Содержание статьи

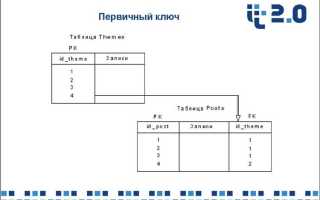
Первичный ключ – это поле или набор полей в таблице, которые однозначно идентифицируют каждую запись. Без корректно определенного первичного ключа невозможно гарантировать уникальность данных, что может привести к дублированию записей и ошибкам при обновлении информации.
При выборе поля для первичного ключа важно учитывать его стабильность: значения не должны изменяться со временем, иначе нарушится целостность связей между таблицами. Часто используют целочисленные идентификаторы с автоинкрементом или UUID, поскольку они гарантируют уникальность без необходимости проверять существующие записи вручную.
Составные первичные ключи применяются, когда уникальность нельзя обеспечить одним полем. В этом случае каждое поле в составе ключа должно быть строго определено и неизменно. Неправильная комбинация полей может создавать коллизии и замедлять работу базы данных.
Создание первичного ключа напрямую влияет на производительность запросов. Индексация ключа позволяет ускорять выборку и соединение таблиц, но неоптимальные типы данных, например длинные текстовые поля, могут существенно замедлить операции. Поэтому важно выбирать компактные и простые форматы.
Понимание роли первичного ключа также критично для работы с внешними ключами. Любая таблица, ссылающаяся на первичный ключ другой таблицы, зависит от его стабильности и уникальности. Нарушение этих принципов приводит к ошибкам ссылочной целостности и проблемам при масштабировании базы.
Что такое первичный ключ и зачем он нужен в таблице

Первичный ключ необходим для построения связей между таблицами через внешние ключи. Когда одна таблица ссылается на другую, она использует первичный ключ как точку привязки, что гарантирует согласованность и целостность данных при изменении или удалении записей.
При проектировании таблицы следует выбирать поле с минимальной длиной и стабильными значениями, чтобы ускорить индексацию и снизить нагрузку на систему. Часто используют числовые идентификаторы с автоинкрементом или UUID, поскольку они исключают коллизии и позволяют быстро выполнять выборки.
Кроме уникальности, первичный ключ обеспечивает основу для оптимизации запросов. Индексация по ключу ускоряет фильтрацию, сортировку и объединение таблиц. Неправильный выбор ключа может замедлить работу базы данных и усложнить поддержание ссылочной целостности.
Выбор подходящего поля для первичного ключа
При выборе поля для первичного ключа важно ориентироваться на его уникальность и стабильность. Значения должны оставаться неизменными на протяжении всего жизненного цикла записи, иначе нарушится целостность ссылок на эту запись в других таблицах.
Оптимально использовать простые типы данных: целые числа или короткие строки фиксированной длины. Длинные текстовые поля или поля, подверженные частым изменениям, замедляют индексацию и усложняют поддержание базы данных.
Для таблиц с большим количеством записей рекомендуется автоинкрементный числовой идентификатор, который гарантирует уникальность без необходимости проверять существующие значения. В распределенных системах часто применяют UUID, чтобы избежать коллизий при параллельных вставках.
Иногда уникальность невозможно обеспечить одним полем. В таких случаях используют составной первичный ключ, объединяя несколько полей. Все поля состава должны быть неизменны и иметь минимальный размер, чтобы не снижать производительность.
Выбор правильного поля напрямую влияет на производительность и целостность данных. Неправильно выбранный ключ может привести к дублированию записей, сложностям при объединении таблиц и замедлению запросов.
Типы данных, подходящие для первичного ключа

