В Java тип char хранит один символ в формате UTF-16, что делает его числовым значением в диапазоне от 0 до 65535. Любое сравнение символов выполняется на уровне кодовых точек, а не визуального представления. Поэтому результат операций зависит от позиции символа в таблице Unicode, а не от языка или алфавита, к которому он относится.
Операторы сравнения (==, !=, <, >) работают напрямую с примитивным значением char и подходят для проверок диапазонов, фильтрации символов и разбора текстовых потоков. Например, условие для определения цифры опирается на непрерывный диапазон кодов от ‘0’ до ‘9’, а не на строковые операции.
Методы класса Character применяются в ситуациях, где требуется дополнительная логика: сравнение объектов-оберток, преобразование регистра или учет особенностей буквенных символов. Использование Character.compare и compareTo позволяет унифицировать сравнение при работе с коллекциями и дженериками, где примитивы недоступны.
Непонимание различий между char и Character часто приводит к ошибкам при использовании equals и автоупаковки. Рекомендуется явно выбирать операторы для примитивов и методы для объектов, а также помнить, что сравнение символов разных регистров требует предварительного приведения через toLowerCase или toUpperCase.
Сравнение char в Java: операторы и методы
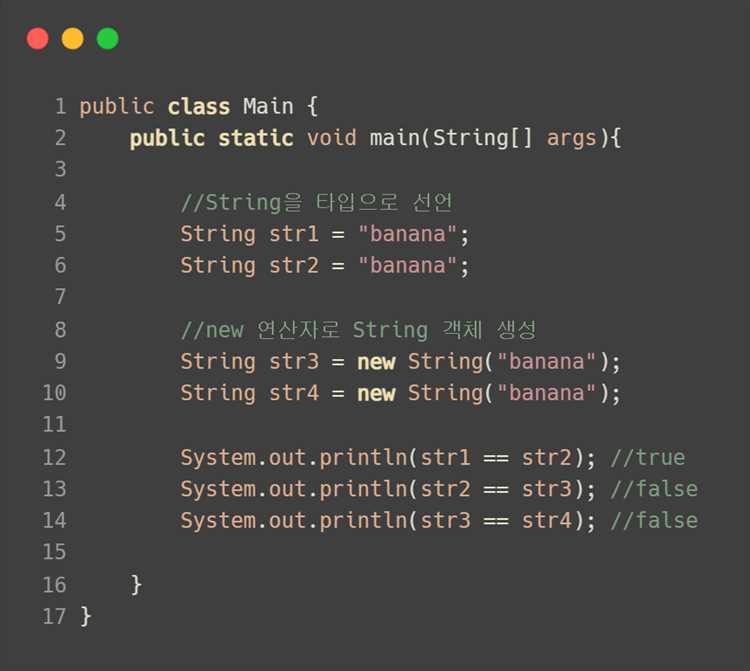
В Java сравнение значений типа char основано на их числовом представлении в кодировке UTF-16. Операторы == и != проверяют совпадение кодов символов без каких-либо преобразований, поэтому сравнение ‘A’ и ‘a’ всегда возвращает ложь. Такой подход подходит для строгих проверок управляющих символов, разделителей и фиксированных маркеров.
Операторы <, >, <= и >= позволяют определять порядок символов по их позиции в Unicode. Это используется при проверке диапазонов, например для фильтрации латинских букв или цифр. Следует учитывать, что кириллица, латиница и спецсимволы находятся в разных блоках, поэтому сравнение символов разных алфавитов не отражает языковой логики.
При работе с объектами Character рекомендуется применять метод Character.compare, который возвращает отрицательное, нулевое или положительное значение в зависимости от порядка аргументов. Этот метод удобен в компараторах и при сортировке коллекций, где прямое использование операторов недоступно.
Метод compareTo у класса Character выполняет аналогичную задачу, но требует учета автоупаковки примитивов. Для сравнения объектов нельзя использовать оператор ==, так как он проверяет ссылки, а не значения. В таких случаях следует опираться на equals или специализированные методы сравнения.
Если требуется игнорировать регистр, сравнение должно предваряться преобразованием символов через Character.toLowerCase или Character.toUpperCase. Эти методы работают на уровне Unicode и корректно обрабатывают большинство буквенных символов, что делает их предпочтительными по сравнению с арифметическими манипуляциями над кодами.
Использование оператора == для сравнения значений char

Оператор == при сравнении значений типа char сопоставляет их числовые коды в диапазоне от 0 до 65535. Он не учитывает алфавит, регистр или визуальное сходство символов. Например, символы ‘1’ и 1 имеют разные коды и никогда не будут равны, даже если логически воспринимаются как одно и то же значение.
