Содержание статьи

Работа с матрицами является ключевым элементом при обработке числовых данных и научных вычислениях. В Python загрузка матрицы из файла позволяет сразу использовать готовые данные без ручного ввода, что особенно важно при работе с большими наборами данных.
Для текстовых файлов с разделителями, таких как CSV или TSV, модуль NumPy предоставляет функции numpy.loadtxt и numpy.genfromtxt, которые поддерживают указание разделителя, пропуск строк заголовка и автоматическое преобразование строк в числа с плавающей точкой.
При работе с таблицами Excel рекомендуется использовать библиотеку pandas. Функция pandas.read_excel позволяет выбрать конкретный лист, обрабатывать пропущенные значения и сразу получать данные в виде DataFrame, который легко преобразуется в массив NumPy для дальнейших вычислений.
Для бинарных файлов или сохранённых массивов NumPy полезна функция numpy.load. Она обеспечивает быструю загрузку больших матриц, минимизирует ошибки при чтении и сохраняет исходный формат данных.
При загрузке матрицы важно проверять соответствие размеров и типов данных, использовать astype для преобразования типов и применять фильтры для очистки некорректных или пропущенных значений. Эти меры предотвращают ошибки при последующих вычислениях и анализе.
Чтение матрицы из текстового файла с разделителями
Для загрузки матрицы из текстового файла с разделителями, такими как запятая, табуляция или пробел, в Python удобно использовать NumPy. Функция numpy.loadtxt позволяет указать разделитель через параметр delimiter и автоматически преобразует строки в числовой формат. Например, для CSV-файла с десятичными числами достаточно вызвать np.loadtxt(‘matrix.csv’, delimiter=’,’).
Если файл содержит пропущенные значения, рекомендуется использовать numpy.genfromtxt, который поддерживает параметр filling_values для подстановки значений по умолчанию. Также можно пропустить строки заголовка через skip_header, чтобы корректно считать только числовые данные.
Перед загрузкой важно проверить корректность разделителей в файле. Несоответствие разделителя приведет к ошибкам при разборе строк. Для файлов с нестандартными разделителями допустимо применять регулярные выражения или предварительно заменять разделители средствами Python, например с помощью метода str.replace.
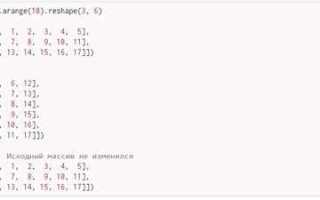
После загрузки матрицы рекомендуется проверить размер и форму массива через array.shape и при необходимости преобразовать тип данных с помощью astype для соответствия требованиям дальнейших вычислений.
Использование модуля NumPy для загрузки матрицы из CSV

Для работы с CSV-файлами, содержащими числовые данные, NumPy предоставляет удобные функции, позволяющие быстро получить массив для вычислений. Основные рекомендации:
- Использовать numpy.loadtxt для простых CSV без пропусков и заголовков: np.loadtxt(‘file.csv’, delimiter=’,’).
- Для файлов с пропущенными значениями или смешанными типами данных применять numpy.genfromtxt с параметрами delimiter=’,’ и filling_values=0.
- Если первая строка файла содержит заголовки, пропускать её через skip_header=1, чтобы загрузить только числовую матрицу.
- Проверять форму массива после загрузки с помощью array.shape и тип данных через array.dtype.
- При необходимости преобразовывать типы данных с помощью astype(np.float32) или astype(np.int64) для оптимизации памяти и совместимости с последующими операциями.
Дополнительно рекомендуется при больших файлах использовать параметр usecols для выбора конкретных столбцов, что сокращает объём загружаемых данных и ускоряет обработку.
Загрузка матрицы из файла Excel с помощью pandas
Для работы с матрицами в Excel-файлах удобно использовать библиотеку pandas. Функция pandas.read_excel позволяет загружать данные в DataFrame и сразу преобразовывать их в массив NumPy.
Рекомендации при загрузке матрицы из Excel:
- Указывать конкретный лист через параметр sheet_name=’Лист1′, чтобы избежать загрузки лишних данных.
- Пропускать строки заголовков или информационные строки через skiprows, если они не содержат числовую матрицу.
- Использовать usecols для выбора нужных столбцов, что уменьшает объём данных и ускоряет обработку.
- Обрабатывать пропущенные значения с помощью fillna(0) или другого подходящего значения перед конвертацией в массив NumPy.
