Содержание статьи

Повторы в одном столбце Excel приводят к искажению итогов: завышаются суммы, неверно считаются уникальные клиенты, дублируются коды и идентификаторы. Типичные примеры – список заказов с повторяющимися номерами, база контактов с одинаковыми e-mail или реестр товаров с дублирующимися SKU. Для таких задач Excel предлагает несколько подходов, отличающихся по точности, скорости проверки и возможностям контроля результата.
Перед началом проверки важно определить что именно считать повтором: совпадение текста целиком, числовое равенство, игнорирование пробелов и регистра или сравнение после преобразований. Например, значения «Москва» и «МОСКВА» могут считаться одинаковыми или разными в зависимости от цели анализа. От этого выбора зависит инструмент – стандартная команда, формула или отдельный запрос.
Встроенные средства Excel позволяют быстро подсветить дубликаты прямо в таблице, не изменяя исходные данные. Такой подход удобен для визуального контроля и первичной проверки. Если требуется логический результат (например, метка «дубликат» в соседнем столбце), используются формулы, которые можно копировать на тысячи строк и комбинировать с фильтрами.
Для регулярной обработки больших массивов данных применяются более гибкие решения: расширенный фильтр, Power Query или макросы. Они подходят, когда источник обновляется, а правила поиска повторов должны соблюдаться автоматически. Понимание различий между этими способами помогает выбрать подходящий вариант под конкретную задачу и избежать ошибок при анализе данных.
Выделение повторов в столбце с помощью условного форматирования
Условное форматирование позволяет визуально отметить дубликаты в одном столбце без изменения значений. Инструмент работает на уровне отображения и подходит для проверки списков с любым типом данных: текст, числа, даты. Выделение применяется автоматически при добавлении новых строк в заданный диапазон.
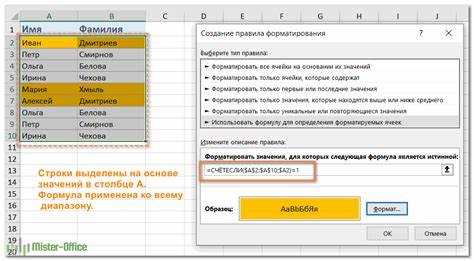
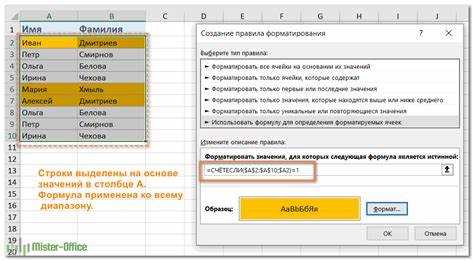
Для базового сценария выделите нужный столбец, откройте меню «Условное форматирование» → «Правила выделения ячеек» → «Повторяющиеся значения». В диалоге можно выбрать формат для повторов и уникальных значений. Excel считает повтором любое значение, встречающееся более одного раза в пределах выделенного диапазона.
Если требуется гибкий контроль, используйте правило с формулой. Это позволяет ограничить проверку конкретным столбцом, исключить пустые ячейки или учитывать только повторы, начиная со второго вхождения. Пример формулы для столбца A: =СЧЁТЕСЛИ($A:$A;A1)>1. Формула применяется ко всему диапазону и подсвечивает все дубликаты.
Для списков с заголовком важно начинать применение правила со второй строки, чтобы название столбца не участвовало в расчётах. Также рекомендуется фиксировать столбец знаком $, иначе при расширении диапазона правило будет работать некорректно.
| Задача | Тип правила | Особенность |
|---|---|---|
| Быстро найти все дубликаты | Готовое правило «Повторяющиеся значения» | Не требует формул, минимум настроек |
| Исключить пустые ячейки | Формула | Добавляется проверка A1<>»» |
| Подсветить только вторые и последующие повторы | Формула | Используется СЧЁТЕСЛИ с относительной строкой |
Условное форматирование не удаляет данные и не создаёт вспомогательных столбцов, поэтому его удобно применять для первичного контроля перед сортировкой, фильтрацией или очисткой таблицы.
Поиск дубликатов формулой СЧЁТЕСЛИ для одного столбца

