
Содержание статьи

Машинный код представляет собой последовательность бинарных инструкций, которые процессор способен выполнять напрямую. Каждая команда кодируется в виде комбинации нулей и единиц, где первые биты определяют операцию, а оставшиеся – адреса регистров, памяти или непосредственные значения. Понимание структуры машинного кода позволяет программисту контролировать использование ресурсов процессора и сокращать время выполнения операций.
Компиляция высокоуровневого языка в машинный код происходит через ассемблер или компилятор, который преобразует инструкции в набор бинарных команд, соответствующих конкретной архитектуре процессора. Различные процессоры используют разные наборы команд (ISA), поэтому одна и та же программа может требовать адаптации к конкретной платформе. Для анализа работы программы на уровне машинного кода применяются дизассемблеры и профилировщики, позволяющие выявлять узкие места и потенциальные ошибки.
При работе с машинным кодом важно учитывать ограничения памяти, особенности кэширования и конвейерной обработки инструкций. Прямое управление командами дает возможность точной оптимизации, включая сокращение числа обращений к памяти и уменьшение задержек при выполнении циклов. Рекомендуется документировать инструкции и их назначения, особенно в проектах, где требуется взаимодействие с аппаратным обеспечением или критически высокая производительность.
Структура команд машинного кода и их назначение

Команда машинного кода состоит из нескольких полей, каждое из которых выполняет конкретную функцию:
- Опкод (Opcode) – определяет тип операции, например, сложение, чтение из памяти или переход.
- Регистр-операнд – указывает, какие регистры процессора участвуют в операции.
- Адрес памяти – используется для загрузки или сохранения данных, может быть прямым или косвенным.
- Непосредственное значение – числовой литерал, который участвует в вычислениях без обращения к памяти.
- Флаги и модификаторы – задают условия выполнения команды или определяют способ обработки данных.
Для эффективного анализа машинного кода важно различать форматы команд:
- Фиксированный формат – все поля имеют одинаковый размер, что упрощает декодирование и ускоряет выполнение.
- Переменный формат – размер полей зависит от типа операции или длины адреса, что позволяет экономить память.
Рекомендации при работе с командами машинного кода:
- Составлять таблицы соответствия опкодов и операций для используемой архитектуры.
- Документировать использование регистров и адресов, чтобы избежать конфликтов при оптимизации.
- Проверять корректность флагов и модификаторов, особенно при условных переходах.
- Использовать дизассемблеры для анализа последовательности команд и выявления узких мест.
Как процессор интерпретирует машинный код

Процессор считывает команды машинного кода из памяти по адресу, указанному в счетчике команд. Каждая инструкция проходит несколько этапов обработки:
- Выборка (Fetch) – команда извлекается из памяти и помещается в буфер инструкций.
- Декодирование (Decode) – опкод распознается, определяется тип операции и необходимые операнды.
- Исполнение (Execute) – процессор выполняет операцию, используя регистры, арифметико-логическое устройство и память.
- Запись результата (Write Back) – результат операции сохраняется в регистры или память.
В современных процессорах используется конвейерная обработка, при которой несколько команд проходят этапы параллельно. Это ускоряет выполнение, но требует точного управления порядком команд и проверкой зависимостей данных.
Рекомендации при работе с машинным кодом для анализа поведения процессора:
- Изучать схемы архитектуры конкретного процессора, включая количество регистров и типы опкодов.
- Следить за порядком инструкций, чтобы избежать конфликтов при обращении к одним и тем же регистрам.
- Использовать симуляторы и профилировщики для проверки последовательности выполнения и времени отклика команд.
- Анализировать влияние условных переходов и циклов на конвейер и кэш процессора.
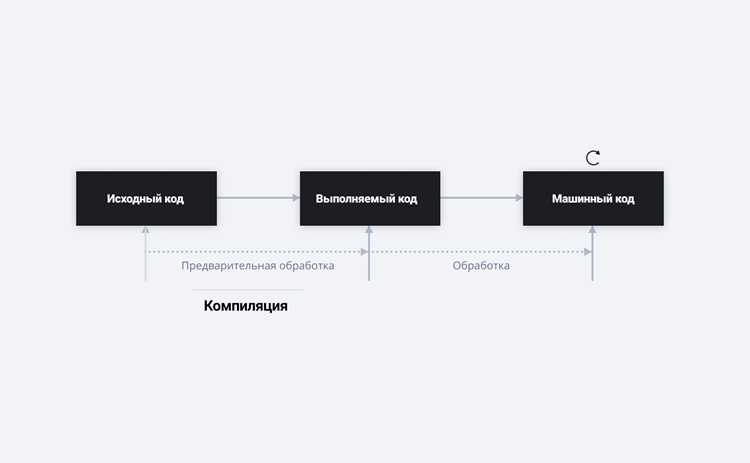
Методы перевода исходного кода в машинный код
Перевод исходного кода в машинный код выполняется с использованием компиляторов, интерпретаторов и ассемблеров. Каждый метод имеет собственные особенности, влияющие на производительность и размер исполняемого файла.