Для первичного ключа оптимальны числовые типы данных, такие как INT, BIGINT, так как они занимают мало памяти и быстро индексируются. Использование целочисленных значений с автоинкрементом позволяет гарантировать уникальность каждой записи без ручной проверки.
В распределенных системах или при необходимости глобальной уникальности применяют UUID или CHAR(36). Такие значения создаются автоматически и минимизируют риск коллизий, однако индексирование длинных строк замедляет выборку по сравнению с числами.
Короткие строковые поля, например CHAR(8) или VARCHAR(20), подходят для ключей, если значения строго контролируются и редко изменяются. Важно избегать длинных текстовых полей и полей с часто меняющимися данными, чтобы не нарушить производительность и целостность.
Тип данных ключа влияет на хранение и скорость операций соединения таблиц. Компактные и фиксированные форматы ускоряют поиск и сортировку, тогда как неоптимальные форматы увеличивают нагрузку на базу данных.
Ограничения уникальности и их роль в первичных ключах
Первичный ключ автоматически накладывает ограничение уникальности на выбранное поле или набор полей. Это гарантирует, что каждая запись в таблице имеет уникальный идентификатор, предотвращая дублирование данных.
Роль ограничений уникальности проявляется в нескольких аспектах:
- Целостность данных: запрещает вставку двух записей с одинаковым значением ключа.
- Оптимизация индексации: уникальный ключ создает индекс, ускоряющий выборку и соединение таблиц.
- Согласованность связей: внешние ключи ссылаются на уникальные значения, что исключает ошибки при обновлении или удалении записей.
При проектировании таблицы важно учитывать:
- Не использовать поля с изменяющимися значениями – это нарушает уникальность.
- Компактные и фиксированные типы данных ускоряют проверку ограничений.
- В составных ключах все поля должны быть стабильными и контролируемыми.
Нарушение ограничений уникальности приводит к ошибкам при вставке и потенциально к потере ссылочной целостности в связанных таблицах, поэтому правильная настройка ключа критически важна для работы базы данных.
Использование составного первичного ключа на практике

Составной первичный ключ создается из двух или более полей таблицы для обеспечения уникальности записей, когда одного поля недостаточно. Каждое поле в составе должно быть неизменным и строго определенным, иначе целостность данных нарушится.
Применение составного ключа целесообразно в таблицах со связями многие-ко-многим. Например, таблица заказов и товаров может использовать комбинацию ID_заказа и ID_товара как ключ, чтобы уникально идентифицировать каждую позицию заказа.
При проектировании составного ключа рекомендуется:
- Выбирать поля минимальной длины, чтобы индекс был компактным и запросы выполнялись быстрее.
- Использовать только стабильные значения, которые не будут изменяться после вставки записи.
- Проверять уникальность комбинации перед вставкой, чтобы избежать ошибок нарушения ограничений.
Составные ключи усложняют работу с внешними ключами, поэтому их следует применять только там, где действительно необходима комбинация нескольких полей для однозначной идентификации записи.
Автоинкрементные ключи и их настройка

Автоинкрементные ключи создаются автоматически при добавлении новой записи, увеличивая значение на единицу относительно предыдущей. Они подходят для числовых первичных ключей, когда требуется уникальный идентификатор без ручного контроля.
При настройке автоинкрементного ключа следует учитывать начальное значение и шаг увеличения. Чаще всего используют начальное значение 1 и шаг 1, но при массовых вставках или распределенных системах можно изменять шаг для предотвращения конфликтов.
Важно выбирать подходящий тип данных. INT обеспечивает до 2,1 миллиарда уникальных значений, BIGINT – до 9,2 квинтиллиона. Для таблиц с большим количеством записей рекомендуется BIGINT, чтобы избежать переполнения.
Автоинкрементные ключи легко комбинировать с индексами и внешними ключами, ускоряя соединение таблиц и выборку. Не рекомендуется использовать автоинкремент для полей, которые могут изменяться или дублироваться в других таблицах, чтобы не нарушать ссылочную целостность.
Ошибки при создании первичных ключей и как их избегать