Функция СЧЁТЕСЛИ позволяет определить дубликаты логически, а не визуально. Такой подход удобен, когда требуется получить признак повтора в отдельном столбце, использовать фильтрацию или включить проверку в расчёты. Формула анализирует количество вхождений каждого значения в заданном диапазоне.
Базовый вариант для столбца A со значениями, начиная со строки 2:
=СЧЁТЕСЛИ($A:$A;A2)
Результат – число, показывающее, сколько раз текущее значение встречается в столбце. Любое значение больше 1 указывает на наличие дубликата.
Чаще формулу используют в логическом виде, чтобы сразу получить понятный результат:
- =СЧЁТЕСЛИ($A:$A;A2)>1 – возвращает ИСТИНА для всех повторяющихся значений.
- =ЕСЛИ(СЧЁТЕСЛИ($A:$A;A2)>1;»Дубликат»;»») – помечает строки текстовой меткой.
Если требуется определить только второе и последующие вхождения, диапазон подсчёта ограничивают текущей строкой:
=СЧЁТЕСЛИ($A$2:A2;A2)>1
Такая формула считает количество появлений значения выше по столбцу и позволяет отличить первое вхождение от повторов.
Для корректной работы рекомендуется соблюдать следующие правила:
- Фиксировать столбец знаком $, чтобы диапазон не смещался при копировании.
- Исключать заголовок из диапазона подсчёта.
- Учитывать, что функция не различает регистр символов.
Формулы на основе СЧЁТЕСЛИ подходят для последующей сортировки, фильтрации и экспорта данных, когда требуется чёткое определение дубликатов в одном столбце.
Определение повторяющихся значений с учётом регистра символов

В задачах с паролями, токенами, серийными номерами и кодами доступа различие между «Ab12» и «ab12» критично. Стандартные функции Excel игнорируют регистр, поэтому для точного поиска повторов требуется явное сравнение символов.
Ключевым инструментом является функция СОВПАД, которая возвращает ИСТИНА только при полном совпадении текста, включая регистр и пробелы. Для подсчёта повторов её объединяют с функцией СУММ и логическим преобразованием.
Пример формулы для диапазона A2:A100:
=СУММ(—СОВПАД(A2;$A$2:$A$100))>1
Формула поэлементно сравнивает значение в строке с остальными ячейками столбца и подсчитывает точные совпадения. Если найдено более одного совпадения, значение считается повторяющимся с учётом регистра.
Чтобы определить только повторные появления, исключив первое вхождение, используется ограниченный диапазон:
=СУММ(—СОВПАД(A2;$A$2:A2))>1
Такой вариант подходит для маркировки строк и последующей фильтрации данных без изменения исходных значений.
При работе с этими формулами следует учитывать:
• вычисления выполняются по массиву и нагружают пересчёт при большом числе строк;
• различия в пробелах в начале и конце строки приводят к разным результатам;
• числа предварительно приводятся к тексту, если требуется контроль регистра.
Поиск повторов с учётом регистра оправдан в сценариях, где любое автоматическое преобразование текста может привести к логической ошибке.
Отбор строк с повторами через расширенный фильтр

Расширенный фильтр позволяет извлечь строки с повторяющимися значениями без формул и условного форматирования. Метод удобен, когда требуется получить отдельный список дубликатов для проверки или передачи, не затрагивая исходную таблицу.
Для работы таблица должна иметь заголовок столбца. Сначала создаётся вспомогательная область условий, в которой заголовок копируется точно, включая регистр и пробелы. Под ним оставляется пустая ячейка – это обязательное условие корректной работы фильтра.
В меню «Данные» выбирается команда «Дополнительно». В поле диапазона списка указывается исходный столбец, в поле диапазона условий – подготовленная область. При включении опции «Скопировать результат в другое место» Excel формирует отдельный список значений, встречающихся более одного раза.
Если необходимо получить строки целиком, а не только значения столбца, диапазон списка расширяют на всю таблицу. В этом случае в диапазоне условий указывается только проверяемый столбец, а остальные остаются пустыми.
Важно учитывать особенности метода:
• расширенный фильтр не подсвечивает дубликаты, а формирует выборку;
• сравнение выполняется без учёта регистра символов;
• при изменении исходных данных фильтр требуется запускать повторно.
Отбор через расширенный фильтр подходит для разовых проверок и формирования отчётов, где нужен отдельный список строк с повторами без дополнительных вычислений внутри таблицы.
Отличие поиска дубликатов от удаления повторяющихся значений

