
Содержание статьи

Alphago – это искусственный интеллект, разработанный компанией DeepMind, способный обыгрывать профессиональных игроков в древнюю стратегическую игру Го. Он использует комбинацию глубоких нейронных сетей и обучения с подкреплением, что позволяет анализировать миллионы возможных ходов и выбирать оптимальные стратегии в режиме реального времени.
Программа изучает партии как профессионалов, так и себя саму, постепенно совершенствуя свои алгоритмы оценки позиций. Благодаря использованию партии обучения на базе исторических данных Го и симуляций собственных игр, Alphago демонстрирует ход мыслей, сопоставимый с решениями человека на уровне чемпионов мира.
Для игроков и исследователей Alphago предоставляет уникальные рекомендации по стратегическим подходам: например, как выстраивать контроль над центром доски или оценивать риски при захвате углов. Использование подобных алгоритмов может улучшить подготовку к турнирам и расширить понимание сложных игровых комбинаций.
Алгоритмы Alphago также применяются в задачах оптимизации и прогнозирования вне игрового контекста, что делает исследование его работы полезным для специалистов в области искусственного интеллекта, анализа данных и стратегического планирования.
Как Alphago обучается стратегии игры в Го

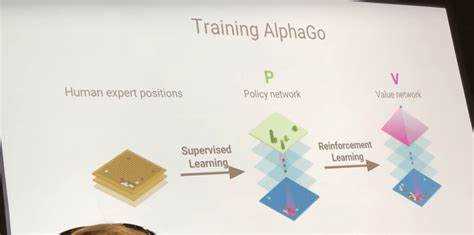
Обучение Alphago строится на двух ключевых методах: супервизируемое обучение и обучение с подкреплением. На первом этапе нейронная сеть анализирует более 30 миллионов исторических партий профессиональных игроков, сопоставляя каждый ход с вероятностью победы. Это позволяет модели сформировать базовое понимание стандартных стратегий и шаблонов.
На втором этапе Alphago играет миллионы игр против себя самой в симулированной среде. Каждая партия оценивается по итоговому результату: выигрыш или поражение. Алгоритм обновляет веса нейронной сети, усиливая ходы, которые приводят к победе, и уменьшая значимость менее успешных вариантов. Такой подход позволяет выявлять нестандартные комбинации и разрабатывать новые стратегии.
Для ускорения обучения используется метод Монте-Карло для прогнозирования исходов ходов. Alphago моделирует тысячи вариантов развития партии, выбирая оптимальные ходы на основе вероятности успеха. Практическая рекомендация для игроков: анализировать партии Alphago можно как руководство по оценке риска и построению атакующих комбинаций.
Обучение продолжается до достижения стабильного уровня игры, сопоставимого с чемпионами мира. Важно отметить, что система постоянно корректирует стратегию при появлении новых данных, что делает ее подход к Го адаптивным и динамичным, а не фиксированным набором шаблонов.
Технологии и алгоритмы, лежащие в основе Alphago

Alphago использует комбинацию глубоких нейронных сетей, поиска Монте-Карло и обучения с подкреплением для анализа партий и прогнозирования оптимальных ходов. Основная архитектура включает две сети: сеть политики для выбора хода и сеть ценности для оценки позиции на доске.
Сеть политики прогнозирует вероятность каждого возможного хода, а сеть ценности оценивает шансы на победу с текущей конфигурацией камней. Совместная работа этих сетей позволяет системе не только повторять известные стратегии, но и создавать новые комбинации, непредсказуемые для человека.
Поиск Монте-Карло используется для моделирования тысячи партий вперед. Каждый возможный ход исследуется с учетом вероятности успеха, что позволяет Alphago минимизировать риск потери территорий и эффективно планировать захваты углов и центра доски.
Ниже приведена таблица ключевых технологий и их функций:
| Технология | Функция |
|---|---|
| Глубокие нейронные сети | Анализ позиций, прогнозирование ходов, выявление стратегических паттернов |
| Сеть политики | Выбор наиболее вероятных успешных ходов |
| Сеть ценности | Оценка позиции и вероятности победы |
| Поиск Монте-Карло | Моделирование будущих ходов для стратегического планирования |
| Обучение с подкреплением | Усиление успешных стратегий через симуляции партий |
Практическая рекомендация для исследователей: использование аналогичных комбинаций сетей и поиска Монте-Карло может применяться для анализа сложных задач планирования, оптимизации ресурсов и стратегического прогнозирования в других областях.
Особенности нейронных сетей в Alphago
В основе Alphago работают две независимые нейронные сети: политика и ценность. Первая определяет вероятность выбора каждого хода, анализируя структуру доски из более чем тысячи входных признаков. Вторая оценивает текущую позицию, вычисляя вероятность победы без необходимости просчитывать всю партию до конца.
Архитектура сетей основана на сверточных слоях, что позволяет учитывать локальные комбинации камней и связи между группами. Такой подход помогает модели правильно оценивать ситуацию в плотных сегментах доски, где важны форма и стабильность групп.
Сеть политики обучается на профессиональных партиях и симулированных играх, что позволяет модели находить ходы, редко встречающиеся в практике. Сеть ценности обучается на результатах партий self-play, что дает возможность формировать независимые оценки сложных позиций.
Для изучения стратегий Го рекомендуется анализировать выходные данные обеих сетей. Это помогает игрокам понять, какие позиции модель считает устойчивыми, и какие ходы повышают вероятность контроля ключевых зон доски.
Как Alphago оценивает ходы и прогнозирует игру