Сравнение через == корректно применять при проверке конкретных символов: разделителей, управляющих знаков, одиночных маркеров протоколов или форматов данных. Проверка вида c == ‘\n’ или c == ‘;’ выполняется за одну операцию и не требует дополнительных преобразований.
Оператор не выполняет автоупаковку и работает только с примитивами. Если одна из сторон выражения имеет тип Character, происходит распаковка в char, после чего сравниваются значения. Это поведение безопасно при ненулевых ссылках, но при возможном значении null приводит к исключению, что следует учитывать при обработке входных данных.
Сравнение символов разных регистров через == допустимо только после явного преобразования регистра. Для этого рекомендуется использовать Character.toLowerCase или Character.toUpperCase, а не арифметические смещения кодов, так как последние корректны лишь для ограниченного набора латинских символов.
Оператор == не подходит для логики, зависящей от языковых правил или категорий символов. В таких случаях следует применять методы класса Character, которые учитывают свойства Unicode и обеспечивают предсказуемое поведение при работе с текстом.
Сравнение char операторами < и > с учетом порядка Unicode
Операторы < и > при работе с типом char сравнивают числовые значения кодовых единиц UTF-16. Порядок определяется позицией символа в таблице Unicode, поэтому результат не связан с алфавитной сортировкой или языковыми правилами. Например, все цифры располагаются раньше латинских букв, а латиница – раньше кириллицы.
Такое сравнение удобно для проверки диапазонов. Условие вида c >= ‘0’ && c <= ‘9’ корректно определяет арабские цифры, поскольку их коды идут подряд. Аналогично можно фильтровать латинские буквы в одном регистре, опираясь на непрерывные интервалы символов.
Следует учитывать, что сравнение символов разных алфавитов через < и > не отражает привычного порядка. Например, ‘Я’ всегда будет больше ‘z’ из-за расположения блоков Unicode, даже если визуально ожидается иной результат. Поэтому такие операторы не подходят для текстовой сортировки, ориентированной на язык.
При сравнении символов разного регистра результат также определяется кодами. Заглавные латинские буквы располагаются раньше строчных, что может искажать проверки, если регистр не был предварительно нормализован. Рекомендуется заранее приводить символы к одному регистру с помощью методов Character.
Операторы < и > работают только с примитивами. При использовании Character происходит автоупаковка и распаковка, что не влияет на результат сравнения, но требует контроля значений null для предотвращения ошибок выполнения.
Приведение char к int для анализа кодов символов
Приведение типа char к int в Java выполняется неявно или через явное преобразование и позволяет получить числовое значение кодовой единицы UTF-16. Это дает возможность напрямую анализировать код символа, выполнять арифметические операции и строить условия без участия строковых методов.
Такой подход полезен при отладке и разборе входных данных, когда требуется понять, какой именно код обрабатывается программой. Преобразование (int) c показывает фактическое значение символа, что помогает выявлять неожиданные пробелы, управляющие знаки или нестандартные символы из расширенных диапазонов Unicode.
Работа с кодами через int упрощает проверки диапазонов, особенно если необходимо комбинировать несколько условий. Например, можно явно задать границы допустимых символов или исключить отдельные коды, не создавая сложных цепочек сравнений с символьными литералами.
Следует учитывать, что тип char хранит только одну кодовую единицу, а не полную кодовую точку Unicode. Символы, представленные суррогатными парами, при приведении к int анализируются лишь частично. Для таких случаев необходимо использовать тип int и методы работы с кодовыми точками.
Приведение char к int не изменяет значение и не требует дополнительных проверок, однако обратное преобразование должно сопровождаться контролем диапазона, чтобы избежать получения некорректного символа при приведении числовых значений.
Применение метода Character.compare для двух char
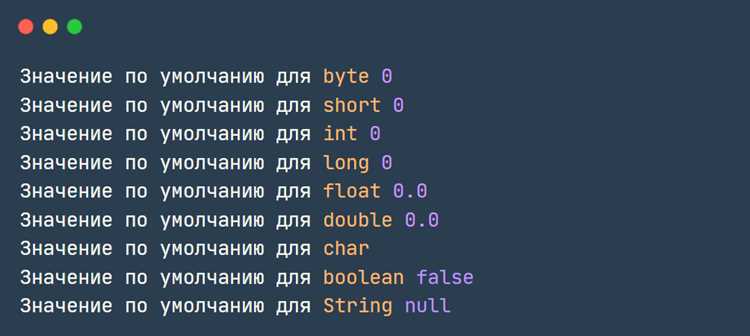
Метод Character.compare(char x, char y) предназначен для сравнения двух примитивных значений char и возвращает целое число, отражающее их порядок по кодам UTF-16. Результат равен нулю при совпадении кодов, отрицателен, если первый аргумент меньше второго, и положителен в обратной ситуации.
