Файл .txt сам по себе не является программой, но часто используется как источник логики, данных или заготовок кода. Преобразование такого файла в .py требуется, когда текст содержит команды, псевдокод, инструкции для автоматизации или набор данных, которые должны обрабатываться интерпретатором Python. Ключевая задача – понять, какую роль играет текст: набор строк, сценарий действий или почти готовый код.
Перед началом важно определить тип содержимого. Если txt-файл содержит обычный текст, его преобразование сводится к созданию Python-скрипта с чтением строк через open(). Если внутри уже есть конструкции, похожие на Python (циклы, условия, функции), потребуется ручная правка: расстановка отступов, замена неподдерживаемых символов и проверка синтаксиса. Простое переименование расширения в этом случае приведёт к ошибкам при запуске.
Отдельного внимания требует кодировка. Большинство txt-файлов создаются в UTF-8 или Windows-1251, и при неверном указании кодировки Python выдаст исключение. Рекомендуется сразу указывать параметр encoding при чтении или сохранить файл в UTF-8 перед преобразованием. Также стоит проверить наличие табуляций, скрытых символов и переносов строк, которые могут нарушить структуру будущего скрипта.
Преобразование txt в py – это не автоматическая операция, а последовательность технических шагов: анализ содержимого, подготовка структуры файла, перенос текста в допустимый синтаксис Python и проверка запуска. Такой подход позволяет получить управляемый и предсказуемый результат, а не набор строк, которые интерпретатор не сможет выполнить.
Определение задачи: что именно должно стать Python-скриптом
Преобразование txt-файла начинается с точного понимания его назначения. Один и тот же текст может использоваться как набор исходных данных, сценарий действий или заготовка кода. От этого зависит структура будущего файла .py, используемые модули и способ обработки содержимого. Без формализации задачи невозможно определить, должен ли текст выполняться построчно, интерпретироваться как логика или храниться в виде данных.
Другая ситуация возникает, когда txt-файл уже включает команды, условия или последовательность шагов, описывающих алгоритм. Здесь требуется определить, какие элементы можно перевести в конструкции Python, а какие нужно переписать. Особое внимание уделяется логическим блокам, повторяющимся операциям и зависимостям между строками, так как они формируют основу будущего скрипта.
Для фиксации решения удобно заранее классифицировать содержимое файла и ожидаемый результат выполнения. Это позволяет избежать хаотичного редактирования и сразу выбрать корректный подход к преобразованию.
| Тип содержимого txt | Назначение Python-скрипта | Подход к преобразованию |
|---|---|---|
| Набор данных | Анализ, фильтрация, расчёты | Чтение файла и обработка значений |
| Пошаговые инструкции | Автоматизация действий | Перевод шагов в функции и условия |
| Псевдокод | Реализация алгоритма | Переписывание в синтаксис Python |
| Готовые фрагменты кода | Запуск программы | Правка отступов и проверка синтаксиса |
Чёткое определение задачи на этом этапе позволяет заранее решить, какие части txt-файла станут исполняемым кодом, какие будут загружаться как данные, а какие следует исключить из итогового .py-файла.
Проверка структуры txt-файла перед преобразованием

Перед переносом содержимого в файл .py необходимо проанализировать внутреннюю структуру txt-документа. В первую очередь проверяется, разделён ли текст на логические блоки: строки с данными, команды, комментарии или описательные фрагменты. Отсутствие явных границ между блоками усложняет последующее преобразование и требует предварительного упорядочивания.
Отдельное внимание уделяется переносам строк. Python воспринимает строку как минимальную единицу исполнения, поэтому лишние пустые строки, разрывы внутри выражений или объединённые в одну строку логические операции могут нарушить интерпретацию. Рекомендуется привести файл к единому формату: одна логическая операция – одна строка.
Необходимо выявить символы, которые не имеют смысла для Python-интерпретатора: табуляции, используемые как выравнивание, нестандартные кавычки, управляющие символы, скопированные из других редакторов. Такие элементы следует заменить или удалить до создания py-файла, иначе они станут причиной ошибок при запуске.
Если txt-файл содержит повторяющиеся блоки, их стоит сгруппировать и определить, можно ли представить их в виде циклов или функций. Наличие однотипных строк часто указывает на необходимость структурирования логики, а не прямого копирования текста в скрипт.
Завершающий этап проверки – оценка последовательности. Строки должны располагаться в том порядке, в котором предполагается выполнение операций. Любые ссылки на переменные, значения или действия, объявленные ниже по тексту, требуют перестановки или переработки, так как Python обрабатывает код строго сверху вниз.
