Содержание статьи

В pandas работа с датами начинается с корректного преобразования данных в тип datetime. Без этого большинство операций с датами, включая извлечение месяца, будут недоступны или приведут к ошибкам. Для строковых форматов даты рекомендуется использовать pd.to_datetime(), указав параметр format при необходимости точного соответствия шаблону.
Для получения номера месяца из столбца с датой применяется свойство dt.month. Оно возвращает целые числа от 1 до 12, что позволяет сразу использовать их для фильтрации, группировки или построения графиков. Если требуется текстовое представление месяца, применяется dt.strftime(‘%B’), который возвращает полное название месяца на языке системы.
При работе с большими таблицами важно заранее учитывать наличие пропусков и некорректных дат. Методы isna() и fillna() помогают идентифицировать и корректировать такие значения, предотвращая ошибки при последующем анализе.
Извлечённые месяцы удобно сохранять в отдельный столбец, что упрощает фильтрацию данных по месяцам и группировку для суммарных показателей. Такой подход позволяет, например, быстро подсчитать количество продаж или событий по каждому месяцу без дополнительных преобразований.
Преобразование строкового формата даты в datetime
Для работы с месяцами в pandas необходимо, чтобы данные имели тип datetime. Строковые форматы даты сначала преобразуются с помощью pd.to_datetime().
Примеры строковых форматов:
- «2025-11-16» – стандарт ISO, преобразуется без указания формата.
- «16/11/2025» – требуется параметр format=»%d/%m/%Y».
- «Nov 16, 2025» – преобразуется с format=»%b %d, %Y».
Рекомендации при преобразовании:
- Использовать errors=’coerce’ для автоматического перевода некорректных дат в NaT, что предотвращает ошибки при дальнейших операциях.
- Проверять наличие пропусков после преобразования с помощью isna().sum().
- При больших датасетах указывать format ускоряет обработку и снижает нагрузку на память.
После преобразования столбец с датами готов к извлечению месяца через dt.month или dt.strftime(), а также к фильтрации и группировке данных.
Получение номера месяца с помощью свойства dt.month
После преобразования столбца с датами в datetime получить номер месяца можно через свойство dt.month. Оно возвращает целые числа от 1 (январь) до 12 (декабрь), что удобно для фильтрации и анализа.
Пример создания нового столбца с месяцами:
df['месяц'] = df['дата'].dt.monthПрактические рекомендации:
- Для фильтрации данных за конкретный месяц используйте логические условия: df[df[‘дата’].dt.month == 11] – извлекает все строки с ноябрем.
- При объединении данных из нескольких источников убедитесь, что все даты преобразованы в тип datetime, иначе dt.month вернёт ошибку.
- Если требуется агрегация по месяцам, создайте столбец с номерами месяцев заранее – это ускоряет операции groupby и подсчёты.
Использование dt.month совместимо с методами fillna() и astype(int), что позволяет корректно обрабатывать пропущенные даты и конвертировать месяц в целый тип для анализа.
Извлечение названия месяца через dt.strftime
Для получения текстового названия месяца используется метод dt.strftime(‘%B’). Он преобразует дату в строку с полным названием месяца на языке системы. Это удобно для отчётов, визуализации и группировки по месяцу.
Пример создания нового столбца с названиями месяцев:
df['название_месяца'] = df['дата'].dt.strftime('%B')Рекомендации по использованию:
- Для сокращённых названий месяцев применяйте ‘%b’, например «Jan», «Feb».
- При объединении данных из разных источников убедитесь, что все даты имеют тип datetime.
- Используйте unique() для проверки всех присутствующих названий месяцев перед агрегацией или сортировкой.
