathOperations; int result = add(5, 3);
Вложенные Namespace помогают структурировать код по уровням. Рекомендуется использовать их для крупных проектов с модульной архитектурой:
namespace Project {
namespace Utils {
void log(const char* message) {
printf("%s\n", message);
}
}
}
Передача Namespace между файлами обеспечивается через директиву #include и указание полного имени функций или переменных. Это сохраняет изоляцию и упрощает поддержку.
| Компонент | Описание | Пример |
|---|---|---|
| Namespace | Группа идентификаторов, объединённых под уникальным именем | namespace MathOperations { … } |
| Полное имя | Обращение к элементу через имя Namespace | MathOperations::add(5,3) |
| using | Сокращение записи при доступе к Namespace | using namespace MathOperations; |
| Вложенный Namespace | Структурирование кода на нескольких уровнях | namespace Project { namespace Utils { … } } |
Для чего нужен Namespace в C и как он помогает организовать код

Namespace в C служит для изоляции идентификаторов, чтобы функции, переменные и структуры с одинаковыми именами не конфликтовали между собой. Это особенно важно при подключении сторонних библиотек или при работе с проектами, где несколько модулей выполняют похожие задачи.
Использование Namespace позволяет логически группировать элементы кода по функциональности. Например, все математические операции можно поместить в Namespace MathOperations, а работу с файлами – в FileUtils. Такой подход облегчает поиск и поддержку кода.
При организации кода с помощью Namespace рекомендуется придерживаться единого стиля именования и минимизировать вложенность. Каждый Namespace должен содержать четко связанный набор функций и структур, чтобы избежать перегрузки и путаницы при обращении к элементам.
Namespace также упрощает повторное использование кода. Модуль, помещенный в отдельный Namespace, можно подключать в других проектах без риска переопределения существующих идентификаторов. Доступ к элементам можно получить через полное имя Namespace или с помощью директивы using, если требуется краткая запись.
Пример логической группировки с использованием Namespace:
namespace Network {
void connect(const char* address) { ... }
void disconnect() { ... }
}
namespace Database {
void connect(const char* connectionString) { ... }
void query(const char* sql) { ... }
}
Как объявлять собственный Namespace и присваивать ему идентификаторы
Создание собственного Namespace в C начинается с ключевого слова namespace, за которым следует уникальное имя и фигурные скобки для блока кода. Внутри блока можно объявлять функции, переменные, структуры и классы, которые будут изолированы от внешнего пространства имен.
Пример объявления собственного Namespace:
namespace Graphics {
int width = 800;
int height = 600;
void drawPixel(int x, int y, int color) {
// код отрисовки пикселя
}
}
Идентификаторы внутри Namespace должны иметь уникальные имена относительно его содержимого, но могут совпадать с именами в других Namespace. Для доступа к ним используется оператор :: или директива using для сокращения записи.
Рекомендуется давать Namespace имена, отражающие функциональную область, чтобы сразу было понятно, к чему относятся его элементы. Например, для работы с сетью использовать Network, для файловых операций – FileUtils. Это упрощает навигацию и поддержку кода.
Присваивать идентификаторы можно как отдельным элементам, так и целым группам функций:
namespace Audio {
void playSound(const char* file);
void stopSound();
int volumeLevel;
}
Правила вложенных Namespace и их применение на практике

Вложенные Namespace в C позволяют создавать многоуровневую структуру для организации кода. Основное правило – каждый вложенный Namespace должен иметь уникальное имя внутри родительского блока. Это предотвращает конфликты идентификаторов и облегчает навигацию по проекту.
Объявление вложенного Namespace выполняется через последовательное использование ключевого слова namespace внутри другого Namespace:
namespace Project {
namespace Utils {
void logMessage(const char* message) {
printf("%s\n", message);
}
}
}
Для обращения к элементам вложенного Namespace используется цепочка операторов ::, указывающая путь от верхнего уровня до нужного идентификатора:
Project::Utils::logMessage("Запуск программы");
Рекомендуется ограничивать глубину вложенности до 2–3 уровней, чтобы не усложнять чтение кода. Вложенные Namespace удобно использовать для модульного разделения проекта, например, разделяя общие утилиты, работу с сетью и обработку данных в отдельных логических блоках.
Директива using может применяться к конкретному уровню вложенного Namespace, что сокращает запись при частом обращении к его элементам без потери изоляции других уровней:
using namespace Project::Utils;
logMessage("Сообщение без полного пути");
Использование директивы using для сокращения доступа к Namespace
Директива using позволяет упростить обращение к элементам Namespace, устраняя необходимость писать полное имя через оператор :: каждый раз. Она может применяться как к целому Namespace, так и к отдельным идентификаторам.
