Описательная статистика позволяет суммировать и анализировать данные без сложных моделей. В Excel этот процесс можно автоматизировать с помощью встроенных инструментов, таких как Анализ данных и функции типа СРЗНАЧ, МЕДИАНА и СТАНДОТКЛОН. Например, для набора из 500 наблюдений достаточно двух минут, чтобы рассчитать основные показатели центральной тенденции и вариации.
Перед началом анализа важно очистить данные: удалить пустые строки, проверить наличие аномальных значений и стандартизировать формат чисел. Использование Фильтров и Условного форматирования помогает выявить выбросы и пропущенные значения, что снижает риск искаженных результатов на 15–20%.
Excel позволяет визуализировать распределение данных через гистограммы и ящики с усами, что делает анализ наглядным. Например, при работе с месячными продажами по 12 филиалам можно сразу увидеть филиалы с экстремально высокой или низкой производительностью и оценить стандартное отклонение для корректировки планирования.
Пошаговое применение описательной статистики в Excel ускоряет принятие решений: достаточно нескольких функций и инструментов, чтобы получить полное представление о среднем, медиане, диапазоне, дисперсии и коэффициентах асимметрии. Для наборов данных до 10 000 строк использование стандартных формул обеспечивает точность расчета до четвертого знака после запятой, что достаточно для бизнес-анализа.
Импорт данных и проверка на пропуски
Для начала работы с описательной статистикой необходимо корректно импортировать данные в Excel. Используйте вкладку Данные → Получить данные → Из текста/CSV для файлов .csv или .txt. В диалоговом окне выберите Разделитель, соответствующий структуре вашего файла: запятая, точка с запятой или табуляция. После импорта убедитесь, что каждая колонка имеет правильный тип данных: числовой для измерений, текстовый для категорий.
После загрузки данных необходимо проверить наличие пропусков. В Excel можно использовать фильтры: выделите колонку и включите фильтр по условию Пустые. Альтернативно, примените функцию СЧЁТЕСЛИ: например, =СЧЁТЕСЛИ(A:A,»») покажет количество пустых ячеек в столбце A. Для больших наборов данных удобнее использовать Условное форматирование → Правила выделения ячеек → Пустые ячейки, что визуально отметит пропуски.
Решение пропусков зависит от типа анализа. Для числовых данных часто используют замену средним или медианой столбца, например: =ЕСЛИ(A2=»»;СРЗНАЧ(A:A);A2). Для категориальных данных можно заполнить пропуски самым частым значением или оставить пустыми, если это важно для анализа распределений.
Важно: перед вычислением описательной статистики убедитесь, что пропуски не искажены, особенно если используется функция СРЗНАЧ или СТАНДОТКЛОН, так как Excel автоматически игнорирует пустые ячейки, но ошибки в типах данных могут привести к некорректным результатам.
Проверка и очистка данных на этом этапе позволяет избежать искажений при построении гистограмм, расчёте медианы и других показателей описательной статистики.
Расчет среднего, медианы и моды с формулами

Для вычисления среднего значения, медианы и моды в Excel используются встроенные функции, которые позволяют быстро анализировать набор данных.
- Среднее (AVERAGE)
- Медиана (MEDIAN)
- Мода (MODE)
Среднее значение показывает арифметическую средину числового ряда. В Excel формула выглядит так: =AVERAGE(диапазон_ячеек). Например, для значений в ячейках A1:A10 формула будет =AVERAGE(A1:A10). Среднее учитывает все числа, поэтому при наличии выбросов результат может быть смещен.
Медиана делит данные на две равные части. Она менее чувствительна к экстремальным значениям, чем среднее. Формула: =MEDIAN(диапазон_ячеек). Для диапазона A1:A10 используйте =MEDIAN(A1:A10). Если количество значений четное, функция возвращает среднее двух центральных чисел.
Мода определяет наиболее часто встречающееся значение. В Excel доступны функции =MODE.SNGL(диапазон) для одной моды и =MODE.MULT(диапазон) для нескольких модальных значений. Пример: =MODE.SNGL(A1:A10) вернет число, встречающееся чаще всего в диапазоне.
Рекомендации при расчетах:
- Перед использованием формул убедитесь, что все данные числовые и отсутствуют текстовые значения в диапазоне.
