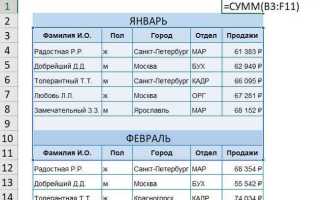
В Excel текст может находиться в любой ячейке, но его присутствие часто влияет на расчёты и функции. Например, числа, записанные как текст, не участвуют в суммировании или средних значениях, что может привести к ошибкам в финансовых отчётах. Использование функции ISTEXT() позволяет быстро определить, какие ячейки содержат именно текст, а не числовые данные или даты.
Кроме явного текста, в ячейках часто встречаются скрытые символы: пробелы в начале или конце, неразрывные пробелы, табуляции. Они могут блокировать корректное применение функций поиска или фильтров. Применение TRIM() и CLEAN() помогает удалить лишние символы и подготовить данные к обработке.
Отдельно стоит выделить текст, встроенный в формулы или ссылки. Ячейки с такими формулами выглядят как числа, но на самом деле содержат строки. Проверка через функции анализа формул и использование Find & Replace с поиском по типу данных позволяет выявить подобные элементы и избежать ошибок при автоматической обработке данных.
Наконец, при работе с большими таблицами важно быстро визуализировать текстовые данные. Условное форматирование с настройкой по типу данных или цветовой кодировкой ячеек позволяет сразу видеть текстовые элементы, отличающиеся от числовых, что упрощает контроль и очистку данных.
Определение текстовых ячеек с помощью функции ISTEXT

Примеры использования функции:
- =ISTEXT(A1) – проверяет, является ли содержимое ячейки A1 текстом.
- =ISTEXT(B2:C10) – массивная проверка диапазона для выявления текстовых элементов.
Функция особенно эффективна при комбинировании с условным форматированием. Это позволяет автоматически выделять текстовые ячейки в таблицах с большим количеством данных.
Рекомендации по применению:
- Использовать в формулах контроля качества данных перед расчётами.
- Объединять с функциями IF() или COUNTIF() для подсчёта или фильтрации текстовых ячеек.
- Проверять импортированные данные: часто числа из внешних источников поступают как текст, и ISTEXT() помогает выявить такие ошибки.
Для автоматической очистки текстовых ошибок рекомендуется комбинировать ISTEXT() с VALUE() для преобразования чисел, записанных как текст, и с TRIM() для удаления лишних пробелов.
Распознавание чисел, записанных как текст, и их исправление

В Excel часто встречаются числа, сохранённые как текст. Такие ячейки блокируют математические операции: функции SUM(), AVERAGE() и другие игнорируют их. Признаками чисел, записанных как текст, служат:
- выравнивание по левому краю по умолчанию;
- зелёный треугольник в верхнем левом углу ячейки;
- невозможность участвовать в арифметических вычислениях.
Методы исправления:
- Использование команды «Преобразовать в число»: выбрать ячейку с треугольником и нажать появившуюся кнопку с предупреждением.
- Функция VALUE(): =VALUE(A1) преобразует текстовое число в настоящий числовой формат.
- Математическая операция с 1: =A1*1 также превращает текстовое число в число.
Для массовой очистки диапазона рекомендуется использовать Paste Special → Multiply: вводим 1 в пустую ячейку, копируем её, выделяем диапазон чисел как текст и выполняем «Специальная вставка → Умножить». Это быстро исправляет все текстовые числа без изменения формата остальных данных.
Регулярная проверка данных с помощью ISTEXT() перед расчётами позволяет выявить подобные ошибки до построения формул, сокращая время на исправление ошибок в отчётах.
Выявление текстовых формул и ссылок в таблице
В Excel иногда формулы и ссылки записываются как текст, что препятствует их вычислению. Например, ячейка ‘=SUM(A1:A5) выглядит как формула, но возвращает текст. Такие элементы нарушают автоматические расчёты и могут скрывать ошибки в таблице.
Признаки текстовых формул и ссылок:
- отображение символа равенства = как обычного текста;
- выравнивание по левому краю, даже при настройках числового формата;
- функции не выполняются при вводе в соседние формулы.
Методы выявления и исправления:
- Использовать ISTEXT() для проверки ячеек, которые должны содержать формулы.
- Проверять Show Formulas в меню «Формулы» для визуального анализа всех формул как текста.
- Удалять лишние апострофы ‘ в начале ячеек вручную или с помощью функции REPLACE().
- Использовать Paste → Values только после исправления, чтобы сохранить вычисленные результаты, а не текстовые формулы.
Регулярная проверка ссылок и формул предотвращает накопление скрытых текстовых ошибок, особенно в больших таблицах с динамическими данными.
Использование условного форматирования для подсветки текста

