Содержание статьи

Решение подзадачи на языке программирования требует четкого определения целей и структуры данных, которые будут использоваться для хранения промежуточных результатов. Например, при работе с массивами чисел выбор между массивом фиксированного размера и динамическим списком напрямую влияет на скорость доступа и возможность масштабирования. Рекомендуется заранее оценить объем данных и характер операций чтения и записи.
Следующий важный этап – определение базового случая и условий остановки. В рекурсивных алгоритмах неправильная формулировка этих условий приводит к переполнению стека или бесконечным циклам. Для подзадач с многократной обработкой элементов стоит явно фиксировать границы цикла и проверять индексы на каждом шаге.
Практическая реализация подзадачи требует детальной проработки шагов обработки каждого элемента. При сортировке или фильтрации данных алгоритм должен учитывать все возможные состояния элементов и предусматривать обработку исключений, например деление на ноль или работу с пустыми значениями. Тестирование отдельных блоков кода до интеграции в основной алгоритм сокращает вероятность ошибок.
Оптимизация использования памяти важна при работе с большими объемами данных. Применение ссылок вместо копирования объектов, использование очередей и стеков вместо массивов больших размеров позволяет уменьшить нагрузку на оперативную память. Для многопоточных задач также следует контролировать доступ к разделяемым ресурсам и синхронизацию потоков.
Проверка корректности результатов включает сравнение выходных данных с ожидаемыми и анализ граничных случаев. Важна систематическая отладка с использованием логирования и пошагового контроля значений переменных. Подход «малых шагов» помогает выявить ошибки на ранней стадии разработки и ускоряет доработку алгоритма.
Выбор структуры данных для хранения промежуточных результатов

При реализации подзадачи выбор структуры данных напрямую влияет на скорость выполнения и объем потребляемой памяти. Для фиксированных наборов данных лучше использовать массивы или статические списки, так как доступ к элементу по индексу выполняется за O(1), а память выделяется заранее.
Если количество элементов заранее неизвестно или изменяется динамически, целесообразно применять связные списки или динамические массивы. Связные списки позволяют вставлять и удалять элементы без перераспределения всей структуры, однако доступ по индексу требует последовательного обхода.
Для хранения уникальных значений подойдут множества (Set) или хеш-таблицы. Они обеспечивают быстрый поиск, вставку и проверку существования элемента. При выборе хеш-таблицы важно учитывать качество хеш-функции и возможные коллизии, чтобы избежать деградации скорости.
При обработке данных с приоритетами рекомендуется использовать очереди с приоритетом или бинарные кучи. Это позволяет извлекать элемент с наивысшим приоритетом за логарифмическое время и упрощает управление промежуточными результатами в алгоритмах сортировки и планирования задач.
Для многомерных данных или сложных структур, таких как графы и деревья, следует использовать специализированные структуры: матрицы смежности для плотных графов, списки смежности для разреженных, а бинарные деревья или деревья поиска для упорядоченных элементов. Выбор зависит от частоты операций вставки, удаления и поиска.
Определение базового случая и условий остановки
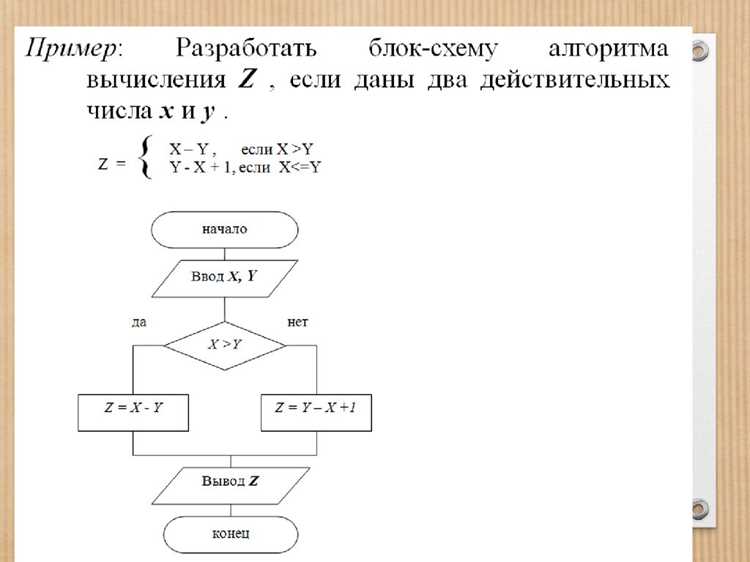
Базовый случай задает минимальное состояние подзадачи, при котором дальнейшие вычисления не требуются. В рекурсивных алгоритмах, например при вычислении факториала, базовый случай равен n = 0 или n = 1. Без точного определения базового случая рекурсия может привести к переполнению стека.
Условия остановки в циклах определяют момент завершения итераций. Для обработки массива длиной n цикл должен выполняться от 0 до n-1 с явной проверкой границ, чтобы избежать выхода за пределы и ошибок доступа к памяти.
При решении задач с динамическим разбиением на подзадачи важно проверять, что каждый новый фрагмент имеет размер, достаточный для обработки. Например, в алгоритмах быстрой сортировки подмассива длиной 1 или 0 дальнейшее деление не требуется, и это должно быть явно зафиксировано в коде.
Для подзадач с множественными условиями остановки рекомендуется использовать логические операторы для объединения критериев. Это позволяет контролировать завершение процесса даже при сложных зависимостях между элементами и предотвращает бесконечные циклы.
Тестирование базовых случаев на граничных значениях помогает выявить ошибки на ранней стадии. Например, проверка пустого массива, нулевых коэффициентов или отрицательных чисел позволяет убедиться, что алгоритм корректно завершает выполнение без побочных эффектов.
Разработка шагов обработки отдельных элементов подзадачи

