Содержание статьи

Таблица в базе данных представляет собой структурированное хранилище информации, организованное в строки и столбцы. Каждый столбец хранит данные одного типа – например, числа, текст или дату, а каждая строка соответствует отдельной записи. Такой подход позволяет быстро находить нужные данные и поддерживать их целостность.
Для идентификации записей в таблице используют первичные ключи, которые гарантируют уникальность каждой строки. Индексы ускоряют поиск и сортировку информации, особенно при работе с большими объемами данных, достигающими миллионов записей. Правильная настройка индексов снижает нагрузку на сервер и ускоряет выполнение запросов.
Таблицы могут быть связаны между собой через внешние ключи, что позволяет строить взаимосвязанные структуры и исключать дублирование информации. Например, таблица заказов может ссылаться на таблицу клиентов, обеспечивая прямую связь между покупками и их владельцами.
Практическое управление таблицей включает добавление, обновление и удаление записей. Использование ограничений на столбцы, таких как NOT NULL или UNIQUE, помогает поддерживать корректность данных. Регулярное резервное копирование таблиц предотвращает потерю информации при сбоях системы.
Для анализа информации таблицы можно фильтровать, группировать и сортировать данные с помощью запросов. Это позволяет получать отчеты, выявлять закономерности и принимать решения на основе точных показателей, без необходимости обрабатывать данные вручную.
Как устроена таблица и какие типы данных она хранит
Таблица в базе данных состоит из столбцов и строк. Столбцы определяют структуру и тип информации, которую можно хранить, а строки содержат конкретные записи. Каждый столбец имеет уникальное имя и заранее заданный тип данных, который ограничивает формат вводимой информации.
Основные типы данных включают целые числа (INT) для подсчета или идентификаторов, числа с плавающей запятой (FLOAT, DOUBLE) для финансовых и научных расчетов, строки (CHAR, VARCHAR) для текстовых данных, а также DATE и TIMESTAMP для работы с датами и временем. Для логических значений используется BOOLEAN, а для больших бинарных объектов – BLOB.
Выбор правильного типа данных влияет на производительность и хранение информации. Например, для столбца с возрастом лучше использовать SMALLINT, чтобы экономить память, а для описаний товаров – VARCHAR с ограничением длины, чтобы ускорить поиск и сортировку. Неверный выбор типа может привести к ошибкам при обработке данных или увеличению объема хранилища.
Каждый столбец может иметь дополнительные ограничения: NOT NULL запрещает пустые значения, UNIQUE гарантирует уникальность, а DEFAULT задает значение по умолчанию. Эти ограничения помогают поддерживать целостность данных и предотвращают некорректные записи.
Правильная организация таблицы с четким распределением типов данных упрощает построение запросов, связывание таблиц и анализ информации, особенно при работе с большими и сложными базами данных.
Как создаются строки и столбцы в таблице
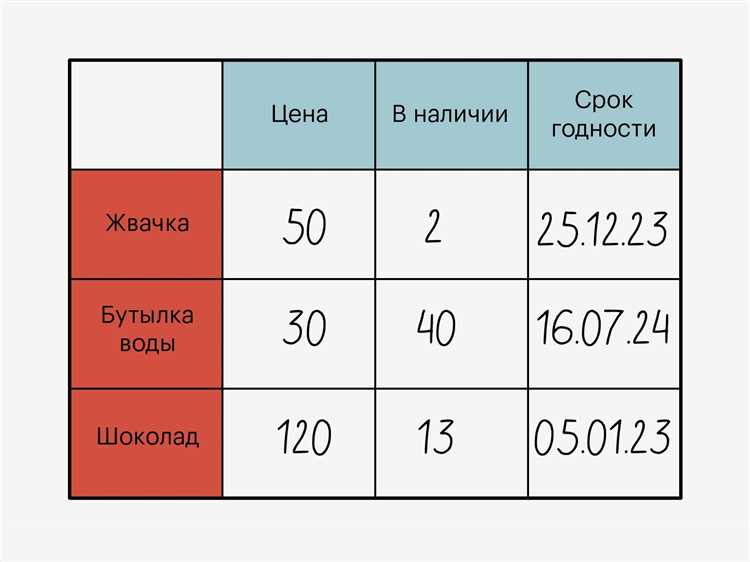
Столбцы создаются при определении структуры таблицы с указанием имени и типа данных. Для числовых значений выбирают INT, SMALLINT, FLOAT, для текстовых – CHAR или VARCHAR, а для дат и времени – DATE, TIMESTAMP. Каждый столбец может иметь ограничения, такие как NOT NULL, UNIQUE или DEFAULT, чтобы контролировать допустимые значения.