Условное форматирование в Excel позволяет визуально выделять текстовые ячейки среди числовых данных. Это ускоряет проверку и очистку таблиц, особенно при больших объёмах информации.
Применение пошагово:
- Выделите диапазон, который нужно проверить.
- Перейдите в Главная → Условное форматирование → Создать правило.
- Выберите правило «Использовать формулу для определения форматируемых ячеек» и введите формулу =ISTEXT(A1), заменяя A1 на верхнюю левую ячейку диапазона.
- Настройте цвет заливки или шрифта для визуального выделения текста.
- Подтвердите изменения, и все текстовые ячейки будут подсвечены автоматически.
Дополнительные рекомендации:
- Использовать разные цвета для чисел, текста и ошибок для быстрого анализа таблицы.
- Сочетать условное форматирование с фильтрацией для мгновенного поиска текстовых элементов.
- Регулярно проверять новые данные: форматирование автоматически применяется к добавленным строкам, если диапазон обновлён.
Условное форматирование помогает выявить текст, который может блокировать вычисления, а также ускоряет подготовку данных к сводным таблицам и отчётам.
Автоматическое разделение текста и чисел в одной ячейке
В Excel часто встречаются ячейки, где текст и числа объединены, например «Заказ123» или «Товар45шт». Такие ячейки затрудняют фильтрацию, суммирование и анализ данных. Разделение компонентов упрощает обработку и подготовку к вычислениям.
Методы разделения:
- Функции TEXTBEFORE() и TEXTAFTER(): позволяют извлечь текст до или после числовой последовательности. Пример: =TEXTBEFORE(A1,»123″) выделит «Заказ».
- Комбинация LEFT(), RIGHT() и FIND(): для динамического извлечения частей строки без знания точного разделителя.
- Функция FILTERXML() с шаблоном для выделения цифр и текста в сложных случаях, когда стандартные функции не подходят.
Дополнительные рекомендации:
- Использовать VALUE() для преобразования извлечённых чисел в числовой формат.
- Проверять результат с ISTEXT() и ISNUMBER(), чтобы убедиться, что данные корректно разделены.
- Для массовой обработки большого диапазона применять формулы в смежных столбцах и после проверки переносить данные обратно с помощью Paste Values.
Автоматическое разделение текста и чисел минимизирует ошибки при подсчётах, фильтрации и построении сводных таблиц, повышая точность анализа.
Проверка скрытых символов и пробелов в текстовых данных
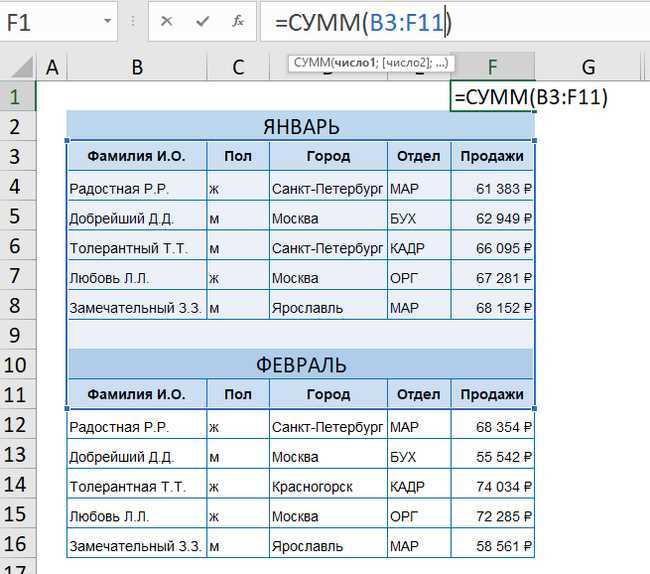
В текстовых ячейках Excel часто присутствуют невидимые символы: пробелы в начале и конце строки, неразрывные пробелы, табуляции или символы переноса строки. Они препятствуют корректной фильтрации, сортировке и использованию функций поиска.
Методы выявления скрытых символов:
- Функция LEN() позволяет сравнить длину текста до и после удаления пробелов.
- Функция CODE(MID()) помогает определить код каждого символа, выявляя нестандартные или невидимые элементы.
- Использование TRIM() удаляет все лишние пробелы, кроме одиночных между словами.
- Функция CLEAN() удаляет невидимые управляющие символы, включая разрывы строк и символы ASCII с кодами 0–31.
Практические рекомендации:
- Применять TRIM() и CLEAN() сразу после импорта данных из внешних источников.
- Комбинировать с ISTEXT() для проверки, что результат остаётся текстом, а не преобразован в пустую ячейку.
- Использовать проверку через Conditional Formatting для визуального выявления ячеек с лишними пробелами или необычными символами.
Регулярная очистка скрытых символов снижает ошибки при вычислениях, объединении данных и построении отчётов, обеспечивая точность обработки таблиц.
Вопрос-ответ:
Как быстро определить, какие ячейки в Excel содержат текст, а не числа?
Для проверки используйте функцию ISTEXT(). Она возвращает TRUE для текстовых значений и FALSE для чисел, дат или логических значений. Например, =ISTEXT(A1) покажет, является ли содержимое ячейки A1 текстом. Если нужно проверить диапазон, формулу можно протянуть по всем ячейкам, чтобы визуально выделить текстовые элементы.
Почему числа, введённые как текст, не участвуют в суммировании?
Excel воспринимает числа в текстовом формате как строку. Функции вроде SUM() или AVERAGE() пропускают такие ячейки, так как они не распознаются как числовые данные. Чтобы исправить это, можно использовать команду «Преобразовать в число», умножить значение на 1 или применить VALUE(), что переводит текст в число.
Как выявить формулы, которые отображаются как текст?
Если в ячейке формула отображается буквально, например ‘=SUM(A1:A5), она записана как текст. Чтобы найти такие случаи, применяют ISTEXT() к ячейкам с формулами. Также можно включить режим Show Formulas в меню «Формулы», который показывает все формулы как текст, облегчая поиск и исправление.
Какие способы есть для разделения текста и чисел в одной ячейке?
Для разделения используют функции TEXTBEFORE() и TEXTAFTER() для извлечения текста или чисел по известным разделителям. В более сложных случаях применяют комбинацию LEFT(), RIGHT() и FIND() для динамического выделения частей строки. После извлечения чисел рекомендуется использовать VALUE() для преобразования в числовой формат.
Как удалить скрытые пробелы и невидимые символы из текстовых ячеек?
Для очистки используют функции TRIM() и CLEAN(). TRIM() убирает лишние пробелы в начале и конце текста, а CLEAN() удаляет управляющие символы и разрывы строк. После обработки рекомендуется проверять результат с ISTEXT() и ISNUMBER(), чтобы убедиться, что данные корректно разделены и готовы к вычислениям.