Содержание статьи

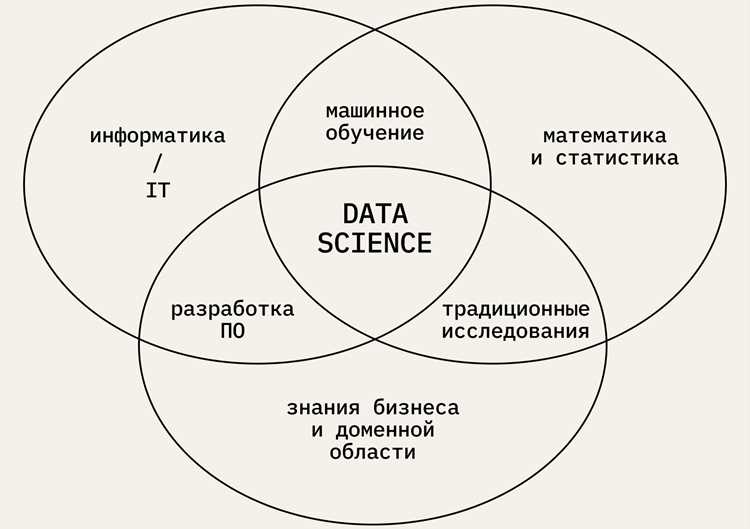
Первые шаги в Data Science требуют понимания того, какие знания действительно нужны. На практике новичкам достаточно освоить базовую статистику, матанализ на уровне производных и интегралов, а также Python. Эти области покрывают большую часть задач, с которыми сталкивается специалист на старте: расчет метрик, обработка данных, подготовка признаков.
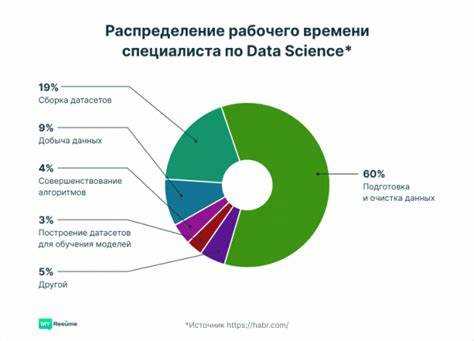
Следующий этап – работа с инструментами. NumPy и Pandas позволяют быстро преобразовывать массивы данных, проверять гипотезы и готовить выборки для моделей. Освоение этих библиотек открывает доступ к разбору реальных датасетов, что помогает понять типичные ошибки в данных, способы их устранения и влияние каждого шага на итоговые результаты.
Для построения моделей достаточно изучить основные алгоритмы: линейную регрессию, логистическую регрессию, деревья решений, градиентный бустинг и kNN. Эти методы покрывают большинство прикладных задач, встречающихся в учебных и тестовых проектах. Практика на реальных данных дает возможность увидеть ограничения каждого алгоритма и подобрать настройки под конкретную задачу.
Определение целей обучения и выбор направления внутри Data Science
Перед началом обучения новичку важно решить, какие задачи он собирается решать: прогнозирование показателей, анализ пользовательского поведения, обработка текстов или работа с изображениями. Это помогает сузить круг навыков и определить, какие библиотеки и алгоритмы потребуется изучить в первую очередь.
Для аналитически ориентированных задач подойдут направления, связанные с продуктовой аналитикой и статистическим моделированием. Они требуют уверенного владения Python, SQL и понимания статистических тестов. Тем, кто хочет строить модели для автоматизации решений, стоит рассматривать машинное обучение с акцентом на методы классификации и регрессии.
Специалистам, интересующимся текстами, подойдет NLP. Здесь важно освоить обработку токенов, векторизацию, модели вроде BERT и методы оценки качества. Для работы с изображениями нужна база по нейронным сетям, сверточным слоям и фреймворкам наподобие PyTorch.
Четко заданная цель снижает объем лишнего материала. Новичок понимает, какие темы изучать дальше, какие инструменты тестировать на практике и какие проекты включать в портфолио, чтобы показать знание выбранного направления.
