Содержание статьи

Для сбора сведений с веб-страниц разработчики часто используют связку requests и BeautifulSoup. Такой подход позволяет извлекать текст, ссылки, параметры товаров, данные таблиц и другие элементы, представленные в HTML. Работа с кодом страницы обычно начинается с анализа структуры разметки и выбора конкретных тегов, по которым удобно ориентироваться.
При обращении к сайту через requests важно учитывать ограничения сервера: частоту запросов, необходимость указания корректного заголовка User-Agent, а иногда и обработку cookies. Без этого доступ может быть заблокирован или страница вернёт неполный набор данных. Поэтому перед началом работы проверяют, какие ответы выдаёт сервер при разных условиях и какие заголовки на него влияют.
В BeautifulSoup востребованы методы find, find_all и поиск по CSS-селектору. Они позволяют получать элементы по тегам, классам и атрибутам, что особенно полезно при парсинге каталогов или новостных разделов. После извлечения данных обычно выполняют их приведение к нужному формату: удаление лишних пробелов, конвертацию числовых значений, замену локальных ссылок абсолютными путями.
Результаты парсинга сохраняют в JSON, CSV или передают в базу данных. Такой набор форматов подходит для последующей обработки: аналитики, интеграции с другими системами или автоматизации задач, связанных с обновлением сведений на собственных сервисах.
Настройка окружения и установка библиотек для работы с BeautifulSoup
Для работы с парсингом удобнее создать отдельное виртуальное окружение. В Windows это выполняется командой python -m venv venv, в Linux и macOS – python3 -m venv venv. После создания окружения его активируют: venv\Scripts\activate в Windows или source venv/bin/activate в Linux и macOS. Такое разделение позволяет изолировать зависимости и избежать конфликтов между версиями библиотек.
Основой для получения HTML-кода страницы служит библиотека requests. Она устанавливается командой pip install requests. Важно проверить версию Python: большинство актуальных релизов requests корректно работают начиная с Python 3.7. Для парсинга HTML используется пакет beautifulsoup4, который ставится командой pip install beautifulsoup4. При необходимости более быстрый парсер lxml добавляют через pip install lxml.
После установки рекомендуется выполнить короткий тест: импортировать библиотеки в интерпретаторе и убедиться, что ошибок нет. Например, запустить from bs4 import BeautifulSoup и import requests. Если виртуальное окружение настроено корректно, пакеты подгружаются без предупреждений, что позволяет переходить к загрузке и анализу HTML-кода.
Получение HTML-кода страницы через requests и обработка ошибок сети
Для загрузки HTML-кода используется метод requests.get(). Чтобы сервер корректно отвечал, в запрос добавляют заголовок User-Agent. Пример: requests.get(url, headers={«User-Agent»: «Mozilla/5.0»}). Это снижает вероятность возврата урезанного контента или перенаправления на заглушку.
Сетевые ошибки удобнее обрабатывать через блок try–except. Библиотека requests предлагает исключения Timeout, ConnectionError, HTTPError. При возникновении ошибки полезно фиксировать код ответа, время запроса и адрес страницы, чтобы понимать причину сбоя и корректировать интервал повторных попыток.
Для страниц, выдающих данные медленно, устанавливают ограничение по времени выполнения запроса: requests.get(url, timeout=5). Если сайт отвечает нестабильно, запрос повторяют через короткую задержку или используют цикл с ограничением количества попыток. Такой подход помогает избежать зависания парсера и исключить ситуацию, когда скрипт остаётся в ожидании ответа неопределённое время.
После успешного получения ответа проверяют статус-код. Если сервер возвращает значение в диапазоне 200–299, то текст страницы доступен через свойство response.text. При возврате кодов 400 или 500 фиксируют причину и решают, стоит ли повторять запрос или сохранять текущий результат в логах для последующего анализа.
Разбор структуры HTML для выбора нужных тегов и атрибутов

Перед извлечением данных открывают исходный HTML-код страницы через инструменты разработчика браузера. Вкладка Elements позволяет увидеть иерархию тегов, определить контейнеры, в которых расположены нужные элементы, и уточнить используемые классы, идентификаторы и атрибуты.
Для выделения текстовых блоков часто применяются теги <p>, <span>, <div>. В каталогах товаров встречаются структуры с повторяющимися узлами, где каждый товар оформлен в одном типе контейнера, например <div class=»item»>. Подобные элементы удобно выбирать через find_all с указанием класса.
Если значения хранятся в атрибутах, обращаются к полям href, src, data-* . Такие параметры востребованы при сборе ссылок, изображений или скрытых настроек. BeautifulSoup позволяет получать атрибуты через словарный доступ, например: элемент[«href»].
Страницы с нестандартной разметкой иногда используют вложенные структуры без классов. В таких случаях ориентируются на позицию тега относительно соседних элементов или применяют CSS-селекторы. Подход удобен при работе с таблицами, где нужно обратиться, например, к каждой ячейке второго столбца.