Строки добавляются как отдельные записи, каждая из которых заполняет значения во всех столбцах. Используют команды типа INSERT INTO, указывая конкретные значения для каждого столбца. Если столбец имеет DEFAULT, его значение можно опустить, и база автоматически подставит заданное значение.
При создании таблицы важно планировать порядок и типы столбцов в зависимости от задач. Часто идентификаторы помещают в первые столбцы для удобства индексации, а редко изменяемые текстовые поля – в конец, чтобы ускорить выборки. Такой подход снижает нагрузку при обработке больших объемов данных.
При работе со строками следует учитывать ограничения целостности. Например, если столбец является первичным ключом, база данных не позволит добавить дубликат. При массовом добавлении данных рекомендуется использовать пакетные вставки для ускорения обработки и снижения количества транзакций.
Структурированное создание столбцов и последовательное добавление строк обеспечивает правильное хранение информации, облегчает фильтрацию, сортировку и построение связей с другими таблицами.
Как уникальные ключи и индексы обеспечивают поиск данных
Уникальные ключи, включая первичные и уникальные, обеспечивают однозначную идентификацию каждой строки в таблице. Они позволяют базе данных мгновенно находить запись по значению ключа, исключая необходимость полного перебора всех строк.
Индексы создаются на столбцах, часто используемых в условиях фильтрации или сортировки. Они хранят упорядоченные ссылки на строки и позволяют базе данных быстро определять местоположение нужных записей. Без индекса поиск по миллиону строк может занимать секунды, тогда как с индексом – миллисекунды.
Для числовых полей эффективны B-Tree индексы, обеспечивающие быстрый поиск диапазонов, а для точного поиска значений можно применять хэш-индексы. Для текстовых столбцов с большими объемами данных используют полнотекстовые индексы, позволяющие искать слова или фразы внутри текста.
Чрезмерное количество индексов замедляет вставку и обновление данных, поэтому их создают только на столбцах, активно участвующих в запросах. Рекомендуется периодически анализировать и перестраивать индексы, чтобы сохранять высокую производительность при увеличении объема таблицы.
Совместное использование уникальных ключей и индексов гарантирует целостность данных и обеспечивает быстрый доступ к информации, даже при сложных выборках и больших таблицах.
Как таблицы связываются между собой через связи
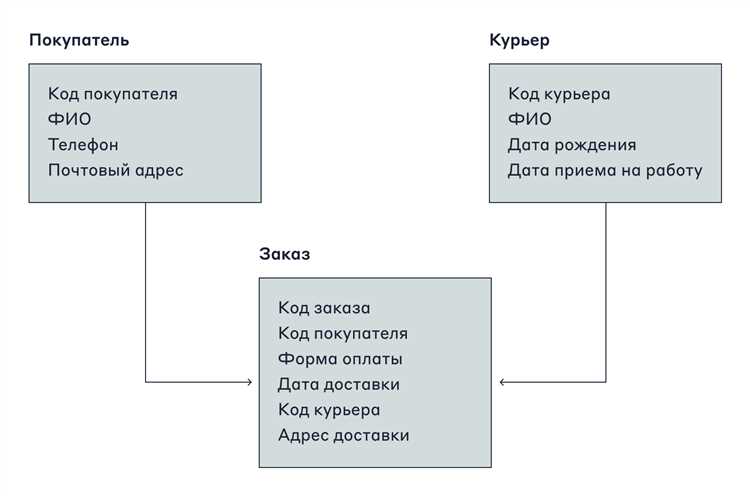
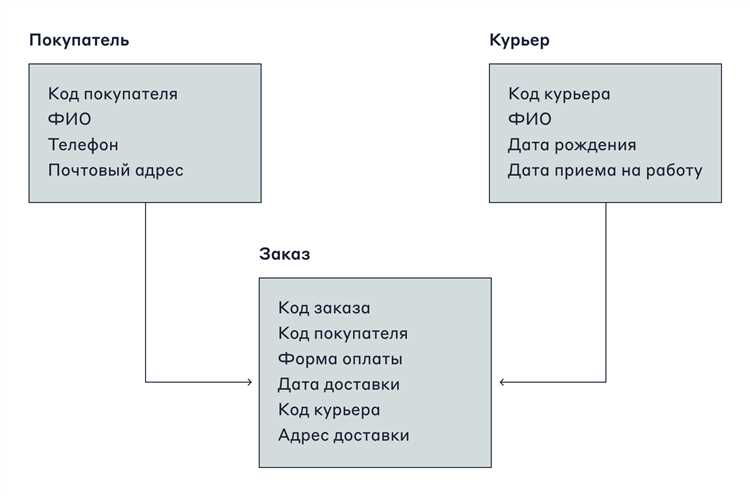
Таблицы в базе данных соединяются с помощью внешних ключей, которые указывают на первичный ключ другой таблицы. Это создает явную связь между записями и позволяет объединять данные из разных таблиц без дублирования информации.
