Содержание статьи

Работа с текстовыми файлами в Python часто требует очистки данных от лишних пустых строк. Пустые строки увеличивают размер файла и могут нарушать обработку данных при чтении, парсинге или анализе. Даже несколько тысяч пустых строк способны замедлить скрипты, особенно при больших объемах данных.
В Python существует несколько методов удаления пустых строк, начиная от встроенных функций чтения и записи файлов до использования генераторов и списковых включений. Каждый способ отличается простотой реализации и влиянием на производительность. Например, чтение файла построчно с последующей фильтрацией строк позволяет обрабатывать большие файлы без загрузки всего содержимого в память.
Для небольших файлов можно использовать метод readlines() с фильтрацией строк через условие if line.strip(). Это позволяет быстро получить список только непустых строк и затем записать его обратно в файл. Для больших файлов рекомендуется использовать итераторы и запись в новый файл построчно, чтобы избежать избыточного потребления памяти.
Статья подробно рассматривает несколько практичных способов удаления пустых строк, приводя конкретные примеры кода с пояснениями. После прочтения вы сможете выбирать оптимальный метод в зависимости от размера файла и требований к скорости обработки данных.
Удаление пустых строк при чтении файла построчно
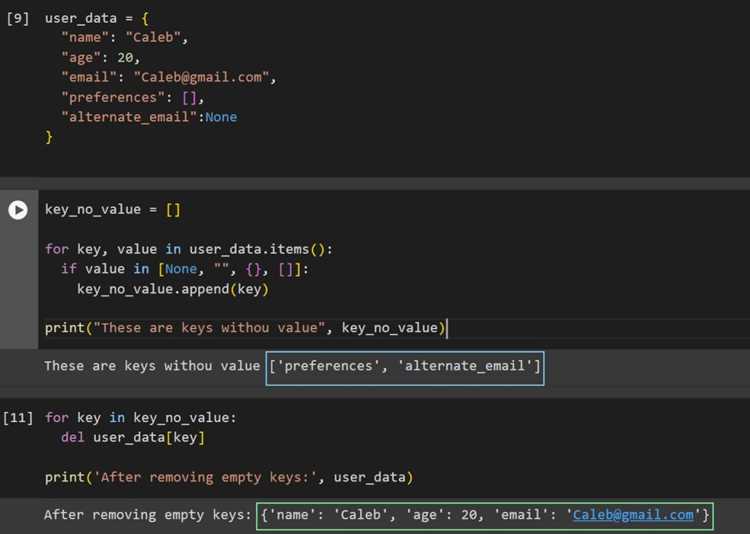
Пример с итерацией по файлу: открываем файл в режиме чтения, проходим по каждой строке и проверяем её на наличие содержимого после удаления пробельных символов с помощью strip(). Только строки с текстом добавляются в новый список или сразу записываются в другой файл.
Пример кода:
with open('input.txt', 'r', encoding='utf-8') as infile,
open('output.txt', 'w', encoding='utf-8') as outfile:
for line in infile:
if line.strip():
outfile.write(line)
Этот метод позволяет не загружать весь файл в память, что важно для больших данных. line.strip() удаляет пробелы и символы переноса строки, предотвращая запись пустых строк в результат.
Альтернативный подход – использовать генераторное выражение для фильтрации строк прямо при записи: outfile.writelines(line for line in infile if line.strip()). Это упрощает код и экономит ресурсы.
Построчное удаление пустых строк подходит для любых текстовых форматов, включая логи, CSV и конфигурационные файлы, где важна структура строк и последовательность данных.
Использование спискового включения для фильтрации пустых строк
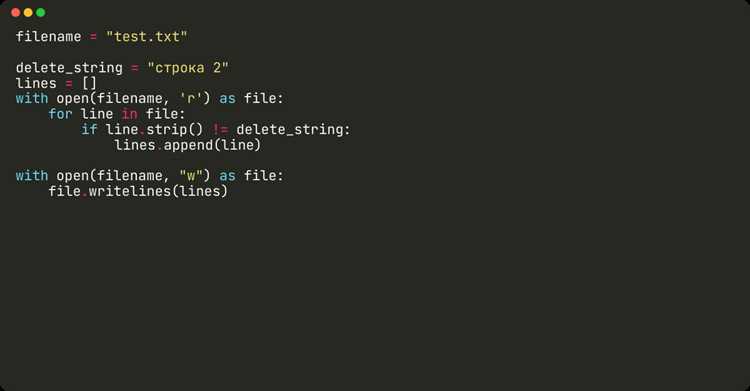
Списковое включение в Python позволяет создавать новый список на основе существующего, применяя фильтры и условия. Для удаления пустых строк из файла этот подход обеспечивает компактность и скорость выполнения.
