Web crawling описывает процесс автоматического обхода сайтов, при котором программа фиксирует структуру страниц, извлекает ссылки и формирует поток данных для последующей обработки. Краулер получает стартовые URL, строит очередь переходов и контролирует глубину обхода, что позволяет управлять нагрузкой и избегать циклических маршрутов.
При работе с реальными сайтами важно учитывать файл robots.txt, скорость запросов и ограничения серверов. Краулер отслеживает коды ответов, корректно обрабатывает перенаправления и фиксирует ошибки сети. Такой подход снижает риск блокировок и помогает получить стабильный набор данных.
Извлечение содержимого выполняется через анализ HTML-структуры: выделяются текстовые блоки, атрибуты, ссылки, элементы навигации и данные, загружаемые динамически. Для проектов с большим числом страниц полезно применять отдельное хранилище для временных данных, логи обработки, а также систему фильтров, которая отсеивает дубликаты и нерелевантные разделы.
Web crawling: что это и как работает
Перед загрузкой страниц сервис сверяет доступ с файлом robots.txt и учитывает допустимую частоту запросов. Это помогает уменьшить нагрузку на сервер и избежать ограничений со стороны сайта. Краулер фиксирует коды ответов, обрабатывает перенаправления и вносит ошибочные URL в отдельный список, что упрощает последующий анализ.
Контент извлекается через разбор HTML: выделяются текстовые узлы, ссылки, атрибуты элементов и данные, появляющиеся при работе скриптов. Для стабильной работы стоит использовать очереди задач, фильтры для удаления повторяющихся страниц и хранилище, где фиксируются результаты обхода вместе с метаданными – временем загрузки, размером документа и найденными ссылками.
Назначение краулера и задачи, которые он решает
Краулер применяют для автоматического сбора данных с сайтов, когда требуется получить структуру страниц, актуальные ссылки и содержимое без ручной проверки. Программа формирует карту ресурсов, выявляет недоступные разделы, фиксирует изменения и подготавливает материал для последующего анализа или индексации.
Инструмент решает задачу систематического обхода: определяет стартовые URL, распределяет их по очереди, контролирует частоту запросов и учитывает правила доступа, указанные в robots.txt. Такой подход позволяет собирать данные в стабильном объёме и снижать риск блокировки.
Краулер используется и для вспомогательных задач: мониторинг обновлений, проверка корректности ссылок, поиск дубликатов, анализ структуры навигации. При работе с крупными сайтами полезно применять фильтры адресов, временное хранилище для необработанных страниц и систему отчётов, где фиксируются коды ответов, время загрузки и объём полученного контента.
Как формируются стартовые URL и очереди для обхода

Стартовый набор URL определяет диапазон будущего обхода. Обычно в него включают главную страницу сайта, ключевые разделы и адреса, полученные из заранее подготовленного списка. Для проектов с ограниченной зоной сканирования используют фильтры доменов и путей, чтобы исключить переходы на внешние ресурсы.
Очередь формируется по мере обработки страниц: краулер извлекает ссылки из HTML, добавляет новые адреса и проверяет их на соответствие заданным правилам. Чтобы не обрабатывать одну и ту же страницу несколько раз, применяется хранилище посещённых URL, в котором фиксируются уже обработанные записи и адреса, находящиеся в ожидании.
Для управления порядком обхода используют стратегии приоритизации. Например, адреса с меньшей глубиной могут получать более высокий приоритет, а страницы с параметрами – наоборот, помещаться в конец очереди. Такой подход помогает поддерживать стабильность структуры обхода и снижает риск попадания в циклические маршруты.
Алгоритм перехода по ссылкам и обработка найденных страниц