Подготовка кодировки и переносов строк для Python
Перед созданием файла .py необходимо точно определить кодировку исходного txt-документа. На практике чаще всего встречаются UTF-8 и Windows-1251. Если кодировка не совпадает с ожидаемой, Python при чтении файла выдаст исключение UnicodeDecodeError. Надёжный подход – сохранить txt-файл в UTF-8 без BOM или явно указать параметр encoding при работе с файлом.
При переносе текста в Python-скрипт важно учитывать тип переносов строк. Windows использует CRLF, Unix-системы – LF. Смешанный формат приводит к некорректному разбору строк и ошибкам при обработке данных. Рекомендуется привести файл к единому виду, используя редактор с возможностью конвертации переносов или автоматическую нормализацию при чтении.
Особое внимание требуется при работе с многострочным текстом. Если содержимое txt должно храниться внутри кода, его следует заключать в тройные кавычки, сохраняя исходные переводы строк. При этом важно проверить отсутствие случайных пробелов в начале строк, так как Python воспринимает отступы как часть синтаксиса.
Необходимо также удалить скрытые символы: неразрывные пробелы, символы конца файла и управляющие последовательности, появляющиеся при копировании из других источников. Их наличие сложно заметить визуально, но они способны нарушить выполнение скрипта или обработку строковых данных.
Корректная настройка кодировки и переносов строк на этом этапе обеспечивает предсказуемое поведение Python при запуске и упрощает дальнейшую отладку, исключая ошибки, не связанные с логикой программы.
Создание файла.py и базовой оболочки скрипта
После подготовки txt-файла создаётся новый файл с расширением .py, расположенный в той же директории или в рабочем каталоге проекта. Имя файла должно соответствовать правилам Python: латиница, без пробелов и специальных символов. Это упрощает импорт и запуск скрипта из командной строки или среды разработки.
В начале файла рекомендуется задать минимальную структуру исполнения. Если скрипт предполагает запуск напрямую, добавляется проверка if __name__ == «__main__»:. Такой подход позволяет в дальнейшем использовать файл как модуль без автоматического выполнения кода при импорте.
Если txt-файл будет считываться как внешний источник, в оболочке сразу указывается путь к нему и базовая функция чтения. Это может быть отдельная функция, возвращающая данные, или блок кода, подготавливающий входные значения. Размещение этой логики в начале файла упрощает контроль за порядком выполнения.
При наличии в будущем нескольких операций имеет смысл заранее определить функции-заготовки. Даже пустые функции с оператором pass позволяют зафиксировать архитектуру скрипта до переноса логики из txt. Это снижает риск хаотичного размещения кода и упрощает последующую доработку.
Базовая оболочка должна запускаться без ошибок до добавления содержимого txt. Проверка пустого или минимального .py-файла гарантирует, что все дальнейшие проблемы будут связаны с переносом текста, а не с неправильным созданием самого скрипта.
Перенос текста в виде строковых данных Python
Если содержимое txt-файла не должно выполняться как код, его переносят в Python в виде строковых данных. На практике это реализуется либо через чтение внешнего файла, либо через прямое встраивание текста в переменные. Выбор зависит от объёма данных и необходимости редактирования исходного текста без изменения скрипта.
При чтении txt-файла строки загружаются в память с сохранением порядка. Каждая строка может обрабатываться отдельно или объединяться в одну строковую переменную. Важно учитывать, что символ переноса строки сохраняется и должен быть явно удалён или обработан, если он не участвует в логике программы.
Для встраивания текста напрямую используется строковый литерал. Короткие фрагменты удобнее хранить в обычных кавычках, а многострочный текст – в тройных кавычках. Такой подход позволяет сохранить форматирование, включая переводы строк и пробелы, без дополнительной обработки.
Специальные символы требуют экранирования. Кавычки, обратные слэши и управляющие последовательности должны быть приведены к синтаксису Python, иначе интерпретатор завершит выполнение с ошибкой. Альтернативой является использование «сырых» строк, если текст не содержит завершающих служебных конструкций.
После переноса текста в виде строковых данных рекомендуется вывести его в консоль или записать во временный файл. Это позволяет убедиться, что содержимое полностью соответствует оригинальному txt и не было искажено в процессе преобразования.
Преобразование команд и данных txt в исполняемый код
Когда txt-файл содержит инструкции или алгоритм, его нельзя переносить в Python построчно без адаптации. Каждая команда должна быть приведена к допустимой конструкции языка: выражению, условию, циклу или вызову функции. На этом этапе определяется, какие строки становятся кодом, а какие – входными данными.
Рекомендуется выполнять преобразование последовательно, разбивая текст на логические группы. Это снижает вероятность ошибок и упрощает проверку результата.
- Команды вида «если», «иначе», «пока», «повторить» переводятся в
if,else,whileс обязательными отступами. - Повторяющиеся действия оформляются в виде функций с явными параметрами.