Сравнительные характеристики методов представлены в таблице:
| Метод | Принцип работы | Преимущества | Особенности применения |
|---|---|---|---|
| Компиляция | Полный исходный код преобразуется в машинный код заранее | Высокая скорость выполнения, полный контроль над оптимизацией | Используется для статически типизированных языков и крупных проектов |
| Интерпретация | Команды выполняются построчно или блоками во время работы программы | Быстрая проверка и отладка, не требуется генерация отдельных файлов | Применяется для скриптовых языков и тестирования отдельных модулей |
| Ассемблирование | Прямой перевод ассемблерных инструкций в машинный код | Максимальный контроль над регистрами и памятью | Используется для системного программирования и оптимизации критичных участков кода |
Рекомендации при выборе метода перевода:
- Для проектов, где важна скорость выполнения, предпочтительна компиляция с оптимизацией под конкретную архитектуру.
- Для быстрого прототипирования и отладки удобнее использовать интерпретаторы с возможностью пошагового анализа команд.
- Ассемблер эффективен при необходимости прямого управления оборудованием и точного распределения ресурсов процессора.
- При комбинировании методов стоит разделять критичные участки кода для компиляции и остальной код оставлять интерпретируемым для гибкости.
Особенности работы с различными архитектурами процессоров

Архитектура процессора определяет набор команд, количество регистров, размер адресного пространства и способы обращения к памяти. При разработке на уровне машинного кода важно учитывать эти различия для корректного выполнения программ.
Основные различия архитектур:
- RISC (Reduced Instruction Set Computer) – небольшое количество простых инструкций, каждая выполняется за один такт. Рекомендуется упрощать алгоритмы и максимально использовать регистры для хранения данных.
- CISC (Complex Instruction Set Computer) – набор длинных и сложных инструкций, каждая может выполнять несколько операций. Рекомендуется анализировать декодирование команд и избегать чрезмерного комбинирования операций в одной инструкции.
- 32-битные и 64-битные процессоры – отличаются размером адресного пространства и регистров. При переводе исходного кода необходимо учитывать тип данных и выравнивание памяти.
- Конвейерные и суперскалярные архитектуры – могут выполнять несколько инструкций параллельно. Следует избегать зависимостей между последовательными командами, чтобы не снижать производительность.
Рекомендации при работе с различными архитектурами:
- Составлять карту регистров и контролировать их использование для предотвращения перезаписи данных.
- Определять частоту обращения к памяти и кэш-памяти для снижения задержек при выполнении команд.
- Использовать симуляторы архитектуры для проверки корректности выполнения машинного кода на конкретной платформе.
- Изучать спецификации процессора для правильного применения условных переходов, вызовов функций и обработки прерываний.
Ошибки и отладка на уровне машинного кода
Ошибки на уровне машинного кода часто связаны с некорректным использованием регистров, неправильными адресами памяти или неверной последовательностью инструкций. Такие ошибки приводят к сбоям, неожиданным переходам или повреждению данных.
Основные типы ошибок:
- Неправильные опкоды – команда не соответствует набору инструкций процессора и вызывает исключение.
- Ошибки адресации – выход за границы памяти, несоответствие формата адреса, конфликт с кэшированием.
- Конфликты регистров – одновременное использование одного регистра для нескольких операций без сохранения промежуточных данных.
- Нарушение порядка инструкций – условные переходы и циклы выполняются неправильно, что приводит к логическим ошибкам.
Методы отладки:
- Использовать дизассемблеры для анализа последовательности команд и выявления несоответствий.
- Применять симуляторы процессора для пошагового выполнения машинного кода и контроля регистров и памяти.
- Ставить контрольные точки и логировать состояние регистров и флагов после каждой ключевой инструкции.
- Тестировать критичные участки кода с разными комбинациями входных данных, чтобы выявить скрытые ошибки адресации и зависимостей.
Рекомендации:
- Документировать назначение каждого регистра и область памяти для уменьшения риска конфликтов.
- Разделять сложные операции на несколько простых команд, чтобы облегчить отладку и анализ исполнения.
- Систематически проверять корректность условных переходов и циклов, особенно при конвейерной обработке инструкций.
Оптимизация программы через прямое управление инструкциями
Прямое управление инструкциями позволяет уменьшить количество операций и сократить задержки при выполнении циклов и ветвлений. Это достигается за счет точного распределения регистров, минимизации обращений к памяти и контроля порядка команд.
Методы оптимизации:
- Использование регистров для временных данных – хранение промежуточных результатов в регистрах снижает задержки доступа к памяти.
- Реорганизация команд – перемещение независимых инструкций перед или после зависимых для максимального заполнения конвейера процессора.