Поиск дубликатов и удаление повторяющихся значений решают разные задачи, хотя в интерфейсе Excel они находятся рядом. Поиск направлен на выявление и анализ совпадений, а удаление – на физическое изменение структуры данных. Смешение этих операций часто приводит к потере информации.
При поиске дубликатов данные остаются неизменными. Используются условное форматирование, формулы или фильтры, которые показывают, где и сколько раз встречается значение. Такой подход нужен для проверки корректности ввода, анализа источников повторов и принятия решения о дальнейших действиях.
Удаление повторяющихся значений работает иначе. Команда «Удалить дубликаты» оставляет только первое вхождение значения в выбранном столбце или наборе столбцов, а все остальные строки безвозвратно удаляет. Excel не учитывает контекст строк и не показывает, какие записи будут исключены до выполнения операции.
Ключевые различия между этими подходами:
• поиск сохраняет все строки и позволяет отфильтровать или пометить повторы;
• удаление изменяет таблицу и сокращает количество строк;
• поиск подходит для анализа, удаление – для финальной очистки.
Перед удалением рекомендуется всегда сначала выполнить поиск и проверить список повторов. Это позволяет убедиться, что совпадения действительно лишние, а не отражают разные записи с одинаковыми значениями в одном столбце.
Нахождение повторов в столбце через Power Query
Power Query используется, когда данные регулярно обновляются и поиск повторов должен выполняться автоматически при каждом обновлении. В отличие от формул, результат формируется в отдельном запросе и не зависит от пересчёта листа.
Для начала диапазон преобразуется в таблицу и загружается в редактор Power Query через команду «Из таблицы/диапазона». В редакторе выбирается столбец, в котором требуется найти повторы, после чего применяется группировка.
В окне «Группировать по» в качестве поля группировки указывается проверяемый столбец, а в качестве операции – «Количество строк». Полученный столбец показывает, сколько раз каждое значение встречается в исходных данных.
Значения с количеством больше единицы считаются повторяющимися. Для отбора таких строк используется фильтр по столбцу с количеством. При необходимости исходные строки восстанавливаются через объединение с первоначальной таблицей по проверяемому столбцу.
Особенности подхода:
• сравнение выполняется без учёта регистра символов;
• пустые значения учитываются как отдельная группа;
• результат обновляется одной командой «Обновить».
Power Query подходит для работы с большими объёмами данных и сценариев, где требуется стабильный механизм поиска повторов без вмешательства в исходный лист Excel.
Вопрос-ответ:
Почему Excel показывает дубликаты, хотя значения визуально отличаются?
Чаще всего причина связана с пробелами, скрытыми символами или форматом данных. Значения «ABC» и «ABC » выглядят одинаково, но Excel считает их разными. Проверка через функцию ДЛСТР помогает выявить лишние символы, а функция СЖПРОБЕЛЫ — привести текст к одному виду.
Можно ли найти повторы в столбце и при этом сохранить все строки?
Да, для этого используют условное форматирование, формулы СЧЁТЕСЛИ или Power Query. Эти способы помечают или отбирают дубликаты, не удаляя данные. Такой подход подходит для анализа и проверки перед очисткой таблицы.
Как определить только вторые и последующие повторы, а не первое вхождение?
Для этой задачи применяют формулу с ограниченным диапазоном, например =СЧЁТЕСЛИ($A$2:A2;A2)>1. Она считает количество появлений значения выше текущей строки и возвращает признак повтора только для следующих совпадений.
Почему поиск дубликатов не учитывает регистр букв?
Большинство стандартных инструментов Excel сравнивают текст без различия между заглавными и строчными символами. Для точного сравнения применяют функцию СОВПАД в массивных формулах, где регистр и пробелы становятся частью проверки.
Как работать с повторами, если данные регулярно обновляются?
В таких случаях используют Power Query. Запрос сохраняет шаги обработки, а при обновлении данных поиск повторов выполняется автоматически. Это удобно для отчётов и загрузок из внешних источников.