Пример чтения файла и фильтрации пустых строк:
with open('file.txt', 'r', encoding='utf-8') as f:
lines = [line for line in f if line.strip()]
Разбор кода:
line.strip()удаляет пробелы и символы перевода строки, возвращая пустую строку для пустых или содержащих только пробелы строк.- Условие
if line.strip()оставляет только строки с содержимым. - В результате
linesсодержит все непустые строки файла.
Списковое включение можно комбинировать с записью обратно в файл:
with open('file.txt', 'w', encoding='utf-8') as f:
f.writelines(line for line in lines)
Рекомендации при работе с большим файлом:
- Использовать генератор вместо списка:
(line for line in f if line.strip()), чтобы не загружать весь файл в память. - Сохранять исходное кодирование файла для предотвращения ошибок с символами Unicode.
- При необходимости удалять строки с пробелами или табуляцией –
line.strip()обеспечит корректную фильтрацию.
Удаление строк с пробелами и табуляциями
В Python строки, содержащие только пробелы или табуляции, считаются непустыми, поэтому простое чтение файла и проверка на пустоту не удалит такие строки. Для их фильтрации удобно использовать метод strip(), который удаляет пробельные символы с начала и конца строки.
Пример удаления строк с пробелами и табуляциями при чтении файла:
with open('input.txt', 'r', encoding='utf-8') as f:
lines = [line for line in f if line.strip()]
with open('output.txt', 'w', encoding='utf-8') as f:
f.writelines(lines)
В этом примере line.strip() возвращает пустую строку для строк, содержащих только пробелы или табуляции, и такие строки исключаются из итогового списка. Результат записывается обратно в файл без лишних пустых строк.
Для больших файлов, чтобы избежать загрузки всего содержимого в память, можно обрабатывать строки по одной:
with open('input.txt', 'r', encoding='utf-8') as infile, open('output.txt', 'w', encoding='utf-8') as outfile:
for line in infile:
if line.strip():
outfile.write(line)
Этот метод сохраняет исходный порядок строк и эффективно удаляет все строки, состоящие только из пробелов и табуляций, без лишней нагрузки на память.
Сохранение результата в новый файл без пустых строк
Для удаления пустых строк и сохранения очищенного текста в новый файл используется чтение исходного файла построчно с последующей фильтрацией. Это позволяет создать отдельный файл с только значимым содержимым.
Пример реализации:
with open('input.txt', 'r', encoding='utf-8') as infile, \
open('cleaned_output.txt', 'w', encoding='utf-8') as outfile:
for line in infile:
if line.strip(): # исключает строки, содержащие только пробелы или табуляции
outfile.write(line)
|
Объяснение:
|
input.txt – исходный файл с пустыми строками и пробелами. |
|
cleaned_output.txt – файл для записи только непустых строк. |
|
|
Этот способ оптимален для больших файлов, так как не требует загрузки всего содержимого в память. Для повторного использования можно оформить код в функцию с параметрами для исходного и результирующего файлов.
Очистка файла на месте без создания копии

Для удаления пустых строк непосредственно в исходном файле используется режим чтения и записи ‘r+’ в Python. Сначала файл открывается для чтения всех строк, затем курсор возвращается в начало с помощью seek(0), и непустые строки записываются обратно.
Пример реализации:
with open('file.txt', 'r+') as f:
lines = f.readlines()
f.seek(0)
f.writelines([line for line in lines if line.strip()])
f.truncate()
Метод strip() удаляет пробелы и символы табуляции, предотвращая сохранение строк, содержащих только пустое пространство. Важно вызвать truncate(), чтобы обрезать остаток файла после записи, иначе в конце могут остаться старые данные.
Этот подход эффективен для небольших и средних файлов. Для больших файлов лучше использовать построчную обработку с временным буфером, чтобы снизить нагрузку на память, но при этом сохранять изменения без создания отдельной копии.
Применение метода filter() для удаления пустых строк
Метод filter() позволяет эффективно отфильтровать пустые строки из списка строк файла без использования циклов и дополнительных условий. Он возвращает итератор, содержащий только элементы, для которых функция-предикат возвращает True.