Alphago сочетает работу сети политики, сети ценности и поиска Монте-Карло, что позволяет системе оценивать ходы не только по локальным выгодам, но и по их влиянию на исход партии. Такой подход помогает анализировать позиции с учетом долгосрочного результата.
Процесс оценки строится по двум основным направлениям:
- вероятностная оценка хода через сеть политики;
- расчет шанса победы через сеть ценности.
После предварительных оценок запускается поиск Монте-Карло, создающий тысячи виртуальных партий. На основе результатов симуляций система корректирует вероятности и обновляет оценки позиций.
Последовательность действий при прогнозировании выглядит следующим образом:
- Анализ конфигурации доски и выделение доступных ходов.
- Оценка каждого хода через сеть политики.
- Построение дерева поиска с использованием симуляций.
- Определение хода с наибольшей суммарной вероятностью успеха.
Игрокам полезно изучать вариации, предложенные Alphago, чтобы понимать, как малозаметные локальные решения влияют на структуру партии. Такой разбор помогает улучшить навыки планирования и избегать тактических просчетов.
История матчей Alphago с профессиональными игроками

Первое публичное испытание Alphago состоялось в 2015 году против южнокорейского профессионала Ли Седоля 9 дан. Матч завершился со счетом 4:1 в пользу системы. Победа привлекла внимание к новым стратегическим вариантам, которые ранее не применялись в профессиональных партиях.
В 2016 году состоялась встреча Alphago с европейским чемпионом Фань Хуем 2 дан. Система выиграла все пять партий. Игры показали, что программа уверенно работает в позициях, где профессионалы традиционно используют проверенные схемы. Некоторые ходы Alphago стали предметом анализа тренеров и игроков высокого уровня.
В 2017 году прошел матч против Кэ Цзе, одного из сильнейших игроков мира. Итог – 3:0 в пользу Alphago. Наиболее обсуждаемым стал первый поединок, где система выбрала позиционное давление вместо прямой борьбы за углы, что позже стало рассматриваться как модель оптимального распределения силы по всей доске.
Профессионалы используют разбор этих партий для анализа нестандартных решений: ранний контроль центра, отказ от жадных территориальных обменов, гибкие перестройки групп. Такие элементы помогают формировать новые подходы в тренировке и оценивать альтернативные пути развития позиции.
Влияние Alphago на развитие стратегических игр