- Преобразовывать DataFrame в NumPy-массив через df.to_numpy() для последующих вычислений и анализа.
При работе с большими таблицами рекомендуется загружать данные порциями с помощью параметра nrows и фильтровать строки по условиям, чтобы избежать избыточного использования памяти.
Обработка строк и преобразование данных в числовой формат
При загрузке матрицы из файлов часто встречаются данные в виде строк, которые необходимо преобразовать в числа. В Python это можно сделать с помощью встроенных функций и методов библиотек NumPy и pandas.
Рекомендации для обработки строк:
- Использовать метод str.strip() для удаления лишних пробелов и невидимых символов перед конвертацией.
- Применять float() или int() для преобразования отдельных значений, либо numpy.array(data, dtype=float) для целых массивов.
- При наличии пропущенных или некорректных значений применять pandas.to_numeric(errors=’coerce’) для преобразования с заменой неконвертируемых значений на NaN.
- Использовать fillna для подстановки числовых значений вместо NaN, чтобы сохранить форму матрицы.
- Для строк с разделителями внутри чисел, например «1,234», сначала заменять запятую на точку с помощью str.replace(‘,’, ‘.’), чтобы корректно преобразовать в float.
Проверять результат преобразования через array.dtype и убедиться, что все значения имеют нужный числовой тип перед дальнейшими вычислениями.
Работа с пропущенными значениями при загрузке матрицы
Пропущенные значения в матрицах могут возникать при чтении CSV, Excel или текстовых файлов. Их правильная обработка необходима для корректных вычислений.
Методы обработки пропусков в Python:
| Метод | Описание | Пример |
|---|---|---|
| Замена на константу | Подставить фиксированное значение вместо пропущенного, например 0 | df.fillna(0) |
| Среднее или медиана | Заполнить пропуск средним или медианным значением столбца | df.fillna(df.mean()) |
| Удаление строк или столбцов | Удалять строки с пропущенными значениями или столбцы с большим количеством пропусков | df.dropna(axis=0) |
| Интерполяция | Вычислить пропуски на основе соседних значений | df.interpolate() |
Для файлов CSV с пропусками в NumPy можно использовать genfromtxt(filling_values=0). Важно проверять форму матрицы и наличие NaN через numpy.isnan(array) перед дальнейшими вычислениями.
Чтение матрицы из бинарного файла с NumPy

Для быстрого и точного хранения больших матриц рекомендуется использовать бинарный формат .npy, который поддерживает библиотека NumPy. Файлы в этом формате сохраняют форму и тип данных массива, обеспечивая корректную загрузку без дополнительных преобразований.
Основные рекомендации при чтении бинарных файлов:
- Использовать функцию numpy.load(‘file.npy’) для загрузки массива с сохранением структуры и типа данных.
- Проверять форму массива после загрузки через array.shape, чтобы убедиться в корректности размеров матрицы.
- Если данные были сохранены с конкретным типом, например float32, убедиться, что при вычислениях используется совместимый тип для предотвращения ошибок переполнения или потери точности.
- Для работы с большими файлами можно использовать параметр mmap_mode=’r’ в numpy.load, что позволяет загружать данные по частям, не занимая всю оперативную память.
- Перед сохранением бинарного файла рекомендуется проверить, что матрица не содержит NaN или некорректных значений, чтобы избежать ошибок при последующей загрузке.
Сохранение загруженной матрицы для последующего использования
После загрузки и обработки матрицы важно сохранить её в формате, который позволит быстро восстановить данные без повторного парсинга исходного файла.
Рекомендации по сохранению:
- Для бинарного хранения и последующей быстрой загрузки использовать NumPy и функцию numpy.save(‘file.npy’, array), которая сохраняет форму и тип данных.
- Если требуется обмен данными с другими программами, использовать CSV через numpy.savetxt(‘file.csv’, array, delimiter=’,’) или pandas.DataFrame.to_csv(‘file.csv’, index=False).
- Для сохранения в Excel применять pandas: DataFrame.to_excel(‘file.xlsx’, index=False), что удобно для визуальной проверки и анализа.
- При работе с большими массивами рекомендуется сохранять их порциями или с использованием mmap для снижения нагрузки на память.
- Проверять корректность сохранённой матрицы, загружая её обратно через соответствующую функцию и сравнивая форму и тип данных с оригиналом.