- Числовые и строковые значения приводятся к типам
int,floatилиstrдо использования в вычислениях. - Строки, используемые только как данные, исключаются из тела кода и передаются через переменные или файлы.
Особое внимание уделяется порядку выполнения. Python обрабатывает код сверху вниз, поэтому объявления функций и переменных должны располагаться до их использования. Любые зависимости между строками txt необходимо выявить заранее и отразить в структуре скрипта.
Для сложных сценариев полезно зафиксировать алгоритм в виде последовательности шагов, а затем реализовать их в коде.
- Выделить входные данные и источник их получения.
- Описать обработку каждого шага в виде функции или блока кода.
- Связать шаги в единую цепочку выполнения.
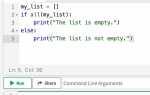
После преобразования каждого блока код следует запускать отдельно. Это позволяет сразу обнаружить логические и синтаксические ошибки, не дожидаясь полной интеграции всего содержимого txt-файла.
Обработка ошибок синтаксиса после переноса
Наиболее частые проблемы связаны с форматированием и недопустимыми конструкциями. Их удобно выявлять, анализируя сообщения об ошибках и соответствующие строки кода.
- Неправильные отступы, особенно после условий и циклов.
- Отсутствие двоеточий в
if,for,while,def. - Использование зарезервированных слов как имён переменных.
- Незакрытые кавычки и скобки после копирования текста.
Для системной проверки полезно разбить скрипт на части и временно закомментировать блоки, не участвующие в текущей проверке. Это позволяет локализовать ошибку и ускоряет исправление проблемных участков.
Рекомендуемый порядок исправлений после переноса:
- Исправить ошибки, препятствующие запуску файла.
- Проверить объявления функций и порядок их использования.
- Убедиться, что все переменные и параметры инициализированы.
- Удалить или переписать строки, не имеющие эквивалента в Python.
После устранения синтаксических ошибок скрипт должен запускаться без исключений. Только на этом этапе имеет смысл переходить к проверке логики и корректности результатов выполнения.
Запуск и проверка работоспособности полученного py-файла
После устранения синтаксических ошибок файл .py запускается в той среде, для которой он предназначен. При запуске из командной строки важно убедиться, что используется нужная версия Python и рабочая директория совпадает с расположением файла и связанных ресурсов. Ошибочный путь к данным или модулям приведёт к сбоям, не связанным с самим преобразованием.
Первый запуск выполняется с минимальным набором входных данных. Это позволяет проверить базовый сценарий выполнения без влияния граничных условий. Если скрипт читает txt-файл, следует заранее проверить существование файла и корректность пути, иначе программа завершится с исключением на этапе инициализации.
Особое внимание уделяется результатам выполнения. Скрипт должен выдавать корректные значения, изменять данные или создавать файлы строго в тех местах, которые были запланированы. Любые побочные эффекты, появившиеся после переноса текста из txt, указывают на ошибку в логике преобразования.
Финальным шагом считается повторный запуск после очистки отладочных элементов. Если py-файл стабильно выполняется в одинаковых условиях и даёт предсказуемый результат, преобразование txt в Python-скрипт можно считать завершённым.
Вопрос-ответ:
Как понять, должен ли txt-файл выполняться как код или использоваться только как источник данных?
Нужно проанализировать содержимое файла. Если строки описывают действия, условия, повторения или расчёты, их придётся переводить в конструкции Python. Если файл состоит из значений, списков, параметров или текстовых блоков без логики выполнения, его следует подключать к скрипту через чтение файла и обработку данных.
Почему после копирования текста из txt Python указывает на ошибку в строке, где визуально всё выглядит нормально?
Часто причина связана со скрытыми символами: неразрывные пробелы, табуляции, нестандартные кавычки или символы конца строки. Они не видны в обычном режиме редактора, но Python воспринимает их как недопустимые элементы. Решение — очистить строку или перепечатать проблемный участок вручную.
Можно ли автоматически преобразовать инструкции из txt в Python-код?
Автоматическое преобразование возможно только для строго формализованных форматов. Обычный текст с описаниями действий требует ручного анализа и переписывания. Скрипт не способен сам определить, какие строки являются условиями, а какие комментариями, без заранее заданных правил.
Что делать, если txt-файл содержит команды в произвольном порядке?
Порядок строк необходимо привести к логике выполнения Python. Объявления переменных и функций должны находиться выше их использования. Если строки ссылаются на данные, описанные ниже по тексту, их придётся переставить или переписать, иначе выполнение завершится ошибкой.
Нужно ли сохранять оригинальный txt-файл после преобразования?
Сохранение исходного файла оправдано, если он используется как входной ресурс или служит контрольной версией. Это позволяет сравнивать результаты обработки, быстро вносить правки в данные и не изменять сам Python-скрипт при корректировке содержимого.