В языке C отсутствует готовая структура данных с названием Dictionary, однако сама задача хранения пар «ключ – значение» возникает постоянно: от сопоставления строк с числами до хранения настроек, таблиц символов и кэшей. Поэтому под Dictionary в C обычно понимают пользовательскую реализацию ассоциативного контейнера на основе базовых структур языка.
Чаще всего роль Dictionary выполняет хеш-таблица, где ключ преобразуется в индекс массива с помощью хеш-функции. В более простых сценариях применяют массивы структур или связанные списки, если объём данных небольшой и требования к скорости поиска невысокие. Выбор подхода напрямую влияет на сложность кода, расход памяти и поведение программы под нагрузкой.
Практическая реализация Dictionary в C требует ручного описания структуры ключа, способа сравнения, логики вставки и поиска, а также контроля за выделением и освобождением памяти. Ошибки в этих местах приводят к утечкам, повреждению данных и неопределённому поведению, поэтому важно заранее понимать, какие операции будут выполняться чаще и какие типы ключей планируется использовать.
В этой статье рассматривается, что именно подразумевают под Dictionary в контексте C, какие структуры данных применяют на практике и как реализовать рабочее решение для хранения и поиска данных по ключу без опоры на сторонние библиотеки.
Dictionary в языке C: что это и как используется

В языке C под Dictionary понимают пользовательскую структуру данных для хранения пар «ключ – значение», так как стандартная библиотека не содержит ассоциативных контейнеров. Такая структура применяется, когда требуется быстро находить данные по уникальному идентификатору: строке, числу или набору байт.
На практике Dictionary в C чаще всего реализуют в виде хеш-таблицы. Ключ обрабатывается хеш-функцией, результат которой используется как индекс массива. В ячейке массива хранится значение либо ссылка на список элементов при совпадении индексов. Такой подход подходит для конфигураций, таблиц символов компиляторов, кэшей и сопоставления строк с числовыми кодами.
В простых задачах вместо хеш-таблицы используют массив структур с линейным поиском или связанный список. Это оправдано при небольшом числе элементов, когда важна простота кода и прозрачность логики. Ключи в таких реализациях обычно сравниваются через strcmp для строк или прямым сравнением для чисел.
При использовании Dictionary в C программист самостоятельно задаёт тип ключа, способ сравнения, правила добавления и удаления элементов. Также требуется явно управлять памятью: выделять её под ключи и значения, корректно освобождать при очистке структуры и учитывать срок жизни данных, передаваемых извне.
Dictionary применяют в ситуациях, где фиксированная структура данных не подходит: динамические наборы параметров, обработка входных данных с неизвестными заранее ключами, сопоставление имён с обработчиками функций. Гибкость такой реализации позволяет адаптировать её под конкретную задачу без лишних зависимостей.
Что понимают под Dictionary в C и почему его нет в стандартной библиотеке
Под Dictionary в языке C обычно подразумевают абстрактную модель хранения данных, где каждому ключу соответствует значение. Это не конкретный тип, а соглашение, используемое разработчиками для описания ассоциативных структур, реализованных поверх базовых механизмов языка: массивов, указателей и пользовательских структур.
Ещё одна причина – отсутствие в C встроенной поддержки обобщённых типов. Стандарт не предоставляет механизмов, позволяющих описать контейнер, работающий с произвольными типами ключей и значений без явных преобразований. Любая реализация Dictionary потребовала бы либо ограничений по типам, либо сложных соглашений через void * и функции обратного вызова.
Также стандарт не задаёт модель управления памятью для сложных контейнеров. Решения о том, кто владеет данными – структура или вызывающий код, – зависят от конкретной задачи. Включение Dictionary в стандарт потребовало бы строгих правил, которые не подошли бы для системного и встраиваемого программирования.
Поэтому в C Dictionary существует как прикладная концепция, а не стандартный компонент. Разработчик сам выбирает структуру, формат ключей и логику доступа, получая полный контроль над поведением и ресурсами программы.
Какие структуры данных применяют для реализации Dictionary в C
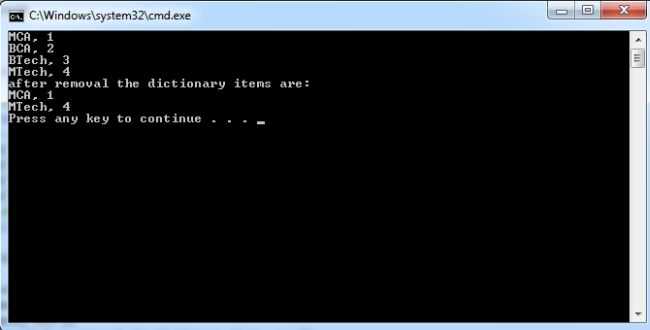
Для реализации Dictionary в C используют несколько базовых структур данных. Выбор зависит от объёма данных, типа ключей и требований к скорости доступа. Ниже перечислены наиболее распространённые варианты, применяемые на практике.