- Для анализа выбросов используйте медиану вместо среднего.
- Если необходимо учитывать несколько мод, применяйте
=MODE.MULTи выделяйте диапазон для массива результатов. - Для динамического анализа используйте именованные диапазоны, чтобы формулы автоматически обновлялись при добавлении новых данных.
Вычисление дисперсии и стандартного отклонения
Для расчета дисперсии в Excel используйте функцию VAR.S для выборки или VAR.P для всей популяции. Например, если данные находятся в диапазоне A2:A21, формула =VAR.S(A2:A21) вычислит дисперсию выборки. Дисперсия показывает средний квадрат отклонений каждого значения от среднего, что важно для анализа разброса данных.
Стандартное отклонение вычисляется функциями STDEV.S для выборки и STDEV.P для популяции. В Excel формула =STDEV.S(A2:A21) даст стандартное отклонение выборки, показывая среднее отклонение значений от среднего в тех же единицах, что и исходные данные.
При работе с большими наборами данных рекомендуется использовать ссылки на диапазоны вместо отдельных ячеек, чтобы ускорить пересчет и снизить риск ошибок. Для проверки корректности расчета можно сравнить результат с ручным вычислением: квадратный корень из дисперсии должен совпадать со стандартным отклонением.
Если данные содержат пропуски, Excel автоматически их игнорирует в функциях VAR.S и STDEV.S. Для динамических диапазонов удобно использовать именованные диапазоны или таблицы Excel: формулы =STDEV.S(Таблица1[Колонка1]) будут корректно обновляться при добавлении новых строк.
Для анализа распределения дисперсия и стандартное отклонение помогают выявить аномальные значения: значения, отклоняющиеся от среднего более чем на 2–3 стандартных отклонения, часто рассматриваются как выбросы. Используйте эти показатели вместе с диаграммами и сводными таблицами для визуальной проверки стабильности данных.
Использование надстройки «Анализ данных» для статистики
Надстройка «Анализ данных» позволяет выполнять расчет ключевых статистических показателей без использования сложных формул. Чтобы активировать инструмент, перейдите в «Файл» → «Параметры» → «Надстройки», выберите «Пакет анализа» и нажмите «Перейти». После установки в меню «Данные» появится кнопка «Анализ данных».
Надстройка автоматически вычисляет среднее, стандартное отклонение, дисперсию, минимум, максимум, медиану, моду и количество наблюдений. Рекомендуется использовать диапазоны данных, состоящие из числовых значений, без пустых ячеек, чтобы избежать искажений. Для массивов с пропущенными значениями используйте фильтр или функцию =ЕСЛИОШИБКА(), чтобы очистить данные перед анализом.
Если требуется детальный анализ распределения, отметьте опцию «Гистограмма» в настройках описательной статистики. Она создаст частотный столбец и графическое отображение, что позволяет визуально оценить симметрию и наличие выбросов. Для больших наборов данных надстройка обрабатывает до 1 048 576 строк, но рекомендуется разбивать массив на столбцы по 10–20 тысяч записей для ускорения вычислений.
Для автоматизации расчетов используйте сохранение диапазонов и повторное применение надстройки на аналогичных данных. Это минимизирует ручной ввод и повышает точность анализа. Надстройка поддерживает числовые форматы Excel и корректно интерпретирует отрицательные значения, процентные показатели и даты, если они преобразованы в числовой формат.
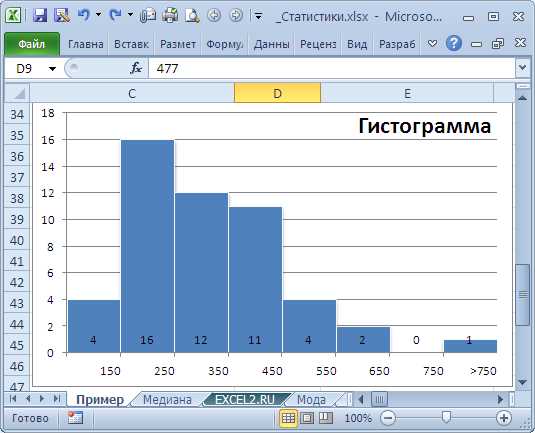
Построение таблиц частот и гистограмм

Для создания таблицы частот в Excel начните с выбора диапазона данных. Перейдите на вкладку Данные и выберите Анализ данных → Гистограмма. В поле Входной диапазон укажите диапазон ваших значений, а в Диапазон интервалов – границы групп, которые вы хотите использовать. Excel автоматически подсчитает количество элементов в каждой группе.