Существует несколько типов связей. Один к одному применяется, когда каждой записи в первой таблице соответствует одна запись во второй. Один ко многим используется для случаев, когда одна запись связана с несколькими записями другой таблицы, например, клиент и его заказы. Многие ко многим реализуется через промежуточную таблицу, содержащую пары идентификаторов связанных записей.
Использование связей позволяет строить JOIN-запросы, которые объединяют данные из нескольких таблиц в один результат. Это облегчает формирование отчетов, анализ информации и построение сложных выборок без повторного хранения одних и тех же данных.
При проектировании связей важно учитывать целостность данных. Определение ON DELETE CASCADE или ON UPDATE CASCADE гарантирует автоматическое обновление или удаление связанных записей, предотвращая «висячие» ссылки и ошибки при изменении данных.
Правильное связывание таблиц снижает объем дублируемой информации, ускоряет запросы и упрощает поддержку базы данных при росте количества записей.
Как добавлять, изменять и удалять записи в таблице
Добавление записей выполняется с помощью команды INSERT INTO, где указываются конкретные значения для каждого столбца. Если столбец имеет DEFAULT значение, его можно опустить, и база подставит заданное значение автоматически.
Изменение существующих записей осуществляется командой UPDATE с указанием условий в WHERE. Без точного фильтра изменения затронут все строки, поэтому рекомендуется всегда использовать условия, ограничивающие диапазон записей. Можно изменять отдельные столбцы или несколько сразу, что ускоряет обновление данных.
Удаление записей выполняется через DELETE FROM с условием WHERE. Для связанных таблиц важно учитывать ограничения внешних ключей: удаление родительской записи может быть запрещено или вызвать каскадное удаление дочерних записей.
При массовых операциях добавления или изменения рекомендуется использовать транзакции, чтобы избежать частичной записи данных в случае ошибки. Это гарантирует целостность таблицы и предотвращает потерю информации.
Регулярная проверка и корректировка записей с соблюдением ограничений и связей между таблицами обеспечивает правильное хранение данных и поддерживает производительность базы при росте объема информации.
Как фильтровать и сортировать данные внутри таблицы
Фильтрация и сортировка данных выполняются с помощью команд SELECT с условиями WHERE и ORDER BY. Фильтры позволяют выбирать только нужные записи по конкретным критериям, а сортировка упорядочивает результат по одному или нескольким столбцам.
Для фильтрации часто используют:
- = и != для точного соответствия или исключения значений;
- <, <=, >, >= для диапазонов чисел или дат;
- LIKE для поиска по шаблону в текстовых полях;
- IN для выбора из набора конкретных значений;
- BETWEEN для диапазонов дат, чисел или строк.
Сортировка выполняется по возрастанию (ASC) или убыванию (DESC). Можно задавать несколько уровней сортировки:
- Сначала по ключевому столбцу, например, дате создания записи;
- Затем по второстепенному, например, по имени клиента для одинаковых дат.
Для ускорения фильтрации и сортировки рекомендуется создавать индексы на столбцах, которые чаще всего участвуют в WHERE и ORDER BY. Это снижает нагрузку на базу при работе с большими таблицами и ускоряет выполнение запросов.
Комбинированное использование фильтров и сортировки позволяет формировать точные выборки и отчеты, избегая обработки ненужных данных вручную и повышая эффективность анализа информации.
