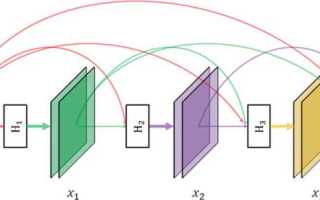
Dense layer – это полносвязный слой нейронной сети, где каждый нейрон получает сигналы от всех нейронов предыдущего слоя. Такой слой используется для объединения признаков и формирования итогового представления данных, что делает его ключевым элементом при построении классификаторов и регрессионных моделей.
Входные данные слоя умножаются на матрицу весов, к результату добавляется смещение, а затем применяется функция активации. Прямое управление весами и смещениями позволяет нейросети выявлять сложные зависимости между признаками и корректно прогнозировать результаты.
При проектировании Dense layer важно определять оптимальное количество нейронов: слишком мало ограничит способность модели к обучению, слишком много может привести к переобучению. Практика показывает, что подбор числа нейронов проводят через эксперименты с кросс-валидацией и анализом метрик точности.
Dense layer активно применяется в задачах классификации изображений, анализа текста и предсказания числовых величин. Примеры использования на Python с библиотекой Keras демонстрируют простоту добавления слоя, настройку функций активации и обучение модели с минимальным кодом.
Dense layer в нейросетях: принцип работы и примеры
Dense layer представляет собой слой, где каждый нейрон соединен со всеми нейронами предыдущего слоя. Входные данные слоя умножаются на матрицу весов W, затем к результату добавляется вектор смещений b, и применяется функция активации f(x). Итоговый выход слоя вычисляется как y = f(Wx + b), что позволяет модели комбинировать признаки и формировать сложные зависимости.
Выбор функции активации критичен: для скрытых слоев часто используют ReLU для ускорения сходимости и устранения проблемы затухающих градиентов, для выходного слоя в задачах классификации – softmax, а для регрессии – linear. Правильная настройка функции активации повышает точность предсказаний и стабилизирует обучение.
Количество нейронов в Dense layer должно соответствовать объему информации и сложности задачи. Например, для классификации изображений размерностью 28×28 px обычно используют 128–512 нейронов в первом полносвязном слое после сверточных слоев. Чрезмерное увеличение числа нейронов повышает риск переобучения, поэтому рекомендуется подключать регуляризацию, например Dropout с вероятностью 0.2–0.5.
Примеры реализации Dense layer на Python с Keras показывают простоту интеграции слоя: достаточно указать количество нейронов и функцию активации, затем добавить слой к модели Sequential. Обучение происходит через метод model.fit с настройкой оптимизатора и функции потерь, что позволяет адаптировать модель под конкретные данные.
Как Dense layer преобразует входные данные в нейросети
Dense layer принимает на вход вектор признаков и преобразует его через матричное умножение на веса слоя. Каждый нейрон вычисляет сумму произведений входов на соответствующие веса и добавляет смещение. Формула вычисления выхода слоя выглядит как y = f(Wx + b), где W – матрица весов, x – входной вектор, b – вектор смещений, а f – функция активации.
В процессе обучения веса W и смещения b корректируются методом обратного распространения ошибки, что позволяет слою выявлять сложные зависимости между признаками. Использование функции активации, например ReLU или sigmoid, обеспечивает нелинейность преобразований, расширяя пространство решений сети.
Для числовых данных рекомендуется нормализовать входы, чтобы ускорить сходимость и снизить риск переполнения нейронов. В задачах с большими признаковыми пространствами практикуется уменьшение размерности через предварительные слои или регуляризацию, чтобы Dense layer мог выделять значимые комбинации признаков без избыточной нагрузки на обучение.
Dense layer формирует компактное представление данных, которое последующие слои используют для классификации, регрессии или генерации. Оптимальное количество нейронов выбирают экспериментально, анализируя метрики точности и потерь на валидационной выборке.
Роль весов и смещений в Dense layer
Весовые коэффициенты в Dense layer определяют силу влияния каждого входного признака на нейрон. Каждый нейрон хранит собственный набор весов W, которые корректируются во время обучения методом градиентного спуска. Правильная настройка весов позволяет модели выделять значимые комбинации признаков и минимизировать ошибку предсказаний.
Смещения b добавляют гибкость нейрону, позволяя сдвигать активацию и обеспечивать корректную работу функции активации даже при нулевых входных значениях. В задачах классификации смещения помогают нейрону активироваться только при наличии определенных признаков, что повышает точность модели.
