Содержание статьи

В библиотеках NumPy и pandas тип object появляется тогда, когда массив или столбец содержит неоднородные значения: строки вперемешку с числами, разные форматы дат, вложенные структуры или результаты ошибочной загрузки данных. Такой тип служит сигналом о том, что массив обрабатывается как набор Python-объектов, а не как компактная числовая структура.
Появление dtype object приводит к тому, что арифметические операции переходят на уровень интерпретатора Python, что заметно снижает скорость обработки. Даже простое суммирование может выполняться в десятки раз медленнее по сравнению с массивами с фиксированным типом. Поэтому важно на ранних этапах сборки и очистки данных проверять типы и отслеживать столбцы, которые неожиданно стали объектными.
Чтобы избежать нежелательного object-типа, полезно заранее задавать типы при чтении файлов, нормализовать строки, приводить данные к единому формату и проверять наличие нестандартных значений. Это упрощает преобразование столбцов в числа, даты или категории и обеспечивает корректную работу векторизованных операций.
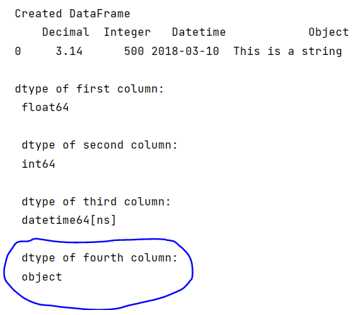
Как определить, что столбец в NumPy или pandas имеет dtype object
Проверка типа данных в массивах и таблицах позволяет сразу выявить столбцы, в которых содержатся Python-объекты вместо оптимизированных числовых или строковых представлений. Это помогает вовремя обнаружить проблемы с загрузкой или преобразованием данных.
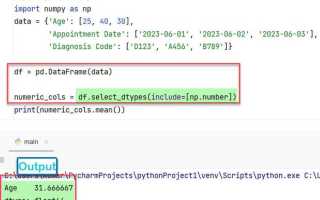
- Для pandas Series информация доступна через series.dtype. При значении object столбец обычно содержит смешанные типы, строковые данные или неконсистентные значения.
- Для DataFrame удобно использовать df.dtypes. Так можно быстро увидеть все столбцы с типом object и оценить масштаб проблемы.
Дополнительно стоит проверить фактические типы элементов:
- Вывести первые несколько значений и применить type() к каждому, чтобы выявить неожиданные форматы.
- Использовать df.applymap(type) или Series.map(type) на небольшом фрагменте данных, чтобы понять, какие типы смешаны.
Если столбец отображается как object, но должен быть числовым или датой, имеет смысл сразу проверить наличие пробелов, нестандартных разделителей, пустых строк, а также значений, которые невозможно привести к целевому типу.
Типичные причины появления dtype object при работе с массивами NumPy
В NumPy тип object возникает тогда, когда массив не может быть представлен как единая структура с фиксированным размером элемента. Это приводит к хранению ссылок на Python-объекты вместо плотного набора числовых значений.
Наиболее распространённая причина – смешанные типы в одном массиве. Если при создании массива присутствуют числа, строки, списки или булевы значения одновременно, NumPy выбирает наиболее гибкий вариант хранения, то есть object. Даже одно «лишнее» значение способно изменить тип всего массива.
Второй частый источник проблемы – разная длина вложенных структур. Например, список списков, где внутренняя длина отличается, не может быть преобразован в матрицу с единым размером элемента. В таких ситуациях NumPy автоматически формирует объектный массив.
Переход к типу object возможен и при загрузке данных из внешних источников. Если хотя бы один элемент содержит нестандартный символ, строковое представление числа или пустое значение, массив перестаёт быть числовым. Это происходит, например, при чтении CSV без предварительной очистки.
Иногда причина связана с ручным созданием массива через np.array() без указания параметра dtype. Если входные данные неоднородны, NumPy не выполняет преобразование к более строгому типу, а сохраняет объектный формат.
Как dtype object влияет на производительность операций в NumPy

Массивы с типом object теряют ключевое преимущество NumPy – выполнение операций на уровне машинных инструкций. Вместо векторизованных вычислений каждое действие выполняется через вызов Python-функций для отдельных элементов.
Основные последствия заметны уже при простых операциях:
- арифметика превращается в последовательный обход массива с обработкой объектов через интерпретатор;
- сравнения работают медленнее из-за вызовов Python-методов вместо прямого сравнения числовых значений;
- агрегации (sum, min, max) теряют оптимизацию и могут быть в десятки раз медленнее по сравнению с числовыми типами.
Дополнительная проблема заключается в снижении эффективности работы кэша процессора. Объекты хранятся разрозненно, ссылки указывают на различные области памяти, что нарушает последовательный доступ к данным и увеличивает количество пропущенных попаданий в кэш.
При обработке крупных массивов это приводит к существенному увеличению времени выполнения циклов, а использование параллельных вычислений становится ограниченным, так как операции над объектами не могут быть автоматизированы на низком уровне.