Каждый элемент подзадачи следует обрабатывать с учетом его типа и структуры данных. Для числовых массивов операции суммирования, умножения или фильтрации должны выполняться с проверкой на переполнение и допустимые диапазоны значений. Использование встроенных функций и библиотек помогает снизить вероятность ошибок при математических вычислениях.
При работе с текстовыми данными необходимо учитывать кодировку символов и возможные пустые строки. Операции сравнения и извлечения подстрок должны предусматривать проверку длины строки и наличие символов, чтобы избежать ошибок при доступе за пределы строки.
Для объектов и структур данных с несколькими полями обработка должна выполняться по ключевым атрибутам. Например, при фильтрации объектов по дате важно сравнивать значения в едином формате и учитывать временную зону, чтобы результаты были корректными.
Если подзадача предполагает последовательные шаги с зависимостями между элементами, следует явно фиксировать порядок операций. При сортировке, агрегации или объединении данных неправильный порядок может привести к некорректным результатам.
Для элементов, которые могут вызывать ошибки выполнения, необходимо добавлять проверку условий и обработку исключений. Например, перед делением чисел проверять делитель на ноль, а перед доступом к массиву – индекс на допустимый диапазон.
Использование циклов и рекурсии для последовательной обработки

Выбор между циклами и рекурсией зависит от структуры подзадачи и требований к памяти. Циклы подходят для повторяющихся операций с известным количеством итераций, рекурсия – для разбиения задачи на идентичные подзадачи.
Рекомендации по использованию циклов:
- Использовать for или while для последовательного обхода массивов и списков.
- При работе с вложенными структурами применять вложенные циклы с четкой проверкой границ.
- Минимизировать изменения индексов внутри тела цикла, чтобы избежать пропуска элементов или бесконечных итераций.
Рекомендации по применению рекурсии:
- Определить базовый случай для прекращения вызова рекурсивной функции.
- Передавать только необходимые параметры для обработки подзадачи, чтобы снизить нагрузку на стек.
- Использовать мемоизацию для сохранения промежуточных результатов и предотвращения повторных вычислений.
Комбинированные подходы:
- Цикл для обхода элементов, внутри которого вызывается рекурсивная функция для обработки вложенных структур.
- Рекурсивная функция, которая использует цикл для обработки элементов текущего уровня.
- Контролировать глубину рекурсии и размер коллекций для предотвращения переполнения памяти.
Обработка ошибок и исключений при выполнении подзадачи
При реализации подзадачи важно предусмотреть возможные ошибки выполнения и исключения, чтобы алгоритм продолжал корректно работать. Основные типы ошибок включают деление на ноль, выход за границы массива, неправильный тип данных и переполнение памяти.
Рекомендации по обработке ошибок:
| Тип ошибки | Метод обработки | Пример на языке программирования |
|---|---|---|
| Деление на ноль | Проверка делителя перед операцией | if (b != 0) result = a / b; |
| Выход за границы массива | Сравнение индекса с размером массива | if (i < array.length) process(array[i]); |
| Неправильный тип данных | Использование проверки типа или преобразования | if (value instanceof Integer) process(value); |
| Переполнение памяти | Ограничение размера коллекций, использование потоковой обработки | List<Integer> subset = fullList.subList(0, limit); |
Для структурированных исключений рекомендуется применять блоки try-catch (или аналоги в языке программирования) и логирование ошибок. Это позволяет выявлять проблемные участки кода и предотвращать аварийное завершение подзадачи.
Оптимизация использования памяти при решении подзадачи
Рекомендации по уменьшению расхода памяти:
- Использовать ссылки на объекты вместо копирования при передаче данных между функциями.
- Применять потоковую обработку данных (streaming), чтобы не загружать весь массив в память одновременно.
- Удалять временные объекты сразу после использования, особенно в циклах и рекурсивных вызовах.
- Для многомерных массивов проверять возможность использования одномерного массива с индексированием.
Оптимизация рекурсивных алгоритмов:
- Использовать хвостовую рекурсию, где это поддерживается компилятором, чтобы уменьшить стек вызовов.
- Хранить промежуточные результаты в хеш-таблицах или массивах для повторного использования (мемоизация).
- Ограничивать глубину рекурсии при обработке больших структур данных и при необходимости переходить на итеративный метод.
Для динамических структур важно контролировать выделение и освобождение памяти. Использование пулов объектов или предварительное выделение памяти снижает частоту вызовов сборщика мусора и ускоряет выполнение подзадачи.
Проверка корректности результатов и отладка алгоритма