Инициализация весов играет критическую роль: использование методов He или Xavier уменьшает риск затухающих или взрывающихся градиентов и ускоряет сходимость обучения. Смещения обычно инициализируют нулями или малыми случайными числами, чтобы нейроны могли адаптироваться к особенностям данных на первых итерациях.
Регуляризация весов, например L1 или L2, ограничивает их рост и снижает вероятность переобучения. Такой подход помогает Dense layer выделять действительно значимые признаки без избыточного подстраивания под обучающую выборку.
Функции активации и их влияние на выход слоя
Функция активации определяет, как нейрон реагирует на входные данные после применения весов и смещений. Она вводит нелинейность, позволяя сети моделировать сложные зависимости между признаками. Без активации Dense layer выполнял бы только линейные преобразования, что ограничивало бы способность сети к обучению.
ReLU (Rectified Linear Unit) активирует нейрон только при положительных значениях входа, ускоряя обучение и снижая вероятность затухания градиентов. Для скрытых слоев она является стандартом при работе с изображениями и временными рядами.
Sigmoid сжимает выход в диапазон от 0 до 1, что удобно для задач бинарной классификации. Однако при больших входных значениях градиенты могут почти исчезать, замедляя обучение. Для многоуровневых сетей рекомендуется комбинировать sigmoid с ограниченным числом скрытых слоев.
Softmax преобразует вектор выходов слоя в вероятностное распределение, что критично для многоклассовой классификации. Выход каждого нейрона интерпретируется как вероятность принадлежности к конкретному классу, а сумма всех выходов равна 1.
Linear применяется в задачах регрессии, когда требуется предсказывать непрерывные величины. Она оставляет значения без ограничений, что позволяет модели формировать диапазон выходов, соответствующий данным.
Применение Dense layer для классификации изображений
В задачах классификации изображений Dense layer используется после сверточных слоев для объединения извлеченных признаков и формирования окончательного решения. Сверточные слои выделяют локальные паттерны, а полносвязный слой интерпретирует эти признаки и предсказывает класс изображения.
Для изображений размером 28×28 пикселей часто применяют один или два Dense слоя с 128–512 нейронами, используя ReLU в скрытых слоях и softmax на выходе. Такая структура обеспечивает баланс между способностью к обучению и риском переобучения.
Ниже приведена схема применения Dense layer в классификации изображений:
| Слой | Тип | Выход | Функция активации |
|---|---|---|---|
| Сверточный | Conv2D | 28×28×32 | ReLU |
| Субдискретизация | MaxPooling2D | 14×14×32 | — |
| Flatten | Flatten | 6272 | — |
| Dense скрытый | Dense | 128 | ReLU |
| Dense выходной | Dense | 10 | Softmax |
Регуляризация Dense слоя через Dropout с вероятностью 0.3–0.5 уменьшает переобучение. Перед подачей изображений на слой рекомендуется нормализация пиксельных значений в диапазон [0,1], чтобы ускорить сходимость и повысить точность классификации.
Использование Dense layer для регрессии числовых данных
Для регрессии Dense layer применяют как выходной слой, который предсказывает непрерывные величины. Входные признаки могут быть нормализованы, чтобы ускорить сходимость и избежать больших значений на выходе. Каждый нейрон выходного слоя формирует линейную комбинацию входов, умноженных на веса, с добавлением смещения.
Для скрытых слоев рекомендуется использовать ReLU, что обеспечивает нелинейное преобразование признаков и уменьшает проблему затухающих градиентов. Выходной слой обычно применяет linear активацию, чтобы значения могли принимать любой диапазон.
Количество нейронов в скрытых Dense слоях подбирается экспериментально: для небольших наборов данных достаточно 32–128 нейронов, для сложных задач с большим числом признаков – 256–512. Регуляризация через L2 или Dropout помогает уменьшить переобучение и стабилизировать прогнозы.
Для оценки качества регрессии используют метрики MAE и MSE, что позволяет отслеживать ошибки предсказания и корректировать архитектуру Dense слоев. Оптимизация проводится через методы градиентного спуска с подбором скорости обучения и числа эпох.
Как выбрать количество нейронов в Dense layer
Количество нейронов в Dense layer определяет емкость модели и ее способность извлекать признаки. Подбор оптимального числа нейронов проводится с учетом объема данных, сложности задачи и архитектуры сети.
Рекомендации по выбору:
- Для небольших наборов данных и простых задач достаточно 32–128 нейронов в скрытом слое.
- Для изображений или текстов с большим числом признаков используют 256–512 нейронов.
- Слишком большое количество нейронов повышает риск переобучения, поэтому применяют регуляризацию через Dropout или L2.