Чтобы избежать потерь производительности, рекомендуется заранее приводить данные к числовым или строковым типам и проверять структуру массивов перед выполнением ресурсоёмких операций.
Проверка и анализ содержимого массивов с dtype object
Анализ массивов с типом object требует прямой проверки значений, так как структура таких данных неоднородна. Простого просмотра dtype недостаточно, поэтому важно определить, какие типы фактически присутствуют в массиве и какие элементы вызывают несоответствие.
Первый шаг – выборка части массива. Просмотр нескольких десятков элементов позволяет быстро заметить строки, вложенные списки, нечисловые символы или значения, которые невозможно привести к ожидаемому типу. Полезно дополнительно применить type() к отдельным элементам, чтобы выявить различия.
Для более детального анализа стоит использовать генераторы или списковые выражения с вызовом type(x) для каждого элемента. Это помогает оценить распределение типов и определить, присутствуют ли единичные выбросы, нарушающие однородность.
При работе с многомерными объектными массивами важно проверить структуру каждого вложенного элемента. Если длины внутренних последовательностей различаются, NumPy не сможет представить данные как плотный массив, и тип object сохранится. В таких случаях необходимо привести вложенные данные к единому формату или изменить структуру.
Если массив содержит строковые представления чисел, даты в разных форматах или пустые значения, перед дальнейшей обработкой нужно выполнить нормализацию: удалить пробелы, унифицировать разделители, заменить пропуски. Это позволит привести массив к числовому или строковому типу и избавиться от объектных элементов.
Проблемы при арифметике и сравнении значений с dtype object

Массивы с типом object создают сложности при выполнении арифметики, так как NumPy вынужден передавать вычисления в интерпретатор Python. Любое действие превращается в последовательный вызов операторов для отдельных элементов, что исключает векторизацию и существенно замедляет обработку.
При сложении и умножении результат нередко зависит от фактических типов элементов. Строки не могут быть автоматически преобразованы к числам, вложенные списки вызывают ошибку при попытке выполнения операций, а значения с разным форматом могут приводить к несогласованному поведению. Например, строка вида «12» будет конкатенироваться с «3», а не складываться как числа.
Проблемы возникают и при сравнении. Обычные операции >, <, == работают через Python-методы для каждого элемента и возвращают результаты, зависящие от логики сравнения конкретного объекта. Сравнение чисел и строк в одном массиве может привести к ошибке, а сравнение строк с разными регистрами или кодировками даёт непредсказуемую сортировку.
В массивах с вложенными структурами сравнение может вовсе отсутствовать, если объект не реализует нужные методы. Это приводит к исключениям при попытке сортировки или фильтрации.
Чтобы избежать подобных ситуаций, рекомендуется привести данные к однородному типу перед арифметикой: конвертировать строки с числами через astype(float), заменить пустые значения, удалить элементы, которые не могут быть преобразованы. Это обеспечивает корректную работу операций и устраняет ошибки, вызванные неоднородностью данных.
Методы преобразования dtype object в числовые и строковые типы
Для работы с массивами NumPy или столбцами pandas, имеющими тип object, часто необходимо привести данные к числовым или строковым типам. Это позволяет ускорить вычисления и избежать ошибок при арифметике и сравнении.
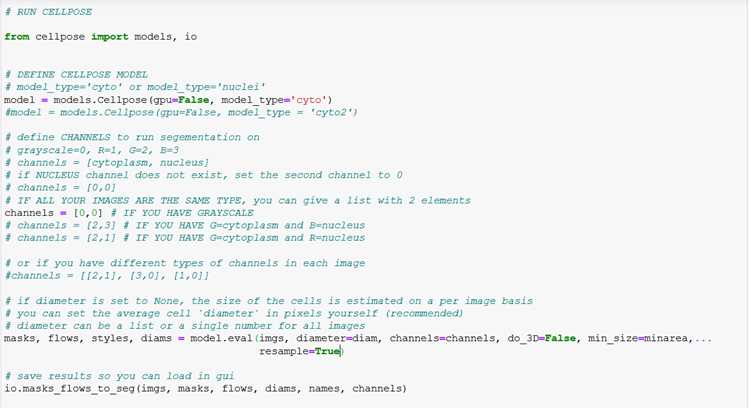
В NumPy преобразование выполняется через метод astype():
- array.astype(float) – конвертирует строковые числа и целые значения в формат float. Элементы, которые не удаётся преобразовать, вызывают исключение;
- array.astype(int) – преобразует значения в целые числа. Требует предварительной очистки от пустых строк и нечисловых элементов;
- array.astype(str) – гарантирует, что все элементы станут строками, полезно при работе с смешанными объектами.
В pandas преобразование столбцов object выполняется через pd.to_numeric() и astype():
- pd.to_numeric(series, errors=’coerce’) – преобразует значения в числа, некорректные элементы заменяются на NaN, что облегчает дальнейшую очистку;
- series.astype(‘int’) или series.astype(‘float’) – прямое приведение типов, требует предварительного удаления или замены пропусков;
- series.astype(str) – преобразует весь столбец в строки, сохраняя исходные значения и смешанные типы.