Пример применения к полному Namespace:
namespace Math {
int add(int a, int b) { return a + b; }
int multiply(int a, int b) { return a * b; }
}
using namespace Math;
int result = add(5, 3); // без указания Math::
Применение директивы к конкретному элементу уменьшает риск конфликта имен, особенно в больших проектах:
using Math::add; int sum = add(10, 7); // multiply по-прежнему требует полного имени Math::multiply
Рекомендации при использовании using: ограничивать её область видимости конкретными блоками или функциями, чтобы избежать случайного переопределения идентификаторов из других Namespace. В глобальной области видимости применять директиву к целому Namespace не рекомендуется при работе с проектами, где используются несколько библиотек с одинаковыми именами функций.
Как избежать конфликтов имен с помощью Namespace

Namespace в C предотвращает пересечение идентификаторов при подключении сторонних библиотек или работе с крупными проектами. Основная идея – изолировать функции, переменные и структуры внутри уникального пространства имен.
Практические рекомендации по использованию Namespace для предотвращения конфликтов:
- Присваивать Namespace имена, отражающие функциональную область: Graphics, Network, Database.
- Разделять элементы проекта на отдельные Namespace по модулям.
- Использовать вложенные Namespace для дополнительных уровней организации, но ограничивать глубину до 2–3 уровней.
- Применять директиву using только в ограниченной области видимости, чтобы не внедрять идентификаторы глобально.
- При необходимости подключать внешние библиотеки использовать их собственные Namespace без объединения с проектными.
Пример изоляции идентификаторов в разных Namespace:
namespace Audio {
void play();
}
namespace Video {
void play();
}
// Использование
Audio::play();
Video::play();
Такой подход исключает конфликты между функциями с одинаковыми именами и сохраняет читабельность кода, позволяя расширять проект без риска случайного переопределения идентификаторов.
Примеры передачи Namespace между файлами проекта
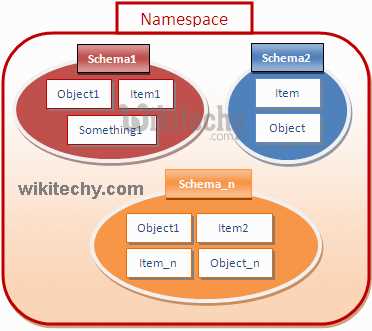
Для передачи Namespace между файлами используется директива #include, которая подключает заголовочный файл с объявлением Namespace. Это позволяет использовать его функции и переменные в других модулях без повторного объявления.
Пример структуры проекта:
// файл math_operations.h
namespace MathOperations {
int add(int a, int b);
int multiply(int a, int b);
}
// файл math_operations.cpp
#include "math_operations.h"
int MathOperations::add(int a, int b) {
return a + b;
}
int MathOperations::multiply(int a, int b) {
return a * b;
}
// файл main.cpp
#include
#include "math_operations.h"
int main() {
int sum = MathOperations::add(5, 3);
int product = MathOperations::multiply(4, 2);
std::cout << sum << " " << product << std::endl;
}
Рекомендации при передаче Namespace между файлами:
- Объявляйте Namespace только в заголовочных файлах, а реализацию функций выносите в отдельные .cpp файлы.
- Используйте уникальные имена Namespace, чтобы избежать конфликтов при подключении сторонних библиотек.
- При необходимости упрощения кода внутри одного файла можно применять директиву using, оставляя глобальную область видимости чистой в остальных файлах.
Такой подход обеспечивает модульность и повторное использование кода без риска столкновения идентификаторов.
Ограничения и ошибки при работе с Namespace в C
В C отсутствует полноценная поддержка namespace, как в C++. Попытка использовать подобные конструкции приводит к ограниченному пространству имен и возможным конфликтам.
Основные ограничения:
- Нет встроенной структуры namespace: в чистом C все идентификаторы находятся в глобальной или локальной области видимости функции.
- Конфликты имен: при использовании одинаковых имен функций или переменных в разных файлах возможны ошибки компоновки.
- Ограниченные способы группировки: можно использовать только префиксы для имитации namespace, что увеличивает длину имен и снижает читаемость.
- Невозможность вложенных namespace: C не поддерживает иерархические области имен.
- Ошибки при подключении заголовочных файлов: повторное включение одного и того же файла без защиты (#ifndef / #define / #endif) вызывает конфликты имен.
Типичные ошибки при работе с "namespace-подобными" решениями:
- Использование одинаковых префиксов в разных модулях, что приводит к пересечению имен.
- Отсутствие защиты заголовочных файлов, что вызывает множественное определение символов при компоновке.