Переходы строятся на основе очереди URL, где каждая запись содержит адрес, глубину обхода и дополнительные параметры. После выбора следующего элемента краулер выполняет загрузку страницы, проверяет код ответа и фиксирует возможные ошибки сети.
- Анализ заголовков ответа: определяется тип контента, размер и доступность для дальнейшей обработки.
- Извлечение HTML: парсер выделяет текстовые блоки, ссылки, атрибуты и элементы интерфейса.
- Обработка найденных ссылок: адреса нормализуются, сверяются с фильтрами домена и путей, затем передаются в очередь.
- Фильтрация повторов: проверка по локальному кешу и базе посещённых страниц.
- Фиксация метаданных: сохраняются время загрузки, количество обнаруженных ссылок и параметры ответа сервера.
Для стабильной работы стоит применять ограничение глубины переходов, контроль частоты запросов и обработку редиректов с фиксацией конечного URL. Это помогает удерживать структуру обхода в предсказуемых пределах и собирать контент без лишних обращений к серверу.
Правила доступа: роль robots.txt и ограничений на загрузку
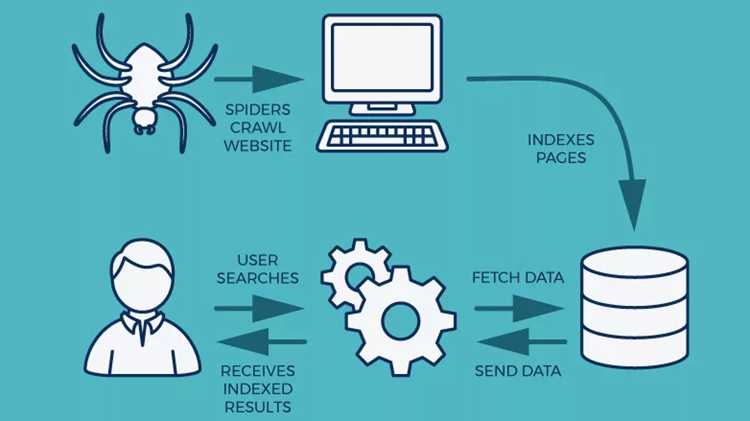
Файл robots.txt указывает краулеру, какие разделы сайта разрешено обходить, а какие – запрещено. Он содержит директивы User-agent, Disallow и Allow, позволяющие детально регулировать доступ для конкретных программ. Краулер перед загрузкой страницы проверяет соответствие URL этим правилам.
Для корректного обхода учитываются ограничения по скорости запросов. Интервалы между обращениями снижают нагрузку на сервер и уменьшают риск временной блокировки. Дополнительно полезно фиксировать размер загружаемых файлов и таймаут соединений, чтобы предотвратить зависания при обработке медленных страниц.
При обходе сайтов с ограничениями стоит вести журнал исключённых URL, фиксировать коды отказа и перенаправлений. Это позволяет анализировать, какие страницы были пропущены, и при необходимости корректировать стратегию обхода, сохраняя соблюдение правил доступа и минимизируя нагрузку на сервер.
Извлечение данных из HTML и подготовка контента к сохранению
Для извлечения информации используется парсинг HTML, который выделяет текстовые блоки, ссылки, атрибуты тегов, метаданные и динамически подгружаемые элементы. Парсер проверяет корректность структуры документа и устраняет ошибки разметки, чтобы контент был пригоден для последующей обработки.
После извлечения данные нормализуются: удаляются лишние пробелы, дублирующиеся элементы и скрипты, не влияющие на содержимое. Ссылки конвертируются в абсолютные URL, а текстовые блоки маркируются тегами для удобного поиска и фильтрации.
Для хранения контента рекомендуется использовать структурированные форматы: базы данных, JSON или CSV. При этом фиксируются метаданные – URL источника, время загрузки, код ответа сервера, размер документа и количество найденных ссылок. Это облегчает последующую индексацию, анализ и интеграцию данных в другие системы.
Проблемы дубликатов, циклов и выбор стратегии обхода

При обходе сайтов часто возникают повторяющиеся URL и циклические переходы, которые могут замедлять работу краулера и увеличивать нагрузку на сервер. Для их контроля используют проверку на уникальность и отслеживание посещённых страниц.
- Фильтрация дубликатов: проверка URL по нормализованной форме, исключение параметров сессий и временных токенов.
- Контроль циклов: фиксирование глубины переходов и анализ структуры ссылок для предотвращения бесконечных обходов.
- Выбор стратегии обхода: использование методов BFS для приоритетного посещения верхних уровней сайта или DFS для глубокого анализа отдельных разделов.
- Учет веса страниц: адреса с высокой значимостью или количеством внутренних ссылок могут обрабатываться раньше, а менее важные – позже.
Реализация этих методов позволяет сокращать избыточные переходы, ускорять сбор данных и сохранять корректную структуру обхода для дальнейшей аналитики и индексирования.
Хранение результатов обхода и способы их дальнейшего использования
Данные, собранные краулером, сохраняются в структурированном виде для последующего анализа и интеграции. В таблицах фиксируются URL, код ответа сервера, время загрузки, размер документа и количество найденных ссылок. Такая организация упрощает фильтрацию, поиск и агрегирование информации.
Пример хранения результатов:
| URL | Код ответа |
|---|