В Python длина массива напрямую влияет на обработку данных, контроль циклов и работу с алгоритмами. Для стандартных списков и кортежей используется функция len(), которая возвращает количество элементов за константное время. Например, len([1, 2, 3, 4]) вернёт 4, а len((10, 20)) – 2.
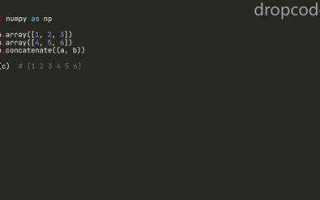
При работе с библиотекой NumPy важно учитывать, что массивы могут быть многомерными. Функция len() возвращает размер первой оси, но для полного подсчета элементов применяют атрибут array.size или array.shape для каждой размерности. Например, для массива np.array([[1,2],[3,4],[5,6]]) len() вернёт 3, а size – 6.
Длина словарей и множеств также измеряется с помощью len(), но учитывает только уникальные ключи или элементы. Это важно при подсчёте уникальных значений или проверке корректности структуры данных. Например, len({1,2,2,3}) вернёт 3, а len({‘a’:10,’b’:20}) – 2.
При работе с вложенными структурами и строками длина отдельных элементов может быть разной. Для строк len() возвращает количество символов, включая пробелы и специальные символы. Для списков внутри списков нужно выбирать подходящий способ подсчёта: либо только верхний уровень с len(), либо суммирование длин всех вложенных массивов через циклы или генераторы.
Использование функции len() для списков
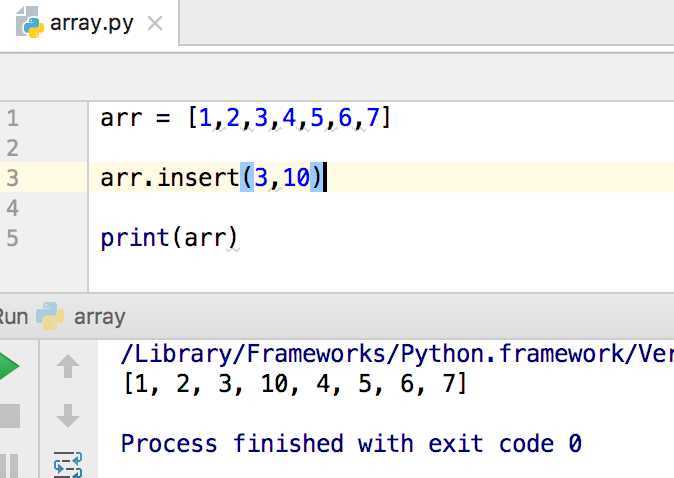
Функция len() возвращает количество элементов в списке за константное время. Для списка my_list = [1, 2, 3, 4, 5] вызов len(my_list) вернёт 5. Она учитывает все элементы, включая None и дубликаты.
Для динамически изменяемых списков len() всегда отражает актуальное количество элементов. Например, после выполнения my_list.append(6) функция len(my_list) вернёт 6, а после my_list.pop() – 5.
Функция совместима с вложенными списками, но возвращает длину только верхнего уровня. Для подсчёта элементов внутри вложенных структур используют комбинацию len() с циклами или генераторами. Например, sum(len(sub) for sub in nested_list) подсчитает количество всех элементов второго уровня.
Использование len() оптимально при проверке границ циклов и условных операторов. Например, для обхода списка: for i in range(len(my_list)) гарантирует корректную итерацию по индексам без ошибок IndexError.
Определение размера кортежа с помощью len()

Для кортежей функция len() возвращает количество элементов в структуре. Кортежи неизменяемы, поэтому размер остаётся постоянным после создания. Например, для my_tuple = (10, 20, 30, 40) вызов len(my_tuple) вернёт 4.
Функция учитывает все элементы, включая None и дубликаты, но не различает тип данных внутри кортежа. Это позволяет использовать len() для контроля границ циклов и проверки непустых кортежей:
if len(my_tuple) > 0: можно безопасно обращаться к элементам по индексу без риска IndexError.
При работе с вложенными кортежами len() возвращает длину только верхнего уровня. Для подсчёта элементов внутри вложенных структур используют генераторы или рекурсивные функции, например:
total = sum(len(sub) for sub in nested_tuple) – подсчёт элементов второго уровня.
Подсчет элементов множества и словаря
Для множеств и словарей функция len() возвращает количество уникальных элементов или ключей. Значения словаря не влияют на результат подсчёта, а дубликаты в множестве автоматически игнорируются.
Примеры использования:
- Для множества my_set = {1, 2, 2, 3, 4} len(my_set) вернёт 4, игнорируя повторяющийся элемент 2.
- Для словаря my_dict = {‘a’:10, ‘b’:20, ‘c’:30} len(my_dict) вернёт 3, учитывая только ключи.
Рекомендации при работе с большими структурами:
- Использовать len() для проверки пустоты: if len(my_set) == 0.
- Сравнивать размеры множеств для поиска пересечений: len(set1) < len(set2).
- Подсчет ключей словаря для условной обработки: if len(my_dict) > 5 выполнять оптимизацию.
Для вложенных множеств или словарей len() учитывает только верхний уровень. Чтобы получить суммарное количество всех элементов, используют комбинацию генераторов или рекурсивные обходы структур.
Длина строки как последовательности символов
В Python строки рассматриваются как последовательности символов, и функция len() возвращает точное количество символов, включая пробелы, цифры, знаки препинания и специальные символы. Например, len(«Python 3.11») вернёт 10.
Для строк с символами Юникода len() учитывает каждый кодовый символ, а не визуальное отображение. Например, эмодзи len(«😊») вернёт 1, хотя на экране может занимать больше места.
Длина строки полезна при ограничении ввода, проверке форматов и обработке текстовых файлов. Например:
- Проверка длины имени пользователя: if len(username) <= 20
- Обрезка длинного текста: text[:len(text)]
- Подсчет количества символов перед сохранением в базу данных
Для многомерных текстовых структур, например списков строк, длину каждой строки вычисляют отдельно через len() или с использованием генераторов: [len(s) for s in string_list].
Измерение длины массива NumPy