- Переопределение глобальных переменных с одинаковым именем в разных файлах.
- Сложность отладки из-за длинных имен с префиксами, особенно в крупных проектах.
- Попытка эмулировать namespace с помощью макросов, что может привести к неожиданным подстановкам и синтаксическим ошибкам.
Рекомендации для безопасной работы с пространством имен в C:
- Использовать уникальные префиксы для всех глобальных функций и переменных.
- Защищать заголовочные файлы с помощью include guards.
- Ограничивать область видимости переменных до локальных функций или static для файлового уровня.
- Организовывать код в отдельные модули, чтобы минимизировать пересечения имен.
- Документировать соглашения по именованию для командной работы над проектом.
Сравнение Namespace с другими способами организации кода

Namespace в C++ позволяет группировать функции, переменные и классы под уникальным именем, предотвращая конфликты имен. В C отсутствует полноценный namespace, поэтому разработчики используют альтернативные методы организации кода.
Основные способы и их характеристики:
- Префиксы для имен: добавление уникального префикса к именам функций и переменных (например, mod1_init(), mod2_init()). Эффективно предотвращает конфликты, но увеличивает длину имен и снижает читаемость.
- Файловая структура: разделение кода на отдельные файлы и модули. Использование
staticдля функций и переменных ограничивает видимость на уровне файла. Подходит для проектов с небольшим числом пересекающихся имен, но требует строгого контроля include-файлов. - Структуры и typedef: объединение связанных данных и функций через структуры или typedef. Позволяет логически группировать элементы, но не защищает глобальные функции и переменные от конфликта имен.
- Макросы и инлайн-функции: создают псевдо-namespace через #define или inline-функции. Позволяют группировать функциональность, но повышают риск неожиданных подстановок и ошибок компиляции.
Сравнительные преимущества и недостатки:
- Namespace обеспечивает явную область видимости и уменьшает вероятность конфликтов, чего нельзя достичь простыми префиксами.
- Префиксы просты в реализации в C, но не обеспечивают логической группировки и иерархии.
- Файловая структура и static-функции ограничивают видимость, но не позволяют создавать вложенные области имен.
- Структуры удобны для организации данных, но не решают проблему глобальных функций.
Рекомендации:
- Для проектов на C использовать комбинацию уникальных префиксов и разделения на модули с
static. - Для C++ применять namespace для логической группировки функций и классов, особенно в больших проектах.
- Документировать соглашения по именованию и структуру файлов, чтобы минимизировать пересечения и улучшить читаемость.
Вопрос-ответ:
Что такое Namespace в C и для чего он используется?
Namespace — это способ организации имен функций, переменных и структур, чтобы избежать конфликтов между идентификаторами. В C напрямую namespace отсутствует, поэтому разработчики используют префиксы и модули для имитации подобного разделения.
Какие ограничения есть при работе с namespace в C?
В C нет встроенной поддержки namespace, поэтому все идентификаторы находятся в глобальной области видимости или локальной функции. Использование одинаковых имен в разных файлах может вызвать ошибки компоновки. Для уменьшения риска конфликтов применяются префиксы и static для функций и переменных на уровне файла.
Чем namespace отличается от использования префиксов в C?
Namespace обеспечивает явную область видимости и позволяет создавать вложенные пространства имен. Префиксы просто добавляют уникальные идентификаторы к именам функций или переменных, что снижает вероятность конфликта, но не создаёт отдельной логической области и усложняет читаемость при большом количестве элементов.
Можно ли использовать namespace в проектах на чистом C?
Прямо использовать namespace в чистом C нельзя. Вместо этого применяют комбинацию уникальных префиксов, разделение кода на модули и использование static для локальных функций и переменных, что частично имитирует область видимости namespace.
Какие ошибки чаще всего возникают при попытке организовать namespace в C?
Чаще всего возникают конфликты имен из-за одинаковых префиксов в разных модулях, повторное включение заголовочных файлов без защиты, переопределение глобальных переменных и сложность чтения длинных имен с префиксами. Также использование макросов для имитации namespace может вызвать неожиданные подстановки и синтаксические ошибки.
Как в C можно избежать конфликтов имен без использования namespace?
В C отсутствует встроенная поддержка namespace, поэтому разработчики используют префиксы для функций и переменных, разделяют код на отдельные файлы и применяют ключевое слово static для ограниченной видимости на уровне файла. Такая организация позволяет снизить риск пересечения идентификаторов и поддерживать структуру проекта. Кроме того, защитные конструкции заголовочных файлов (#ifndef, #define, #endif) предотвращают повторное включение и ошибки компоновки.