Подбор базовых курсов по математике, статистике и Python
Для старта в Data Science достаточно освоить темы, которые используются при подготовке признаков и проверке гипотез. Подойдут курсы по матанализу на уровне производных, градиентов и простых оптимизационных методов. Важно закрепить понятия дисперсии, ковариации, распределений и доверительных интервалов – эти элементы применяются почти в каждом проекте.
По статистике удобны программы, включающие разбор A/B-тестов, проверку гипотез и расчёт метрик. Обратите внимание на курсы, где есть практические задания с SQL или Python, поскольку они помогают сразу применять теорию. Выбор стоит делать в пользу материалов, содержащих реальные датасеты, чтобы отработать вычисление статистических показателей.
По Python подойдут обучающие программы, где последовательно разбираются типы данных, функции, работа с файлами, циклы и основы ООП. Желательно, чтобы курс давал практику в NumPy и Pandas, так как эти библиотеки формируют основу обработки данных. Дополнительным плюсом будет модуль по визуализации, позволяющий строить графики для первичного анализа.
Оптимально сочетать теорию и практику: один курс по математике, один по статистике и один по Python обеспечат рабочий базис. Такой набор позволяет быстро перейти к разбору алгоритмов машинного обучения и выполнять простые проекты.
Освоение библиотек NumPy, Pandas и инструментов анализа данных

Работа с данными в Data Science строится на умении быстро преобразовывать массивы, находить ошибки в выборках и готовить таблицы под модели. NumPy и Pandas дают полный набор операций для таких задач, поэтому на начальном этапе важно освоить их на практических примерах.
При изучении NumPy стоит уделить внимание базовым элементам:
- создание массивов и изменение их формы;
- векторные операции и вычисления по оси;
- генерация случайных величин для тестирования кода;
- работа с масками для фильтрации значений.
Pandas позволяет структурировать данные в форматах Series и DataFrame. Полезно отработать следующие приёмы:
- загрузка таблиц из CSV, Excel и SQL;
- очистка пропусков и аномалий;
- группировка и агрегации для расчёта ключевых метрик;
- слияние таблиц разными способами;
- создание новых признаков на основе существующих столбцов.
Помимо обработки данных следует освоить инструменты первичного анализа:
- визуализация распределений и корреляций для проверки предположений о данных;
- построение сводных таблиц для быстрого сравнения групп;
- проверка статистических гипотез в простых кейсах.
Удобнее всего закреплять материал на публичных датасетах: данные по продажам, медицинские таблицы, наборы с Kaggle. Такой подход помогает увидеть реальные проблемы, правильно выбрать методы очистки и сформировать уверенность в работе с массивами любой сложности.
Изучение методов машинного обучения и их практическое применение

На первом этапе полезно освоить алгоритмы, которые чаще всего встречаются в прикладных задачах. Это линейные модели, деревья решений, ансамбли, алгоритмы ближайших соседей и базовые модели кластеризации. Для каждого метода важно понимать входные данные, ограничения и способы проверки качества.
Удобнее всего систематизировать базовые алгоритмы в виде таблицы:
| Алгоритм | Задачи | Основные требования к данным |
|---|---|---|
| Линейная и логистическая регрессия | Прогноз числовых значений, бинарная классификация | Отсутствие сильной мультиколлинеарности, масштабирование признаков |
| Деревья решений | Классификация и регрессия | Минимальная подготовка признаков, устойчивость к выбросам |
| Градиентный бустинг | Сложные задачи прогнозирования | Чистые данные, корректные признаки, контроль переобучения |
| kNN | Классификация без сложной модели | Масштабирование данных, удаление шумовых признаков |
| K-means | Кластеризация и поиск групп | Выбор числа кластеров, нормализация признаков |
Чтобы закрепить материал, достаточно взять один датасет и протестировать несколько моделей. Проект может включать очистку данных, генерацию признаков, подбор гиперпараметров и анализ метрик. Такой подход показывает, как выбор алгоритма влияет на поведение модели и какие ошибки возникают при неверных предположениях о данных.
Для контроля качества подойдут метрики accuracy, precision, recall, RMSE и MAE. Их сравнение позволяет определить, какой алгоритм работает устойчивее на выбранной выборке. Регулярная практика помогает быстрее замечать проблемы в данных и выбирать подходящие методы.