Появление Alphago изменило подход к изучению стратегий в Го и других интеллектуальных играх. Анализ партий показал, что система способна находить решения, не основанные на классических схемах, что привело к пересмотру ряда теоретических положений. Игроки начали уделять больше внимания гибкости позиций и отказу от заранее зафиксированных шаблонов.
Успех Alphago стимулировал разработку моделей, способных изучать игровые процессы без предварительного набора правил. Это позволило использовать методы самообучения для создания систем, применимых в шахматах, сёги и других сложных играх. Разработчики тестируют аналогичные архитектуры для исследования поведения и прогнозирования результатов в условиях неопределённости.
Для тренеров и игроков ценной стала возможность изучать новые варианты, предложенные системой. Такие решения демонстрируют, как небольшие изменения в ранней стадии партии могут влиять на итоговый баланс. Разбор этих подходов помогает выстраивать тренировочные программы, ориентированные на широкий спектр позиций.
Исследователи рассматривают подход Alphago как основу для разработки алгоритмов, способных анализировать динамичные системы за пределами игр. Принципы обучения через симуляции и оценку множества сценариев применяются в задачах распределения ресурсов, управления рисками и моделирования поведения сложных структур.
Применение подходов Alphago вне Го
Методы, использованные в Alphago, применяются в задачах, где требуется анализировать большое число вариантов и прогнозировать последствия действий. Одним из ключевых направлений стало моделирование процессов в биологии: алгоритмы помогают выявлять структуру белков, оптимизируя поиск стабильных конфигураций.
В логистике подход self-play используется для формирования маршрутов с учетом ограничений, таких как загрузка транспорта, время доставки и изменения спроса. Система оценивает разные стратегии и уточняет решения на основе симуляций, что снижает число неоптимальных маршрутов.
Финансовые компании применяют методы оценки позиций, аналогичные сети ценности. Алгоритмы анализируют поведение активов, выявляют рисковые конфигурации и предлагают варианты перераспределения портфеля. Такой подход снижает вероятность непредвиденных потерь.
Для исследовательских задач подходит комбинация политики и симуляций. Она помогает в выборе стратегий при разработке лекарств, где нужно оценить множество потенциальных таргетов и уточнить перспективные направления работы. Такой механизм ускоряет отбор вариантов и уменьшает объем ручной проверки.
Ограничения и слабые стороны Alphago

Несмотря на высокие результаты, работа Alphago ограничена набором условий, на которые система была обучена. Модель не адаптируется к задачам с другими правилами без полного переобучения, поскольку механизмы оценки зависят от структуры Го.
Ключевые слабые стороны заметны в следующих аспектах:
- ограниченная интерпретируемость решений, что затрудняет анализ причин выбора хода;
- зависимость от больших вычислительных ресурсов для проведения симуляций;
- неспособность учитывать контекст, выходящий за рамки игровой доски;
- отсутствие понимания целей человека – все решения строятся на вероятностях, а не на концепциях;
- качественное снижение результата при неполных данных или изменённых правилах игры.
Для исследовательских проектов важно учитывать, что архитектура Alphago плохо переносится на задачи, где отсутствует чёткое правило оценки результата. Это делает применение модели ограниченным в системах, требующих обработки неоднозначных данных.
При использовании подходов Alphago в других областях рекомендуется заранее проводить тестирование на наборе сценариев с разной степенью неопределённости. Это помогает выявлять ситуации, в которых система принимает нестабильные решения и нуждается в дополнительной настройке.
Вопрос-ответ:
Как Alphago выбирает ход в сложной позиции, где профессионалы расходятся во мнениях?
Система комбинирует оценку сети политики и прогноз сети ценности. Затем запускается серия симуляций поиска Монте-Карло, где проверяются возможные ветви развития партии. Итоговое решение формируется на основе статистики успешных сценариев. Такой подход помогает находить ходы, которые не всегда очевидны для игроков, опирающихся на стандартные шаблоны.
Можно ли использовать подход Alphago для тренировки начинающих игроков?
Да, но с оговорками. Разбор партий позволяет увидеть нестандартные варианты, которые в обычной практике встречаются редко. Подходит методика изучения ключевых фрагментов партии: выбор направления атаки, оценка устойчивости групп, работа с центром. Для новичков полезно сравнивать свои ходы с рекомендациями системы, чтобы понять, какие решения уступают по стратегической ценности.
Почему Alphago играет партии между своими версиями и что это даёт?
Игры self-play позволяют модели собирать собственный массив данных, не ограничиваясь человеческим опытом. Такой метод помогает выявлять стратегии, которые не встречаются в профессиональных партиях. Каждая симуляция используется для обновления весов сети ценности и уточнения вероятностей в сети политики, что увеличивает качество оценки позиций.
Есть ли ограничения у поиска Монте-Карло, который применяет Alphago?
Основная сложность — зависимость от вычислительных ресурсов. Для точной оценки ходов требуется запускать тысячи симуляций, что увеличивает нагрузку на систему. Кроме того, метод хуже работает в ситуациях, где небольшое изменение позиции приводит к резкому изменению результата симуляции. В таких условиях приходится усиливать роль сети ценности, чтобы корректировать перекосы в расчётах.