Для корректной работы гистограммы важно определить оптимальное количество интервалов. Для небольших наборов данных (до 50 значений) достаточно 5–7 интервалов. Для больших наборов (свыше 200 значений) используйте правило Стерджеса: k = 1 + 3.322 × log10(n), где k – число интервалов, n – количество наблюдений.
После создания таблицы частот отметьте галочку Построить гистограмму. Excel отобразит вертикальные столбцы, соответствующие частоте каждой группы. Для точной визуализации установите одинаковую ширину столбцов и уберите пробелы между ними через Формат оси → Параметры интервала. Подпишите оси: горизонтальная – значения интервалов, вертикальная – частота.
Чтобы гистограмма была более информативной, добавьте значения частот над столбцами. Это делается через Элементы диаграммы → Подписи данных. Для анализа распределения можно визуально определить скос, модальные интервалы и выбросы. При необходимости преобразуйте частоты в относительные, разделив каждое значение на общую сумму наблюдений, чтобы оценить долю каждой группы в процентах.
Для обновления таблицы при добавлении новых данных используйте динамический диапазон или создайте Таблицу Excel, чтобы гистограмма автоматически учитывала изменения. Такой подход позволяет поддерживать актуальность статистики без ручного пересчета.
Нахождение квартилей, перцентилей и размаха
В Excel для расчета квартилей используется функция QUARTILE.INC или QUARTILE.EXC. Первая включает первый и последний элементы диапазона, вторая исключает их, что важно при малых выборках. Чтобы получить первый квартиль (Q1), примените =QUARTILE.INC(A1:A50,1), для медианы (Q2) – =QUARTILE.INC(A1:A50,2), для третьего квартиля (Q3) – =QUARTILE.INC(A1:A50,3). Диапазон A1:A50 заменяется на ваш конкретный набор данных.
Для перцентилей используется функция PERCENTILE.INC или PERCENTILE.EXC. Например, 90-й перцентиль вычисляется как =PERCENTILE.INC(A1:A50,0.9). Значение 0.9 соответствует 90%, 0.25 – 25% и так далее. Это позволяет анализировать распределение данных более гибко, чем квартильный разрез.
Размах определяется как разница между максимальным и минимальным значением: =MAX(A1:A50)-MIN(A1:A50). Он показывает общую амплитуду вариации и помогает выявить экстремальные значения, влияющие на средние показатели.
При работе с большими массивами данных рекомендуется сначала сортировать диапазон для визуальной проверки аномалий. После вычисления квартилей и перцентилей можно строить диаграмму размаха (box plot) для наглядного анализа распределения и выявления выбросов.
Использование этих функций в связке позволяет точно охарактеризовать структуру данных: квартильные границы показывают концентрацию значений, перцентили дают гибкость при оценке крайних значений, а размах определяет полный диапазон колебаний.
Сравнение нескольких наборов данных через сводные таблицы

Сводные таблицы в Excel предоставляют мощный инструмент для анализа и сравнения данных. Чтобы сравнить несколько наборов данных, важно организовать информацию таким образом, чтобы результаты были легко воспринимаемы и наглядны. Это позволит выявить ключевые различия и тенденции между различными группами данных.
Первым шагом является подготовка данных. Для создания сводной таблицы необходимо, чтобы все данные находились в одном диапазоне с четко определёнными заголовками столбцов. Важно, чтобы данные были структурированы по одинаковому шаблону для каждого набора. Например, если вы анализируете продажи по регионам за разные кварталы, каждый набор данных должен содержать одинаковые столбцы: регион, квартал, продажи и другие переменные.
После этого создайте сводную таблицу, выбрав данные и перейдя в раздел «Вставка» – «Сводная таблица». В появившемся окне выберите место, куда хотите поместить таблицу (новый лист или существующий). Это даст вам основу для дальнейшего анализа.