Неправильное определение первичного ключа может привести к дублированию данных, нарушению ссылочной целостности и замедлению работы базы данных. Основные ошибки включают:
- Использование изменяющихся полей, таких как email или телефон, которые могут обновляться.
- Выбор полей с большим размером, например длинных текстовых или бинарных данных, что замедляет индексацию.
- Применение составного ключа без анализа уникальности комбинации полей.
- Игнорирование потенциального переполнения при автоинкрементных ключах.
- Отсутствие индексации или неправильная настройка уникальности.
Чтобы избежать ошибок, рекомендуется:
- Выбирать стабильные, неизменяемые поля для ключа.
- Использовать компактные типы данных, такие как INT или BIGINT.
- Проверять уникальность значений до внедрения ключа и при необходимости применять составной ключ.
- Настраивать автоинкремент с учетом ожидаемого объема данных, чтобы избежать переполнения.
- Создавать индексы и следить за корректностью ссылочной целостности при использовании внешних ключей.
Следование этим рекомендациям минимизирует риски дублирования и ускоряет работу базы данных, обеспечивая надежную структуру для хранения и обработки информации.
Связь первичного ключа с внешними ключами в других таблицах
Первичный ключ служит точкой привязки для внешних ключей в других таблицах. Любая таблица, которая ссылается на первичный ключ, использует его для обеспечения ссылочной целостности, гарантируя, что каждая запись в дочерней таблице соответствует существующей записи в родительской.
При проектировании связей следует учитывать следующие рекомендации:
- Тип данных внешнего ключа должен точно совпадать с типом первичного ключа, чтобы исключить ошибки привязки.
- Нельзя удалять или изменять значения первичного ключа без соответствующей обработки внешних ключей, иначе возникнут ошибки ссылочной целостности.
- Использовать каскадные операции (ON DELETE CASCADE, ON UPDATE CASCADE) только при полной уверенности в логике данных, чтобы автоматические изменения не нарушили бизнес-процессы.
Корректная настройка внешних ключей ускоряет выполнение JOIN-запросов и обеспечивает точность данных при массовых обновлениях и удалениях. Нарушение правил связи между ключами приводит к появлению «висячих» записей и нарушению структуры базы, что затрудняет аналитические и операционные процессы.
Вопрос-ответ:
Почему нельзя использовать изменяемое поле, например email, в качестве первичного ключа?
Использование изменяемого поля нарушает ссылочную целостность: если значение ключа изменится, все таблицы, ссылающиеся на него через внешние ключи, потеряют точность привязки. Это может привести к «висячим» записям и ошибкам при объединении таблиц. Лучший вариант — использовать числовой идентификатор или UUID, которые остаются неизменными.
Как выбрать между автоинкрементным ключом и UUID?
Автоинкрементный ключ удобен для локальных баз с последовательной вставкой записей и небольшой вероятностью конфликтов. Он занимает меньше памяти и быстрее индексируется. UUID подходит для распределенных систем или когда требуется глобальная уникальность, так как исключает пересечения значений при параллельных вставках, хотя индексирование длинных строк может замедлять выборку.
Когда стоит использовать составной первичный ключ?
Составной ключ нужен, если уникальность нельзя обеспечить одним полем. Например, таблица с деталями заказов может использовать комбинацию идентификатора заказа и идентификатора товара. Важно, чтобы все поля состава были стабильными и имели минимальный размер, чтобы не ухудшать производительность базы и корректно работать с внешними ключами.
Как тип данных первичного ключа влияет на производительность базы?
Компактные числовые типы, такие как INT или BIGINT, позволяют быстрее создавать индексы, выполнять сортировку и соединения таблиц. Длинные текстовые поля замедляют индексацию и выборку, увеличивают объем занимаемой памяти и нагрузку на сервер при массовых операциях. Выбор типа данных напрямую отражается на скорости операций и стабильности базы.
Что происходит с внешними ключами, если значение первичного ключа изменяется?
Если первичный ключ изменяется без настройки каскадного обновления, все связанные записи во внешних таблицах теряют точную привязку, что приводит к нарушению ссылочной целостности. При использовании ON UPDATE CASCADE изменения автоматически применяются ко всем связанным записям, но это требует внимательного проектирования, чтобы не нарушить логику работы данных.
Можно ли использовать строковое поле, например имя пользователя, как первичный ключ?
Использовать строковое поле для первичного ключа допустимо, но не всегда удобно. Длинные строки увеличивают размер индекса, замедляют выборку и операции соединения таблиц. Кроме того, имя пользователя может изменяться, что нарушает ссылочную целостность. Для уникальной идентификации лучше выбрать числовой идентификатор или UUID, а строковое поле оставить как уникальное, но не ключевое.
Какие ошибки чаще всего совершают при настройке автоинкрементного ключа?
Типичные ошибки включают выбор слишком маленького типа данных, что может привести к переполнению при большом количестве записей, игнорирование начального значения и шага, что создаёт конфликты при параллельных вставках, и попытку изменять значения ключа вручную. Для избегания проблем рекомендуется использовать тип BIGINT для крупных таблиц, установить подходящий старт и шаг, а редактировать значения только через встроенные механизмы базы.