Пример соответствия номера месяца и названия месяца:
| Номер месяца | Название месяца |
|---|---|
| 1 | January |
| 2 | February |
| 3 | March |
| 4 | April |
| 5 | May |
| 6 | June |
| 7 | July |
| 8 | August |
| 9 | September |
| 10 | October |
| 11 | November |
| 12 | December |
Фильтрация данных по конкретному месяцу
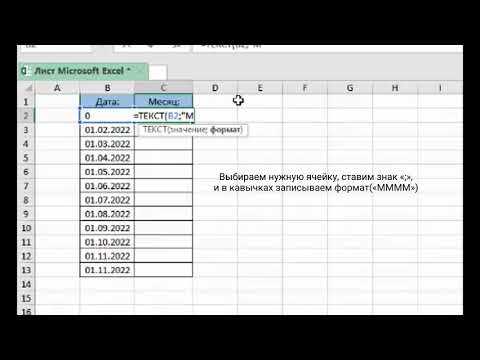
Для извлечения всех записей за определённый месяц используется логическое условие на столбец с датой или с отдельным столбцом месяца. Если столбец имеет тип datetime, применяется dt.month:
df_ноябрь = df[df['дата'].dt.month == 11]Если создан отдельный столбец с месяцами:
df_ноябрь = df[df['месяц'] == 11]Фильтрация по текстовым названиям месяцев через столбец с dt.strftime(‘%B’):
df_ноябрь = df[df['название_месяца'] == 'November']Рекомендации:
- Используйте copy(), если требуется сохранить фильтрованную таблицу отдельно от исходной: df_ноябрь = df[df[‘месяц’]==11].copy().
- Для фильтрации нескольких месяцев применяйте метод isin(): df[df[‘месяц’].isin([11,12])].
- Проверяйте наличие пропущенных дат в столбце с месяцами перед фильтрацией, чтобы избежать потери данных.
Создание нового столбца с месяцами из существующей даты
Новый столбец с месяцами облегчает фильтрацию, группировку и агрегацию данных. Для этого используется существующий столбец с типом datetime.
Пример добавления столбца с номерами месяцев:
df['месяц'] = df['дата'].dt.monthДля текстовых названий месяцев:
df['название_месяца'] = df['дата'].dt.strftime('%B')Рекомендации:
- Создавайте столбец до фильтрации и группировки, чтобы ускорить операции groupby.
- Используйте astype(int), если необходимо сохранить месяц как целое число для вычислений:
df['месяц'] = df['дата'].dt.month.astype(int)Обработка пропущенных и некорректных дат
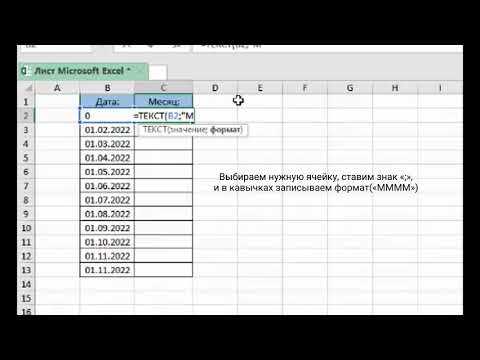
Пропущенные значения и некорректные даты мешают извлечению месяца и могут приводить к ошибкам при фильтрации и группировке. Для их обработки применяется параметр errors=’coerce’ в pd.to_datetime(), который переводит некорректные строки в NaT.
Пример преобразования с обработкой ошибок:
df['дата'] = pd.to_datetime(df['дата'], format='%d/%m/%Y', errors='coerce')Рекомендации по работе с пропусками:
- Проверяйте количество пропущенных дат с помощью df[‘дата’].isna().sum().
- Заполняйте пропуски значением по умолчанию для анализа по месяцам: df[‘дата’].fillna(pd.Timestamp(‘2025-01-01’), inplace=True).
- Или удаляйте строки с некорректными датами, если они не критичны для анализа: df.dropna(subset=[‘дата’], inplace=True).
- При создании нового столбца с месяцами учитывайте NaT, чтобы избежать ошибок при groupby или фильтрации: df[‘месяц’] = df[‘дата’].dt.month автоматически вернёт NaN для пропущенных значений.