Сбор портфолио: подбор задач, подготовка датасетов и оформление проектов
Для портфолио нужны проекты, показывающие умение работать с данными на всех этапах. Подойдут задачи прогнозирования продаж, классификации клиентов, разбор текстов или анализ логов. Лучше выбирать темы, где можно чётко сформулировать цель и получить измеримый результат.
Если подходящего датасета нет, его можно собрать самостоятельно: выгрузить данные через API, объединить открытые таблицы или сформировать выборку из нескольких источников. Важно сохранять исходный формат данных и фиксировать каждый шаг очистки, чтобы проект был воспроизводим.
Оптимальный набор – 2–3 проекта, различающиеся по типу задачи. Такой комплект демонстрирует владение анализом данных, подготовкой признаков и построением моделей, что помогает выделиться среди начинающих кандидатов.
Подготовка к собеседованиям: разбор типовых задач и вопросов
Для успешного прохождения собеседований важно отработать стандартные типы задач и вопросы, с которыми сталкиваются начинающие data scientist. Их можно разделить на несколько категорий:
- Алгоритмы и структуры данных: списки, словари, деревья, графы. Практика на Python помогает решать задачи по поиску, сортировке и фильтрации данных.
- Статистика и A/B-тестирование: вычисление доверительных интервалов, проверка гипотез, расчёт метрик precision, recall, F1. Важно уметь интерпретировать результаты.
- Машинное обучение: выбор модели, подбор гиперпараметров, анализ метрик RMSE, MAE, ROC-AUC. Нужно показать понимание, когда применять линейную регрессию, деревья или бустинг.
- Обработка данных: очистка пропусков, работа с выбросами, создание признаков и объединение таблиц. Часто дают задачи на реальные датасеты с неполными данными.
Рекомендуется подготовить практические решения в виде ноутбуков или скриптов, чтобы на собеседовании показать ход рассуждений. Полезно:
- Разбирать 5–10 задач по каждому типу алгоритмов и ML-методов.
- Сравнивать несколько моделей на одном датасете и объяснять выбор лучшей.
- Подготовить короткие объяснения статистических тестов и метрик, чтобы отвечать без запинки.
- Решать задачи с реальными данными с Kaggle или открытых источников, чтобы показать навыки практического анализа.
Регулярная практика по этим направлениям позволяет уменьшить время на решение задач, повысить уверенность и продемонстрировать способность анализировать данные от начала до конца.
Вопрос-ответ:
С чего лучше начать обучение, если нет опыта в программировании?
Начать стоит с Python, так как это основной язык для анализа данных. Освойте базовые типы данных, функции, циклы и работу с файлами. Одновременно изучайте простую математику и статистику: среднее, дисперсию, стандартное отклонение, корреляцию. Это создаст базу для дальнейшей работы с библиотеками NumPy и Pandas.
Какие навыки помогут быстрее перейти к реальным проектам?
Для практических проектов важно уметь загружать данные из CSV и баз данных, очищать пропуски и выбросы, объединять таблицы и создавать новые признаки. Владение библиотеками NumPy и Pandas позволит проводить эти операции быстро. Кроме того, базовые навыки визуализации с matplotlib или seaborn помогут анализировать распределения и выявлять закономерности.
Как правильно выбирать задачи для портфолио новичку?
Лучше выбирать задачи, которые позволяют показать весь цикл работы с данными: сбор, очистку, анализ, построение моделей и интерпретацию результатов. Хорошо подходят прогнозирование продаж, классификация клиентов, анализ текстов или кластеризация пользователей. Каждый проект должен иметь понятную цель, измеримые результаты и объяснение методов, которые вы использовали.
Какие темы стоит повторять перед собеседованием на позицию junior data scientist?
Следует пройтись по базовым алгоритмам: линейная и логистическая регрессия, деревья решений, градиентный бустинг, kNN. Также полезно освежить знания по статистике и A/B-тестам, SQL-запросам и обработке данных. Практика на реальных датасетах позволяет быстро отвечать на вопросы по очистке данных, построению моделей и интерпретации метрик.