Использование Character.compare оправдано в контекстах, где требуется числовой результат сравнения, а не логическое значение. Это особенно актуально при написании компараторов, сортировке массивов и коллекций, а также при реализации собственных алгоритмов упорядочивания.
- Метод работает напрямую с примитивами и не создает объектов Character.
- Поведение полностью совпадает с вычитанием кодов, но не требует явного приведения типов.
- Результат стабилен и предсказуем при любых допустимых значениях char.
При сравнении символов разных регистров или алфавитов метод не выполняет нормализацию. Если порядок должен быть регистронезависимым, символы следует заранее привести к одному регистру через методы класса Character.
- Преобразовать оба символа к нужному регистру.
- Передать значения в Character.compare.
- Использовать возвращаемое значение в логике сортировки или проверки.
Метод не обрабатывает суррогатные пары как единый символ. При сравнении расширенных кодовых точек необходимо использовать значения типа int, полученные через методы работы с Unicode.
Сравнение через compareTo у объекта Character и автоупаковка
Класс Character реализует интерфейс Comparable, предоставляя метод compareTo для сравнения объектов-оберток. Метод сопоставляет внутренние значения char по кодам UTF-16 и возвращает целое число, отражающее их относительный порядок. Это делает его пригодным для сортировки коллекций, работающих только с объектами.
При передаче примитивного char в контекст, где ожидается Character, происходит автоупаковка. Сравнение через compareTo в таком случае требует создания объекта, что следует учитывать в участках кода с большим числом операций. Для одиночных сравнений это не критично, но в циклах предпочтительнее использовать примитивы.
Метод compareTo нельзя вызывать у ссылки со значением null. При обработке данных из внешних источников необходимо заранее проверять объекты на наличие значения, иначе возникает исключение во время выполнения. В ситуациях с потенциально отсутствующими символами безопаснее применять статический метод Character.compare.
Сравнение через compareTo не учитывает регистр и языковые особенности. Если требуется регистронезависимая логика, объекты должны быть предварительно преобразованы через методы приведения регистра. Сам метод сравнивает только числовые коды и не выполняет дополнительной обработки.
Использование compareTo оправдано при работе с обобщенными структурами данных и стандартными алгоритмами сортировки. В остальных случаях прямое сравнение примитивов остается более предсказуемым и простым вариантом.
Инкремент и декремент char с помощью операторов ++ и —
Тип char в Java поддерживает операторы ++ и —, так как хранит числовое значение кодовой единицы UTF-16. Инкремент увеличивает код символа на единицу, а декремент уменьшает его, что приводит к переходу к соседнему символу в таблице Unicode без учета семантики или алфавита.
Такое поведение полезно при последовательной обработке диапазонов символов, например при генерации последовательностей букв или переборе допустимых значений. При этом важно понимать, что операции не ограничиваются рамками конкретного алфавита и могут привести к выходу за ожидаемый диапазон.
| Исходное значение char | Операция | Результирующий символ | Комментарий |
|---|---|---|---|
| ‘A’ | ++ | ‘B’ | Переход к следующей латинской букве |
| ‘Z’ | ++ | ‘[‘ | Выход за пределы алфавита |
| ‘0’ | ++ | ‘1’ | Последовательность цифр |
| ‘а’ | — | ‘Я’ | Переход внутри блока кириллицы |
Инкремент и декремент применимы только к примитиву char. Для Character такие операции невозможны без явной распаковки, что делает код менее наглядным. В ситуациях, где требуется управление кодами символов, предпочтительно работать с примитивами или явно приводить значения к int.
Перед использованием операторов ++ и — рекомендуется задавать четкие границы диапазона и проверять результат. Это предотвращает появление непреднамеренных символов, особенно при работе с пользовательским вводом и многоязычными данными.
Сравнение char без учета регистра через Character.toLowerCase и toUpperCase

Сравнение символов без учета регистра в Java требует явного приведения значений, так как тип char сравнивается по кодам UTF-16. Символы разных регистров имеют разные числовые значения, поэтому прямое сравнение через операторы всегда даст ложный результат без предварительной нормализации.