Массивы NumPy могут быть многомерными, поэтому стандартная функция len() возвращает размер только первой оси. Например, для массива arr = np.array([[1,2,3],[4,5,6]]) len(arr) вернёт 2, хотя общее количество элементов – 6.
Для полного подсчёта всех элементов используют атрибут size:
- arr.size вернёт 6 для приведённого массива.
Для получения размера по конкретной оси применяется атрибут shape:
- arr.shape[0] – количество строк (2).
- arr.shape[1] – количество столбцов (3).
Рекомендации при работе с большими массивами:
- Использовать len(arr) для циклов по первой оси.
- Применять arr.size для подсчёта общего количества элементов в вычислениях.
- Использовать arr.shape для работы с индексами и срезами многомерных массивов.
Подсчет элементов вложенных списков
Вложенные списки представляют собой списки внутри списков, и функция len() возвращает количество элементов только верхнего уровня. Например, для nested = [[1,2,3],[4,5],[6]] len(nested) вернёт 3, игнорируя количество элементов внутри подсписков.
Чтобы подсчитать все элементы во вложенных списках, используют генераторы или циклы:
- sum(len(sub) for sub in nested) вернёт 6, суммируя элементы всех подсписков.
- Рекурсивная функция позволяет учитывать вложенность произвольного уровня:
Применение подсчёта:
- Контроль общего количества элементов перед обработкой данных.
- Проверка соответствия структуры списков заданным требованиям.
- Оптимизация циклов, чтобы избежать IndexError при обходе вложенных элементов.
Для смешанных структур (списки с кортежами или множествами внутри) генератор или рекурсивная функция позволяет корректно подсчитывать только последовательности, игнорируя другие типы данных.
Получение длины массива с помощью цикла for

Цикл for позволяет подсчитать количество элементов массива вручную, обходя каждый элемент и увеличивая счётчик. Например, для списка arr = [1,2,3,4] можно использовать:
count = 0
for item in arr:
count += 1
После выполнения цикла переменная count будет содержать длину массива (4 в данном примере). Этот метод полезен для проверки корректности функции len() или работы с объектами, которые не поддерживают встроенное определение длины.
Для вложенных массивов цикл for можно комбинировать с генераторами или рекурсией, чтобы подсчитывать элементы на нескольких уровнях. Например:
- Для nested = [[1,2],[3,4,5]] можно суммировать длины подсписков: total = 0
for sub in nested:
for item in sub:
total += 1, что даст 5.
Рекомендации по использованию:
- Применять при работе с нестандартными объектами, которые не поддерживают len().
- Использовать для отладки, чтобы убедиться в корректности структуры данных.
- Сохранять счётчик в отдельной переменной для дальнейшей обработки или анализа.
Сравнение размеров нескольких массивов
Сравнение длины массивов позволяет определить, какой из них содержит больше элементов, и корректно организовать обработку данных. Для списков и кортежей используют функцию len():
len(arr1) > len(arr2) возвращает True, если первый массив длиннее второго.
Для множеств и словарей len() учитывает только уникальные элементы или ключи. Например:
- len(set1) < len(set2) помогает определить, где больше уникальных значений.
- len(dict1) == len(dict2) проверяет соответствие количества ключей в двух словарях.
При сравнении многомерных массивов NumPy учитывают размер нужной оси через shape или общее количество элементов через size:
- arr1.shape[0] > arr2.shape[0] – больше строк в первом массиве.
- arr1.size < arr2.size – меньше элементов в целом.
Рекомендации:
- Использовать len() для быстрого сравнения одномерных структур.
- Для вложенных или многомерных массивов применять sum(len(sub) for sub in arr) или size для точного подсчёта.
- Сравнивать массивы перед объединением или обработкой для предотвращения ошибок индексации.
Вопрос-ответ:
Можно ли использовать len() для подсчёта элементов вложенных списков?
Функция len() возвращает количество элементов только верхнего уровня. Если у вас есть список списков, например nested = [[1,2],[3,4,5]], то len(nested) вернёт 2. Чтобы подсчитать все элементы внутри подсписков, используют генераторы или циклы, например: sum(len(sub) for sub in nested), что вернёт 5.
Как узнать количество элементов в массиве NumPy?
Для многомерных массивов NumPy функция len() возвращает размер первой оси. Например, для arr = np.array([[1,2,3],[4,5,6]]) len(arr) даст 2, хотя элементов всего 6. Чтобы получить общее количество элементов, используют arr.size. Для получения размеров каждой оси применяют arr.shape, например, arr.shape[1] вернёт 3 — количество столбцов.
Что учитывать при подсчёте длины строк с эмодзи или символами Юникода?
Функция len() считает каждый кодовый символ, включая эмодзи, пробелы и специальные символы. Например, len(«😊») вернёт 1, несмотря на то, что визуально символ может занимать несколько позиций. При работе с текстами важно учитывать это, чтобы не выйти за границы индексов или правильно ограничивать ввод.
Как сравнить размеры нескольких массивов разных типов данных?
Для списков и кортежей используют len(), для словарей и множеств len() возвращает количество ключей или уникальных элементов. Для массивов NumPy применяют size или shape в зависимости от задачи. Например, len(list1) > len(list2) проверяет, какой список длиннее, а arr1.size < arr2.size покажет, какой массив NumPy содержит меньше элементов. Такой подход позволяет корректно организовать циклы и обработку данных.