Пример использования при работе с файлом:
with open('file.txt', 'r') as f:
lines = f.readlines()
non_empty_lines = list(filter(str.strip, lines))
with open('file.txt', 'w') as f:
f.writelines(non_empty_lines)
- Функция
str.stripудаляет пробелы и символы перевода строки в начале и конце строки. Если строка пустая после удаления пробелов,filterеё исключает. - Метод работает напрямую с любыми итерируемыми объектами, что позволяет использовать его не только с результатом
readlines(), но и с генераторами. - С помощью
list()можно получить список для записи обратно в файл или дальнейшей обработки.
Использование filter() особенно удобно при больших файлах, так как предикат вызывается только для каждой строки без лишних проверок и условных операторов.
Также можно применять его совместно с генераторами для минимизации потребления памяти:
with open('file.txt', 'r') as f, open('clean_file.txt', 'w') as out:
out.writelines(filter(str.strip, f))
- В этом случае строки читаются и записываются по мере обработки, что экономит оперативную память.
- Метод полностью исключает пустые и состоящие только из пробелов строки без дополнительных циклов.
Удаление пустых строк с помощью регулярных выражений
Регулярные выражения позволяют точно определять шаблоны строк для их удаления. В Python используется модуль re, который поддерживает функции поиска и замены по шаблону.
Для удаления пустых строк достаточно использовать шаблон r'^\s*$\n', где ^\s*$ соответствует строкам, содержащим только пробельные символы, а \n учитывает перенос строки.
Пример кода для очистки файла с помощью регулярных выражений:
import re
with open('file.txt', 'r', encoding='utf-8') as f:
content = f.read()
cleaned = re.sub(r'^\s*$\n', '', content, flags=re.MULTILINE)
with open('file.txt', 'w', encoding='utf-8') as f:
f.write(cleaned)
Флаг re.MULTILINE необходим для обработки каждой строки отдельно, иначе регулярное выражение применялось бы к тексту целиком. Этот метод удаляет строки, полностью состоящие из пробелов или табуляций, оставляя только содержательные строки.
Регулярные выражения особенно эффективны при работе с большими файлами или текстом с непредсказуемым количеством пробелов и пустых строк между данными.
Обработка больших файлов без загрузки всего в память
При работе с большими файлами загрузка всего содержимого в память может привести к значительной нагрузке или сбою программы. Эффективный подход – чтение файла построчно и запись сразу в новый файл без пустых строк.
Для этого используйте конструкцию with open() и итерацию по объекту файла. Каждая строка проверяется на наличие текста с помощью метода strip(). Пустые строки игнорируются, а непустые записываются в выходной файл:
Пример:
with open('input.txt', 'r', encoding='utf-8') as infile, open('output.txt', 'w', encoding='utf-8') as outfile:
for line in infile:
if line.strip():
outfile.write(line)
Этот способ исключает необходимость хранения всего файла в памяти, что особенно важно при работе с файлами объемом сотни мегабайт и более. Он сохраняет порядок строк и корректно обрабатывает любые символы конца строки.
Для ускорения работы с очень большими файлами можно использовать буферизированное чтение через file.readline() или модуль fileinput, что позволяет дополнительно контролировать использование ресурсов и писать изменения напрямую на диск.
Вопрос-ответ:
Как удалить пустые строки из большого файла, чтобы не загружать его полностью в память?
Для работы с большими файлами стоит использовать построчное чтение. Открываете исходный файл для чтения и создаёте новый файл для записи. Затем проходите по каждой строке исходного файла, проверяете, что она не пустая или не содержит только пробелы, и записываете в новый файл. Такой подход позволяет обрабатывать файлы любого размера без риска переполнения памяти.
Можно ли удалить строки с пробелами и табуляциями так же просто, как полностью пустые строки?
Да. При проверке строки достаточно использовать метод strip(), который убирает все пробельные символы с начала и конца строки. Если после strip() строка оказывается пустой, её можно не записывать в файл. Этот способ работает одинаково для строк с пробелами, табуляциями и обычных пустых строк.
Как быстро удалить пустые строки при чтении файла построчно в Python?
Можно использовать генераторное выражение или функцию filter(). Например, открываете файл, читаем строки в цикле и перед записью проверяем, что строка не пустая: line.strip(). Вариант с filter(None, file) также работает, так как filter пропускает значения, которые Python трактует как ложные, включая пустые строки. Такой подход минимизирует использование дополнительной памяти.
Есть ли способ очистить файл от пустых строк без создания нового файла?
Да, можно открыть файл в режиме чтения-записи и считывать строки по очереди, собирая только непустые. После этого курсор возвращают в начало файла, очищают его методом truncate() и записывают отфильтрованные строки обратно. Этот способ требует аккуратности, так как работает с самим исходным файлом, и неправильная последовательность действий может привести к потере данных.