Перед преобразованием рекомендуется использовать методы очистки данных: удаление пробелов, унификация форматов дат и чисел, замена пустых значений, чтобы избежать ошибок и сохранить корректность вычислений.
Обработка смешанных значений и пропусков в столбцах с dtype object
Столбцы с типом object часто содержат смешанные значения: числа, строки, пустые элементы или специальные символы. Прямое преобразование в числовой тип без предварительной обработки вызывает ошибки и некорректные вычисления.
Основные методы обработки:
| Метод | Описание | Пример |
|---|---|---|
| Удаление некорректных элементов | Удаляются значения, которые не соответствуют целевому типу (например, строки в числовом столбце) | series = series[pd.to_numeric(series, errors=’coerce’).notna()] |
| Замена пропусков | Пустые строки, None или NaN заменяются на значение по умолчанию | series.fillna(0, inplace=True) |
| Унификация формата | Приведение строковых чисел к единому виду, удаление пробелов и лишних символов | series = series.str.replace(‘,’, ‘.’).str.strip() |
| Преобразование типов | После очистки выполняется конвертация в int или float | series = series.astype(float) |
Рекомендуется сначала провести анализ распределения типов в столбце через series.map(type).value_counts(), чтобы определить, какие значения требуют обработки, а затем применять методы очистки и приведения к единому типу. Это снижает вероятность ошибок при последующих вычислениях и упрощает работу с данными.
Практические способы избежать появления dtype object в данных
Для минимизации появления столбцов и массивов с типом object важно контролировать структуру и формат данных на ранних этапах обработки. Применение конкретных мер позволяет сохранить числовую или строковую однородность и ускорить вычисления.
Основные рекомендации:
- Задавать типы данных при создании массивов или загрузке файлов. В NumPy использовать параметр dtype при np.array(), в pandas – dtypes при read_csv() или read_excel().
- Проверять данные на наличие смешанных типов и строковых представлений чисел. Например, использовать pd.to_numeric(errors=’coerce’) для выявления неконвертируемых значений.
- Удалять или заменять пропуски и нестандартные элементы до приведения типов. Пустые строки, символы и None лучше заменить на NaN или значение по умолчанию.
- Унифицировать форматы строк и дат. Пробелы, разделители и символы валюты должны быть очищены до конвертации в числовой тип.
- При объединении массивов или DataFrame следить, чтобы элементы имели одинаковый тип. Даже один столбец с объектными значениями приведёт к преобразованию всего массива в object.
Систематическая проверка и нормализация данных до выполнения операций обеспечивает корректные вычисления и исключает неожиданные ошибки, связанные с dtype object.
Вопрос-ответ:
Что означает dtype object в Python и чем он отличается от числовых типов?
Тип object в Python, используемый в NumPy и pandas, обозначает массив или столбец, содержащий Python-объекты вместо фиксированного числового типа. В отличие от int или float, такие массивы могут содержать строки, списки, даты или смешанные значения, что делает их универсальными, но медленными при вычислениях.
Почему столбец в pandas автоматически получает dtype object при загрузке CSV?
При чтении CSV pandas анализирует содержимое столбца. Если присутствуют строки, пустые значения или элементы с разными форматами, библиотека присваивает тип object. Это предотвращает ошибки конверсии, но требует последующей очистки и приведения к нужному типу для числовых вычислений.
Как проверить, что массив NumPy имеет dtype object?
В NumPy тип массива можно определить через атрибут array.dtype. Если вывод содержит object, элементы представлены как Python-объекты. Для детального анализа можно проверить фактические типы элементов через type() на отдельных значениях или применить списковое выражение для всего массива.
Какие проблемы возникают при арифметических операциях с массивами dtype object?
Арифметические операции над массивами с типом object выполняются на уровне Python для каждого элемента. Это снижает скорость вычислений и может привести к ошибкам, если элементы имеют несогласованные типы: строки не преобразуются автоматически в числа, а вложенные структуры вызывают исключения.
Как правильно преобразовать столбец с dtype object в числовой тип?
В pandas можно использовать pd.to_numeric(series, errors=’coerce’), чтобы конвертировать значения в числа, при этом неконвертируемые элементы заменяются на NaN. В NumPy применяется array.astype(float) или array.astype(int) после очистки данных от строк и пустых значений. Перед этим важно унифицировать формат чисел и удалить лишние символы.
Почему при объединении массивов или DataFrame столбцы часто становятся dtype object?
При объединении массивов или столбцов pandas и NumPy анализируют типы всех входных данных. Если хотя бы один элемент имеет несоответствующий тип — например, строку среди чисел — библиотека присваивает всему столбцу тип object. Это обеспечивает корректное хранение всех значений, но снижает скорость операций и препятствует векторизации. Чтобы избежать этого, перед объединением следует привести все массивы к одинаковому типу и удалить или заменить элементы, которые не соответствуют требуемому формату.