Извлечение текстового содержимого элементов с помощью методов BeautifulSoup
Для получения текста из выбранного элемента применяется свойство .text или метод .get_text(). Первый вариант подходит для простых структур, второй удобен при необходимости убрать лишние переносы строк или пробелы с помощью параметра strip=True. Такой подход ускоряет дальнейшую обработку данных и снижает объём дополнительной очистки.
Если элемент содержит вложенные теги, BeautifulSoup корректно собирает текст из всех уровней. Например, у блока <div>, внутри которого находятся заголовки, ссылки или фрагменты с разметкой, метод get_text() вернёт объединённый текст без HTML-тегов. Это полезно при парсинге новостей, описаний товаров и карточек статей.
В ситуациях, когда в элементе присутствуют и текст, и технические данные, можно ограничить выбор конкретными узлами. Метод .find() позволяет получить нужный фрагмент перед извлечением текста. Например, если внутри блока находятся несколько параграфов, выбирают нужный по классу и извлекают только его содержимое.
Для текстовых полей, содержащих числовые значения, иногда требуется приведение формата. После получения строки очищают её с помощью .replace() или методов регулярных выражений, чтобы корректно конвертировать данные в нужный тип перед сохранением или анализом.
Получение значений атрибутов и ссылок из выбранных HTML-узлов

Атрибуты элементов доступны через словарный доступ. Для ссылки используется обращение вида element[«href»]. Такой способ подходит для тегов <a>, <link> и любых узлов, где URL хранится в атрибуте. Если атрибут отсутствует, перед извлечением проверяют наличие ключа через element.has_attr(«href»), чтобы избежать исключений.
Некоторые сайты используют дополнительные данные в атрибутах data-*. Они содержат идентификаторы, параметры фильтров, рейтинги и прочие значения, которые не отображаются пользователю напрямую. BeautifulSoup позволяет получать такие параметры обычным обращением к словарю атрибутов. Это упрощает сбор структурированных данных, не представленных в текстовой части страницы.
При работе с относительными ссылками важно преобразовать их в абсолютные. Для этого комбинируют доменное имя сайта и значение атрибута. В Python это удобно выполнять через urllib.parse.urljoin(). Такой подход обеспечивает корректное сохранение путей, особенно если данные используются для перехода на вложенные страницы.
Для систематизации часто извлекаемых атрибутов полезно фиксировать их в таблице, чтобы исключить пропуски и несоответствия при последующей обработке.
| Элемент | Атрибут | Назначение |
|---|---|---|
| <a> | href | Получение ссылок |
| <img> | src | Путь к файлу |
| Любой тег | data-* | Внутренние параметры страницы |
| Блоки каталога | class | Поиск нужных контейнеров |
Парсинг списков товаров, статей или таблиц с повторяющейся структурой
Для извлечения данных из списков и таблиц используют метод find_all(), позволяющий выбрать все повторяющиеся элементы одного типа. В каталогах товаров это часто <div class=»item»>, в блогах – <article>, в таблицах – <tr>. Полученный список элементов обрабатывают циклом, извлекая текст и атрибуты каждого узла.
При работе с таблицами полезно отделять заголовки столбцов от строк с данными. Заголовки берут через <th>, а строки – через <td>. После извлечения текст очищают от лишних пробелов и символов переноса строк, чтобы сохранить однородный формат для анализа или записи в CSV/JSON.
Если структура элементов сложная, выбирают ключевые подузлы через find() внутри основного контейнера. Например, в карточке товара сначала выбирают блок с названием, затем блок с ценой, а после – изображение и ссылку. Такой подход позволяет формировать структурированный объект данных для каждой позиции.
Для ускорения обработки больших списков рекомендуется проверять наличие обязательных атрибутов перед извлечением и пропускать элементы с отсутствующими данными. Это уменьшает количество ошибок и упрощает последующую агрегацию информации.
Очистка и нормализация полученных данных после извлечения
После парсинга HTML важно привести данные к стандартизированному виду для корректного анализа и хранения. Основные задачи включают удаление лишних символов, корректировку форматов и проверку структуры данных.
- Удаление пробелов, переносов строк и невидимых символов с помощью strip() или регулярных выражений.
- Преобразование числовых значений: цены, количество просмотров или рейтинги конвертируют в int или float, удаляя пробелы, символы валют и разделители тысяч.
- Приведение дат к единому формату YYYY-MM-DD через модуль datetime для унификации всех записей.
- Проверка и преобразование ссылок: относительные URL объединяют с доменом сайта через urllib.parse.urljoin() для получения абсолютных адресов.
- Удаление дубликатов, особенно в каталогах товаров или списках статей, чтобы сохранить уникальные объекты.
- Очистка остатков HTML-тегов внутри текста с помощью BeautifulSoup(element.get_text(), «html.parser») или регулярных выражений.
- Стандартизация форматов текста: приведение всех строк к одному регистру, удаление лишних символов и специальных знаков.
Регулярная очистка и нормализация данных упрощает запись в CSV, JSON или базу данных, сокращает ошибки при последующем анализе и облегчает автоматическую обработку информации.