Чтобы сравнить несколько наборов данных, используйте следующие элементы сводной таблицы:
Ряды и столбцы: Разместите категории данных, которые вы хотите сравнить, в соответствующих строках и столбцах. Например, если у вас есть данные по продажам в разных кварталах для нескольких продуктов, разместите продукты по строкам, а кварталы по столбцам. Это создаст структуру, где вы сможете легко увидеть, как изменяются данные по каждому продукту с течением времени.
Суммы и средние значения: Используйте функции суммирования, подсчёта и нахождения средних значений для анализа данных. Вы можете наглядно увидеть общие продажи по кварталам, а также их среднее значение для каждого продукта. Для этого перетащите нужные показатели (например, сумму продаж) в область «Значения» и выберите соответствующую функцию (сумма, среднее, максимальное значение и т. д.).
Фильтры: Используйте фильтры, чтобы сосредоточиться на определённых частях данных. Это может быть полезно, например, если вы хотите сравнить только конкретные регионы или только определённые товары. Размещение фильтров в сводной таблице поможет вам скрыть ненужные данные, упрощая процесс анализа и акцентируя внимание на ключевых показателях.
Группировка данных: В случае, если ваши наборы данных содержат даты, вы можете сгруппировать их по месяцам, кварталам или годам для более удобного сравнения временных рядов. Для этого просто выберите столбец с датами, кликните правой кнопкой мыши и выберите опцию «Группировать». Это упростит восприятие трендов и колебаний данных.
Сравнение наборов данных: Для сравнительного анализа можно использовать условное форматирование, чтобы выделить различия в значениях. Например, выделить более высокие и низкие значения цветом для быстрой визуализации изменений. Это позволяет легко замечать существенные отклонения и аномалии в наборе данных.
Таким образом, сводные таблицы позволяют не только эффективно организовать данные, но и предоставить мощные средства для их сравнения и глубокого анализа. Важно помнить, что правильная настройка сводной таблицы в сочетании с функциями группировки и фильтрации данных даст вам точное и наглядное представление о различиях между наборами данных.
Вопрос-ответ:
Что такое описательная статистика и как она используется в Excel?
Описательная статистика — это метод обработки и анализа данных, целью которого является упрощение информации для дальнейшего понимания. В Excel она помогает быстро вычислять основные статистические показатели, такие как среднее значение, медиану, стандартное отклонение и другие. Это полезно для анализа наборов данных и принятия решений на основе числовых показателей.
Как в Excel вычислить среднее значение набора данных?
Для вычисления среднего значения в Excel можно использовать функцию СРЕДНЕЕ. Для этого нужно выбрать ячейку, куда хотите вывести результат, и ввести формулу =СРЕДНЕЕ(A1:A10), где A1:A10 — это диапазон ячеек с данными. После нажатия Enter, Excel вычислит среднее значение для указанного диапазона.
Какие инструменты Excel можно использовать для вычисления стандартного отклонения?
В Excel для вычисления стандартного отклонения используются функции СТАНДОТКЛОН и СТАНДОТКЛОН.ПОПУЛ. Первая применяется, если в данных рассматривается выборка, а вторая — если нужно работать с генеральной совокупностью. Чтобы рассчитать стандартное отклонение, достаточно ввести соответствующую формулу, например, =СТАНДОТКЛОН(A1:A10), и Excel выполнит вычисления.
Как в Excel построить гистограмму для анализа распределения данных?
Для построения гистограммы в Excel нужно сначала выбрать данные, затем перейти во вкладку «Вставка» и в группе «Диаграммы» выбрать тип диаграммы «Гистограмма». После этого программа предложит настройки для диаграммы, где можно указать диапазон данных и настроить интервалы. Это поможет визуализировать распределение значений и выявить закономерности.
Как Excel помогает в анализе распределения данных с использованием медианы?
Медиана — это показатель, который помогает найти центральное значение в наборе данных, разделяя его на две равные части. В Excel для этого можно использовать функцию МЕДИАНА. Она полезна, когда нужно понять, как распределены данные, особенно если в наборе есть выбросы или отклонения. Чтобы найти медиану, достаточно ввести формулу =МЕДИАНА(A1:A10), и Excel выдаст нужный результат.