- Сведение к минимуму ветвлений – использование условных инструкций и циклов с предсказанием переходов уменьшает вероятность конвейерных простоев.
- Сокращение обращения к памяти – объединение операций, работающих с одними и теми же адресами, для уменьшения количества загрузок и сохранений.
- Инлайн-команды – внедрение часто повторяющихся коротких функций непосредственно в основной код для устранения накладных расходов на вызовы.
Рекомендации при оптимизации машинного кода:
- Проверять результат каждой модификации на корректность выполнения, чтобы избежать логических ошибок.
- Использовать профилировщики и симуляторы процессора для анализа узких мест и оценки времени выполнения команд.
- Документировать изменения и назначение регистров, чтобы облегчить поддержку и дальнейшие доработки.
Применение машинного кода в современных языках и системах
Машинный код лежит в основе всех современных языков программирования, обеспечивая работу компиляторов и виртуальных машин. Компиляторы языков C, C++ и Rust переводят исходный код в машинные инструкции, оптимизированные под конкретные архитектуры процессоров.
В системах с виртуальными машинами, таких как Java и .NET, исходный код сначала преобразуется в промежуточный байт-код, который затем интерпретируется или компилируется в машинный код на лету (JIT-компиляция). Это обеспечивает баланс между переносимостью и производительностью.
Применение машинного кода в современных системах включает:
- Оптимизацию критичных участков программ, например, обработку графики или вычислительные задачи в научных расчетах.
- Разработку драйверов и низкоуровневых модулей для взаимодействия с оборудованием.
- Использование встроенных ассемблерных вставок в высокоуровневых языках для точного контроля регистров и памяти.
- Реализацию систем реального времени, где важно минимальное время отклика и предсказуемое выполнение инструкций.
Рекомендации при использовании машинного кода в современных проектах:
- Анализировать совместимость инструкций с целевой архитектурой процессора.
- Документировать ассемблерные вставки и изменения, чтобы обеспечить поддержку и переносимость кода.
- Использовать профилировщики для оценки влияния низкоуровневых оптимизаций на общую производительность системы.
Вопрос-ответ:
Что такое машинный код и как он отличается от ассемблера?
Машинный код — это набор бинарных инструкций, которые процессор выполняет напрямую. Ассемблер использует мнемоники и символические адреса, которые затем преобразуются в машинный код. Основное отличие в том, что машинный код состоит только из чисел и непосредственно управляет аппаратными ресурсами, тогда как ассемблер упрощает понимание и редактирование инструкций человеком.
Почему важно учитывать архитектуру процессора при работе с машинным кодом?
Разные процессоры используют различные наборы команд, количество регистров и размер адресного пространства. Инструкция, корректная для одной архитектуры, может быть недопустимой на другой. Игнорирование этих особенностей приводит к сбоям и некорректной работе программ, поэтому при оптимизации или низкоуровневой разработке необходимо точно соответствовать архитектуре целевого процессора.
Какие методы существуют для перевода исходного кода в машинный код?
Существует три основных метода: компиляция, интерпретация и ассемблирование. Компиляция преобразует весь исходный код в машинный код заранее, обеспечивая высокую скорость выполнения. Интерпретация выполняет команды построчно во время работы программы, позволяя быстро тестировать и отлаживать код. Ассемблирование преобразует ассемблерные инструкции в машинный код, что дает полный контроль над регистрами и памятью.
Какие ошибки чаще всего встречаются на уровне машинного кода?
Основные ошибки связаны с неправильными опкодами, некорректной адресацией памяти, конфликтами регистров и нарушением порядка выполнения команд. Эти ошибки могут вызывать сбои, повреждение данных и некорректное выполнение циклов. Для их обнаружения используют дизассемблеры, симуляторы процессора и логирование состояния регистров после ключевых инструкций.
В каких случаях имеет смысл использовать машинный код в современных языках программирования?
Машинный код применяется при необходимости точного контроля ресурсов процессора, оптимизации критичных участков, разработке драйверов и систем реального времени. В современных языках часто используют ассемблерные вставки для ускорения вычислений, снижения задержек и реализации функций, требующих прямого управления регистрами и памятью.
Каким образом машинный код влияет на производительность программы и как его можно оптимизировать?
Машинный код напрямую управляет процессором и памятью, поэтому структура команд и порядок их выполнения определяют скорость работы программы. Оптимизация возможна через минимизацию обращений к памяти, использование регистров для временных данных и упорядочивание инструкций для заполнения конвейера процессора. Также применяются методы сокращения ветвлений и внедрения часто повторяющихся функций непосредственно в основной код, что уменьшает накладные расходы на вызовы. Для контроля изменений рекомендуется использовать профилировщики и симуляторы, которые позволяют оценить влияние каждой оптимизации на выполнение программы.