Сохранение результатов парсинга в JSON, CSV или базу данных
После извлечения и очистки данных важно организовать их хранение для последующей обработки. Выбор формата зависит от объёма информации и способов дальнейшего использования.
- JSON: подходит для структурированных данных с вложенными объектами. Сохраняют через модуль json:
import json with open("data.json", "w", encoding="utf-8") as f: json.dump(data_list, f, ensure_ascii=False, indent=4)Поддерживает иерархические структуры и сохраняет типы данных.
- CSV: удобен для таблиц и списков. Используют модуль csv:
import csv with open("data.csv", "w", newline="", encoding="utf-8") as f: writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() writer.writerows(data_list)Обеспечивает совместимость с Excel и аналитическими инструментами.
- База данных: применяют SQLite, PostgreSQL или MySQL при больших объёмах и необходимости быстрого поиска. Для SQLite пример с sqlite3:
import sqlite3 conn = sqlite3.connect("data.db") cursor = conn.cursor() cursor.execute("CREATE TABLE IF NOT EXISTS items (name TEXT, price REAL, url TEXT)") cursor.executemany("INSERT INTO items VALUES (?, ?, ?)", data_list) conn.commit() conn.close()Позволяет выполнять фильтрацию, агрегирование и обновление записей.
Выбор способа хранения зависит от структуры данных и задач анализа. JSON подходит для вложенных объектов, CSV – для таблиц, база данных – для масштабных проектов с постоянным доступом и обновлением информации.
Вопрос-ответ:
Что такое BeautifulSoup и для чего он используется в Python?
BeautifulSoup — это библиотека Python для парсинга HTML и XML. Она позволяет извлекать текст, ссылки, таблицы и другие элементы из веб-страниц. Основное преимущество заключается в удобстве навигации по структуре документа и возможности работы с тегами, классами и атрибутами.
Как безопасно получать HTML-код страницы с помощью requests?
Для получения HTML используют requests.get() с указанием заголовка User-Agent, чтобы сервер корректно обрабатывал запрос. Важно обрабатывать исключения Timeout, ConnectionError и HTTPError через блок try–except, а также проверять статус-код ответа. Для нестабильных сайтов полезно ограничивать таймаут и повторять запрос несколько раз с паузой.
Какие методы BeautifulSoup позволяют извлекать текст из элементов?
Для получения текстового содержимого применяют свойство .text или метод .get_text(). Метод get_text(strip=True) удаляет лишние пробелы и переносы строк. Если элемент содержит вложенные теги, эти методы собирают весь текст с подуровней, что удобно для новостных блоков, описаний товаров и статей.
Как работать с атрибутами и ссылками внутри HTML-узлов?
Атрибуты элементов доступны через словарный синтаксис, например, element[«href»] для ссылок. Перед обращением стоит проверить наличие атрибута через element.has_attr(«href»). Относительные ссылки преобразуют в абсолютные с помощью urllib.parse.urljoin(). Атрибуты data-* используются для получения дополнительных параметров страницы, которые не отображаются в тексте.
Как сохранять результаты парсинга для последующего анализа?
Результаты можно хранить в формате JSON для вложенных объектов, CSV для таблиц и списков или в базу данных SQLite, PostgreSQL, MySQL для больших объёмов. JSON сохраняют через json.dump(), CSV через csv.DictWriter, а базу данных через библиотеку для выбранного движка с созданием таблиц и добавлением записей через INSERT. Такой подход обеспечивает удобное чтение, фильтрацию и обновление данных.
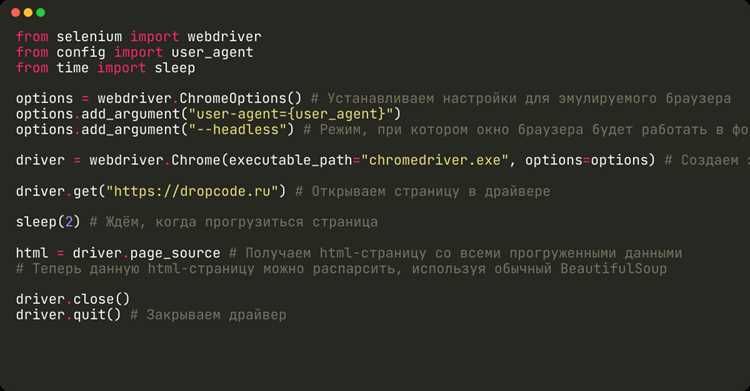
Как обрабатывать динамически загружаемые данные на сайте при использовании BeautifulSoup?
BeautifulSoup работает с уже загруженным HTML-кодом страницы, поэтому контент, который подгружается через JavaScript после первичной загрузки, напрямую извлечь не получится. Для таких случаев используют комбинацию инструментов: сначала получают итоговый HTML через браузерный движок, например, с помощью Selenium или Playwright, затем передают этот HTML в BeautifulSoup для парсинга. После этого можно применять обычные методы извлечения текста, атрибутов и ссылок. Важно учитывать задержки загрузки данных, чтобы скрипт успел получить полный контент.