Группировка данных по месяцу для анализа
Группировка по месяцу позволяет быстро получать суммарные показатели, сравнивать значения и строить отчёты. Для этого создайте отдельный столбец с номерами месяцев или названиями через dt.month или dt.strftime(‘%B’).
Пример группировки по номеру месяца с подсчётом количества записей:
df.groupby(df['дата'].dt.month).size()Пример группировки с суммой значений по месяцу:
df.groupby('месяц')['продажи'].sum()Рекомендации:
- Используйте sort_index() после группировки, чтобы месяцы шли в хронологическом порядке.
- Для текстовых названий месяцев добавляйте категориальный тип pd.Categorical с упорядоченными месяцами, чтобы groupby отражал правильную последовательность.
- Проверяйте наличие NaT в столбце с месяцами перед группировкой, чтобы исключить пустые строки из анализа.
- Если требуется объединение нескольких таблиц по месяцам, создавайте единый столбец с номерами месяцев для всех источников.
Сравнение нескольких столбцов с датами по месяцам
При работе с несколькими столбцами дат иногда требуется сравнить их по месяцам для выявления совпадений, задержек или сезонных закономерностей. Для этого удобно создавать отдельные столбцы с месяцами через dt.month или dt.strftime(‘%B’).
Пример сравнения двух столбцов с месяцами:
df['месяц_дата1'] = df['дата1'].dt.month
df['месяц_дата2'] = df['дата2'].dt.month
df['совпадение_месяцев'] = df['месяц_дата1'] == df['месяц_дата2']Рекомендации:
- Для текстовых названий используйте одинаковый формат через dt.strftime(‘%B’), чтобы сравнение было корректным.
- Обрабатывайте пропущенные значения (NaT) перед сравнением, иначе логические операции вернут False для пустых дат.
- При анализе нескольких столбцов создавайте отдельные столбцы с месяцами для каждого столбца, чтобы ускорить фильтрацию и группировку.
- Для агрегированных показателей можно применять groupby([‘месяц_дата1’, ‘месяц_дата2’]), чтобы изучить взаимодействие между месяцами разных событий.
Вопрос-ответ:
Как преобразовать столбец с датами в pandas, чтобы извлечь месяц?
Для извлечения месяца столбец с датами должен иметь тип datetime. Если дата хранится в строковом формате, примените pd.to_datetime(). Например: df[‘дата’] = pd.to_datetime(df[‘дата’], format=’%d/%m/%Y’, errors=’coerce’). После этого можно использовать df[‘дата’].dt.month для получения номера месяца или df[‘дата’].dt.strftime(‘%B’) для названия месяца.
Можно ли фильтровать данные сразу по названию месяца?
Да, если создать столбец с текстовыми названиями месяцев через dt.strftime(‘%B’). Например, df[‘название_месяца’] = df[‘дата’].dt.strftime(‘%B’). После этого можно фильтровать строки по конкретному месяцу: df[df[‘название_месяца’] == ‘November’].
Что делать с пропущенными или некорректными датами при извлечении месяца?
Некорректные строки можно преобразовать в NaT с помощью errors=’coerce’ в pd.to_datetime(). Пропуски проверяются через isna(). Их можно заполнить конкретной датой через fillna() или удалить строки с dropna(). Новый столбец с месяцами корректно обработает NaT, возвращая NaN вместо числа.
Как сравнивать месяцы в нескольких столбцах с датами?
Создайте отдельные столбцы с месяцами для каждого столбца даты через dt.month или dt.strftime(‘%B’). Затем используйте логическое сравнение: df[‘месяц_дата1’] == df[‘месяц_дата2’]. Для анализа зависимости между месяцами разных столбцов применяют groupby([‘месяц_дата1’, ‘месяц_дата2’]), что позволяет подсчитать количество совпадений или изучить сезонные различия.