Методы Character.toLowerCase и Character.toUpperCase преобразуют символ с учетом правил Unicode, а не только латинского алфавита. Это позволяет корректно сравнивать буквы кириллицы и других письменностей, где регистр представлен отдельными кодовыми точками.
- Преобразование выполняется до сравнения, а не во время него.
- Методы работают с примитивом char и не требуют создания объекта.
- Результат зависит от таблиц Unicode, встроенных в текущую версию JVM.
На практике рекомендуется выбирать один регистр и приводить к нему оба символа. Чаще используется toLowerCase, так как он стабилен при проверках пользовательского ввода и разборе текстовых данных.
- Получить исходные значения char.
- Применить Character.toLowerCase или Character.toUpperCase к каждому символу.
- Сравнить результаты через оператор == или метод Character.compare.
Следует учитывать, что некоторые символы Unicode при преобразовании регистра могут изменяться несимметрично или не иметь пары. Для одиночных символов это редкие случаи, но при строгих требованиях к текстовой обработке их необходимо учитывать.
Ограничения метода equals при сравнении char и Character
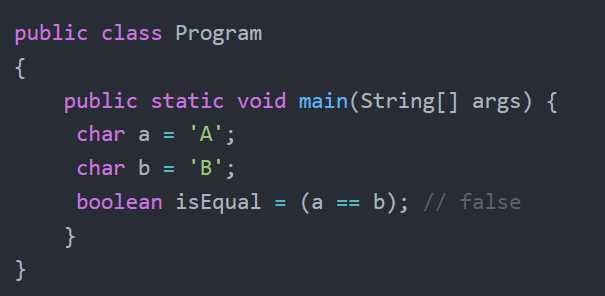
Метод equals применяется только к объектам и недоступен для примитивного типа char. Его использование возможно исключительно с экземплярами класса Character, что уже накладывает ограничение и требует понимания различий между значениями и ссылками.
Вызов equals сравнивает внутреннее значение символа, но не выполняет автоупаковку аргумента. Попытка сравнить Character с char напрямую невозможна без предварительного приведения примитива к объекту, что усложняет код и увеличивает риск ошибок.
Метод чувствителен к значению null. Вызов equals у ссылки без значения приводит к исключению, поэтому при работе с данными из коллекций или внешних источников требуется предварительная проверка. Это особенно важно в условиях, где отсутствие символа допустимо логикой программы.
equals не учитывает регистр и не выполняет нормализацию. Символы ‘A’ и ‘a’ считаются разными, даже если в прикладной задаче требуется иная логика. Все преобразования должны выполняться до вызова метода, иначе результат будет некорректным.
Использование equals оправдано при сравнении объектов Character в коллекциях, но для большинства операций с одиночными символами предпочтительнее сравнение примитивов через операторы или статические методы класса Character, которые не зависят от состояния объекта.
Вопрос-ответ:
Почему оператор == подходит для сравнения char, но не всегда удобен для Character?
Оператор == сравнивает примитивные значения напрямую и корректно работает с типом char, так как проверяет числовые коды символов. При использовании Character происходит распаковка объекта, что может привести к исключению при значении null. Кроме того, == для объектов проверяет ссылки, а не содержимое, поэтому для Character он неприменим без явного приведения к примитиву.
Почему сравнение char операторами < и > иногда дает неожиданный порядок символов?
Операторы < и > сравнивают коды UTF-16, а не алфавитный порядок. Блоки Unicode расположены технически, а не лингвистически, поэтому латиница, кириллица и специальные символы следуют друг за другом в непривычной последовательности. Такое сравнение подходит для диапазонов кодов, но не для сортировки текста по правилам языка.
Зачем приводить char к int, если его можно сравнивать напрямую?
Приведение к int позволяет явно увидеть и анализировать числовой код символа. Это удобно при отладке, обработке нестандартного ввода и построении сложных условий, где требуется работать с конкретными кодовыми значениями, а не символьными литералами.
В чем практический смысл Character.compare, если есть операторы сравнения?
Character.compare возвращает числовой результат, который можно напрямую использовать в сортировке и компараторах. Это избавляет от ручного преобразования логических условий в числовую форму и упрощает работу с обобщенными структурами данных, где операторы недоступны.
Почему equals не считается универсальным решением для сравнения символов?
equals работает только с объектами и не применим к char. Он не выполняет преобразование регистра и чувствителен к null. При сравнении одиночных символов это создает лишние проверки и повышает риск ошибок, поэтому для примитивов чаще используют операторы или статические методы класса Character.