Проверка корректности начинается с тестирования подзадачи на граничных значениях и типовых сценариях. Для числовых массивов это минимальные, максимальные и отрицательные значения, для строк – пустые и односимвольные строки. Сравнение результата с заранее известным эталоном позволяет выявить ошибки на ранней стадии.
Логирование промежуточных результатов помогает отслеживать работу алгоритма на каждом шаге. Запись значений ключевых переменных и состояния структуры данных позволяет выявить отклонения и неправильно обработанные элементы.
Использование пошаговой отладки в IDE или с помощью внешних инструментов дает возможность остановить выполнение на критических точках и проверить значения переменных. Это особенно важно при рекурсивных вызовах и вложенных циклах.
Автоматизированное тестирование ускоряет выявление ошибок после внесения изменений. Создание набора тестов с разными сценариями и проверка их прохождения после каждого изменения кода минимизирует риск регрессий.
Вопрос-ответ:
Как выбрать подходящую структуру данных для хранения промежуточных результатов?
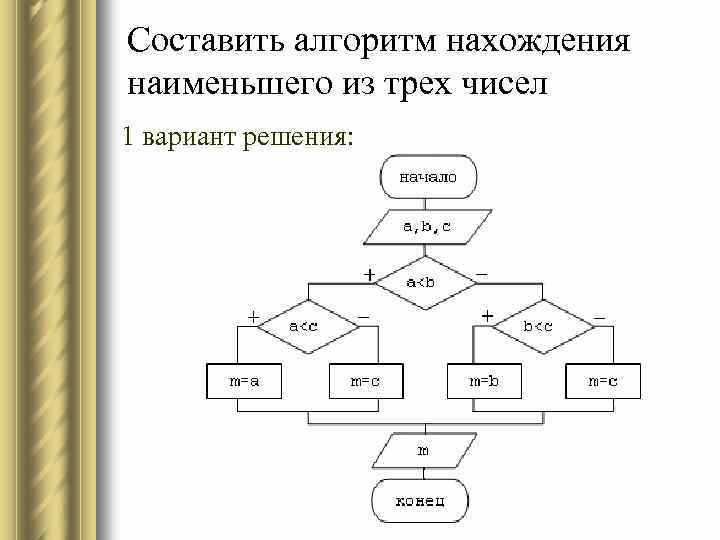
Выбор структуры данных зависит от объема и типа информации. Для фиксированных массивов чисел подходят обычные массивы с быстрым доступом по индексу. Если размер данных изменяется динамически, лучше использовать связные списки или динамические массивы. Для хранения уникальных значений подходят множества или хеш-таблицы, а для элементов с приоритетом — очереди с приоритетом или бинарные кучи.
Почему важно определять базовый случай и условия остановки в алгоритме?
Базовый случай предотвращает бесконечное выполнение рекурсии или цикла. Например, при вычислении факториала базовый случай — n=0 или n=1. Условия остановки циклов контролируют границы обхода массива или списка, предотвращая выход за пределы структуры данных и ошибки доступа к памяти. Это снижает вероятность аварийного завершения программы.
Какие методы проверки корректности работы подзадачи существуют?
Проверка включает тестирование на граничных значениях, сравнение с ожидаемыми результатами и логирование промежуточных данных. Пошаговая отладка позволяет проследить изменение переменных на каждом этапе. Для сложных структур, таких как графы или деревья, полезно визуализировать состояния элементов для понимания корректности операций вставки, удаления и сортировки.
Когда лучше использовать рекурсию, а когда циклы?
Рекурсия подходит для разбиения задачи на одинаковые подзадачи, например в быстрой сортировке или обходе дерева. Циклы предпочтительны при последовательной обработке известных объемов данных. Иногда эффективен комбинированный подход: цикл для обхода элементов, внутри которого вызывается рекурсивная функция для обработки вложенных структур.
Какие приемы позволяют уменьшить потребление памяти при решении подзадачи?
Сократить использование памяти помогают ссылки на объекты вместо копирования, удаление временных объектов после использования, потоковая обработка данных и ограничение глубины рекурсии. Для больших массивов можно использовать одномерные массивы вместо многомерных с расчетом индексов, а для повторяющихся вычислений — хранить промежуточные результаты для повторного использования.