- Слишком малое количество нейронов ограничивает способность модели выявлять сложные зависимости, что ведет к низкой точности.
Практический подход к подбору числа нейронов:
- Начать с базового числа нейронов, например 64–128.
- Обучить модель на тренировочной выборке и оценить метрики на валидационной.
- Постепенно увеличивать или уменьшать количество нейронов, наблюдая изменения точности и потерь.
- Использовать кросс-валидацию для проверки стабильности модели при разных конфигурациях.
Для многослойных Dense сетей число нейронов часто уменьшают по мере продвижения к выходу, что позволяет сжать признаки и снизить вычислительные затраты.
Примеры реализации Dense layer на Python с Keras
В Keras Dense layer легко интегрируется в модель через класс Dense. Ниже приведены основные варианты реализации с конкретными рекомендациями.
Пример простой модели для классификации:
- Создание модели Sequential:
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Flatten model = Sequential() model.add(Flatten(input_shape=(28,28))) # преобразование входа model.add(Dense(128, activation='relu')) # скрытый слой model.add(Dense(10, activation='softmax')) # выходной слой - Компиляция и обучение:
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
Для регрессии можно использовать выходной слой с линейной активацией:
model.add(Dense(64, activation='relu')) # скрытый слой
model.add(Dense(1, activation='linear')) # предсказание непрерывной величины
Рекомендации по реализации Dense layer в Keras:
- Использовать нормализацию входных данных через StandardScaler или MinMaxScaler.
- Добавлять Dropout для регуляризации при большом количестве нейронов.
- Подбирать количество нейронов в скрытых слоях экспериментально, начиная с 64–128.
- Выбирать функцию активации в зависимости от задачи: ReLU для скрытых слоев, softmax для многоклассовой классификации, linear для регрессии.
Вопрос-ответ:
Что такое Dense layer и как он работает в нейросети?
Dense layer — это полносвязный слой нейронной сети, где каждый нейрон связан со всеми нейронами предыдущего слоя. Он принимает входные данные, умножает их на матрицу весов, добавляет смещения и пропускает результат через функцию активации. Такой подход позволяет нейросети выявлять сложные зависимости между признаками и формировать итоговое представление данных для последующих слоев.
Как выбрать функцию активации для Dense слоя?
Выбор функции активации зависит от задачи и положения слоя в сети. Для скрытых слоев обычно используют ReLU, которая ускоряет обучение и предотвращает затухание градиентов. Для задач классификации выходного слоя применяют softmax для многоклассовых задач и sigmoid для бинарной классификации. Для регрессии используют линейную активацию, чтобы выход мог принимать любые значения.
Почему важно правильно задавать количество нейронов в Dense layer?
Количество нейронов влияет на способность слоя выделять признаки и комбинировать их для решения задачи. Слишком мало нейронов ограничивает возможности сети, что ведет к низкой точности. Слишком много нейронов увеличивает риск переобучения. Оптимальное количество выбирают экспериментально, анализируя метрики на тренировочной и валидационной выборках, а при необходимости применяют регуляризацию.
Как Dense layer используется для классификации изображений?
После сверточных слоев Dense layer объединяет извлеченные признаки и формирует окончательные прогнозы. Сверточные слои выделяют локальные паттерны, а полносвязный слой интерпретирует их для определения класса изображения. Обычно используют один или два Dense слоя с ReLU в скрытых слоях и softmax на выходе, что позволяет сети предсказывать вероятность принадлежности к каждому классу.
Каким образом Dense layer применяется для регрессии числовых данных?
В регрессии Dense layer выступает как выходной слой, предсказывающий непрерывные значения. Входные признаки нормализуют, скрытые слои используют ReLU для нелинейного преобразования, а выходной слой применяет линейную активацию. Настройка количества нейронов и регуляризация помогают модели точнее прогнозировать значения, а метрики MAE и MSE оценивают качество предсказаний.
Как Dense layer преобразует входные данные и почему это важно для нейросети?
Dense layer выполняет линейное преобразование входных данных, умножая их на веса и добавляя смещения, а затем применяет функцию активации. Каждый нейрон получает сигнал от всех нейронов предыдущего слоя, что позволяет выявлять комбинации признаков и формировать представление данных. Это важно, потому что слой объединяет и интерпретирует признаки, полученные на предыдущих этапах, обеспечивая нейросети способность к точным прогнозам или классификации. Настройка количества нейронов, функции активации и регуляризация весов напрямую влияет на способность модели выделять значимые закономерности и снижать ошибки на новых данных.