Отладка ошибок при загрузке и проверка корректности данных
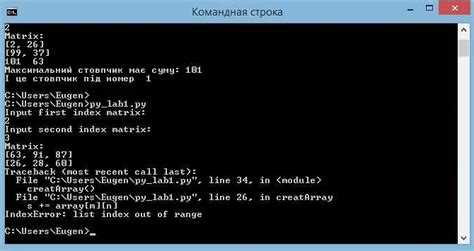
При загрузке матрицы из файлов часто возникают ошибки, связанные с несоответствием формата, типами данных или пропущенными значениями. Важно проводить систематическую проверку данных после каждой операции.
Основные шаги для отладки:
- Проверить наличие файла и корректность пути. Ошибка FileNotFoundError указывает на неверный путь или отсутствие файла.
- Убедиться в правильности разделителей в текстовых файлах. Несоответствие delimiter приводит к неправильному разбору строк.
- Проверить форму массива через array.shape после загрузки. Несоответствие ожидаемым размерам может указывать на пропуски или лишние строки.
- Проверять тип данных с помощью array.dtype и при необходимости преобразовывать через astype.
- Использовать функции numpy.isnan(array) и pandas.isnull(df) для выявления пропусков или некорректных значений.
- Логировать ошибки и предупреждения при загрузке с try-except для последующего анализа и корректировки данных.
Регулярная проверка размеров, типов и наличия пропущенных значений позволяет предотвратить ошибки на этапе анализа и вычислений, обеспечивая корректность работы с матрицей.
Вопрос-ответ:
Какие функции Python подходят для загрузки матрицы из текстового файла с разделителями?
Для загрузки матрицы из CSV, TSV или других текстовых файлов с разделителями подходят функции numpy.loadtxt и numpy.genfromtxt. loadtxt удобна для файлов без пропусков, где все значения числовые, а genfromtxt позволяет обрабатывать пропущенные значения через параметр filling_values и пропускать строки заголовков с skip_header.
Как загрузить матрицу из Excel-файла с помощью pandas?
Для чтения Excel-файлов используют функцию pandas.read_excel. Можно указать конкретный лист через параметр sheet_name, пропускать строки, не содержащие числовые данные, через skiprows, выбирать нужные столбцы через usecols. После загрузки DataFrame легко преобразуется в NumPy-массив через df.to_numpy() для дальнейших вычислений.
Как правильно обрабатывать строки с числами и пропущенные значения при загрузке матрицы?
Строки следует очищать с помощью str.strip() для удаления пробелов, а затем преобразовывать в числовой формат с помощью float() или int(). В DataFrame можно использовать pandas.to_numeric(errors=’coerce’) для замены неконвертируемых значений на NaN, а затем подставлять конкретные числа через fillna для сохранения формы матрицы.
Можно ли загружать большие матрицы из бинарных файлов без полного использования оперативной памяти?
Да, NumPy поддерживает загрузку больших бинарных массивов формата .npy с параметром mmap_mode=’r’. Это позволяет работать с массивом по частям, не загружая его полностью в память, что полезно при больших объёмах данных. После загрузки рекомендуется проверить форму массива через array.shape и тип данных через array.dtype.
Какие меры помогают проверить корректность матрицы после загрузки из файла?
После загрузки следует проверять размер массива с помощью array.shape, тип данных через array.dtype, наличие пропусков через numpy.isnan или pandas.isnull. Для выявления ошибок полезно логировать операции загрузки через try-except и сравнивать результаты с ожидаемыми размерами и типами данных, чтобы убедиться, что матрица готова к вычислениям.
Как загрузить матрицу из CSV-файла, если в нём есть пропущенные значения?
Для CSV-файлов с пропусками удобно использовать numpy.genfromtxt, указав параметр filling_values для подстановки значений по умолчанию. Также можно пропустить заголовки через skip_header. После загрузки рекомендуется проверить массив на наличие NaN через numpy.isnan и при необходимости заменить их с помощью методов NumPy или pandas.
Можно ли загрузить матрицу из Excel и сразу использовать её в числовых вычислениях?
Да, для этого используется библиотека pandas. Функция read_excel позволяет выбрать лист и нужные столбцы, пропустить строки с текстовыми данными через skiprows. После загрузки DataFrame легко преобразуется в NumPy-массив через df.to_numpy(), что позволяет сразу выполнять математические операции и анализ данных.