Как таблицы используются для отчетов и анализа данных
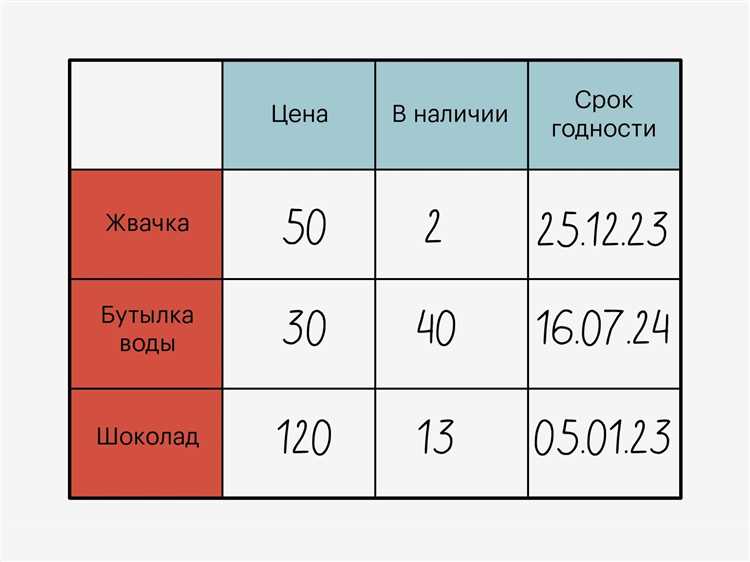
Для построения отчетов применяют:
- Агрегацию данных: подсчет сумм, средних, максимумов и минимумов для числовых столбцов;
- Группировку по ключевым признакам, например, по клиентам, регионам или датам заказов;
- Объединение данных из нескольких таблиц с помощью INNER JOIN, LEFT JOIN или RIGHT JOIN, чтобы получить полную картину;
- Фильтрацию и сортировку, чтобы отчеты содержали только актуальные и упорядоченные данные.
Для анализа используют индексы и первичные ключи, которые ускоряют выборки и расчеты, особенно при работе с миллионами записей. Таблицы позволяют создавать динамические отчеты, где можно менять параметры фильтрации и группировки без дублирования данных.
Систематическое использование таблиц для отчетов и анализа позволяет выявлять закономерности, отслеживать показатели и принимать решения на основе точных данных, исключая ручную обработку и минимизируя ошибки.
Вопрос-ответ:
Что такое первичный ключ в таблице и зачем он нужен?
Первичный ключ — это столбец или набор столбцов, значение которых уникально для каждой строки таблицы. Он используется для однозначной идентификации записи и позволяет быстро находить нужные данные. Кроме того, первичный ключ служит ссылкой для создания связей с другими таблицами через внешние ключи, что помогает поддерживать целостность информации.
Как создать индекс для ускорения поиска в таблице?
Индекс создается на столбце или группе столбцов, которые часто участвуют в фильтрах или сортировке. Он хранит отсортированные указатели на строки, что позволяет базе данных находить нужные записи без полного перебора таблицы. Для числовых данных часто используют B-Tree индексы, для текстовых полей — полнотекстовые. Индексы ускоряют выборки, но создают дополнительную нагрузку при вставке и обновлении записей.
Чем отличаются связи «один к одному» и «один ко многим» в таблицах?
Связь «один к одному» означает, что каждой записи в первой таблице соответствует ровно одна запись во второй. Например, у каждого сотрудника может быть один паспорт. Связь «один ко многим» позволяет одной записи в первой таблице иметь несколько связанных записей во второй, как клиент и его заказы. Выбор типа связи зависит от логики данных и требований к структуре базы.
Как правильно добавлять и обновлять записи, чтобы не нарушить связи между таблицами?
При добавлении записи необходимо проверять, что все значения внешних ключей соответствуют существующим записям в связанных таблицах. При обновлении данных следует учитывать ограничения внешних ключей, например, если столбец связан с другой таблицей, изменение его значения может быть запрещено или потребовать каскадного обновления. Использование транзакций позволяет вносить несколько изменений одновременно и предотвращает частичное внесение данных при ошибках.
Как таблицы используются для построения отчетов с объединением нескольких источников данных?
Для отчетов часто требуется объединять информацию из нескольких таблиц. Это выполняется с помощью JOIN-запросов, которые связывают таблицы через ключи. Можно использовать INNER JOIN для получения только совпадающих записей, LEFT JOIN для сохранения всех строк из основной таблицы и RIGHT JOIN для сохранения всех строк из второй таблицы. После объединения можно фильтровать, группировать и агрегировать данные, создавая отчеты с точными показателями и аналитикой без дублирования информации.