-
Массив структур. Каждый элемент содержит ключ и связанное с ним значение. Поиск выполняется последовательным перебором. Подходит для небольших наборов данных, таблиц соответствий и конфигураций с фиксированным размером.
-
Связанный список. Используется, когда размер Dictionary меняется во время работы программы. Удобен для вставки и удаления элементов, но поиск по ключу остаётся линейным.
-
Хеш-таблица. Самый распространённый вариант. Ключ преобразуется в индекс массива с помощью хеш-функции. В ячейках хранятся элементы или ссылки на цепочки при совпадении индексов.
Хеш-таблицы реализуют несколькими способами разрешения коллизий:
-
Цепочки – в каждой ячейке массива хранится связанный список элементов с одинаковым хешем.
-
Открытая адресация – при совпадении индекса выполняется поиск следующей свободной позиции по заданному алгоритму.
В задачах с упорядоченными ключами применяют деревья поиска, например бинарные деревья. Они позволяют хранить данные в отсортированном виде и выполнять поиск без хеширования, но требуют более сложной логики вставки и балансировки.
На практике для строковых ключей чаще выбирают хеш-таблицы, а для небольших наборов данных – массивы или списки. При проектировании Dictionary в C важно заранее определить, какие операции будут выполняться чаще: добавление, поиск или удаление.
Как описать структуру Dictionary на основе массива и связанных списков
Один из самых распространённых способов описать Dictionary в C – сочетание массива и связанных списков. Массив используется как таблица фиксированного размера, а каждый его элемент указывает на начало списка, в котором хранятся пары «ключ – значение» с одинаковым индексом.
Базовая структура элемента Dictionary обычно включает ключ, значение и указатель на следующий элемент. Для строковых ключей хранят указатель на char *, для числовых – само значение или его копию. Связанный список позволяет добавлять новые элементы без переразметки памяти.
Массив представляет собой набор указателей на первый элемент списка. Его размер задаётся при инициализации Dictionary и определяет диапазон индексов, которые возвращает хеш-функция. От размера массива зависит плотность заполнения списков и длина поиска.
При добавлении элемента ключ обрабатывается хеш-функцией, результат используется как индекс массива. Если по этому индексу список пуст, новый элемент становится первым. Если список уже существует, элемент добавляется в его начало или конец, в зависимости от выбранной логики.
Поиск значения по ключу начинается с вычисления индекса, после чего выполняется последовательный просмотр связанного списка с посимвольным или числовым сравнением ключей. Такой подход упрощает реализацию и снижает риск выхода за границы массива.
При описании структуры важно заранее определить правила владения памятью: копируется ли ключ внутрь Dictionary или хранится ссылка на внешние данные. Для строк чаще выделяют отдельную память под копию, чтобы избежать ошибок при освобождении исходных данных.
Как реализовать добавление и поиск значений по ключу в Dictionary
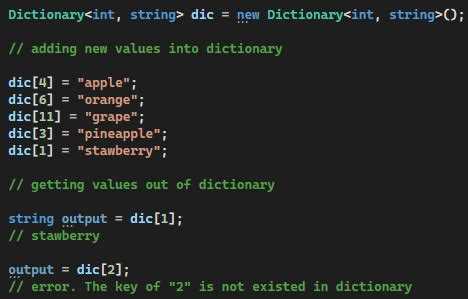
Добавление и поиск элементов в Dictionary на основе массива и связанных списков выполняется через хеширование ключа. Сначала ключ преобразуется в индекс массива с помощью хеш-функции. Затем операция выполняется в списке, соответствующем этому индексу.
Пример структуры таблицы операций:
| Операция | Алгоритм | Рекомендации |
|---|---|---|
| Добавление |
|
Использовать простую, но распределяющую хеш-функцию. Проверять существование ключа, чтобы не дублировать. |
| Поиск |
|
Для длинных списков рассмотреть оптимизацию поиска или увеличение размера массива, чтобы уменьшить длину цепочек. |
Правильное управление памятью при добавлении критично. Ключи и значения должны выделяться отдельно, чтобы Dictionary владел своими данными. При удалении элементов необходимо корректно освобождать память для каждого узла списка.
Вопрос-ответ:
Что такое Dictionary в языке C и как его использовать без стандартной поддержки?
В C Dictionary — это структура данных, которая хранит пары «ключ — значение». В стандартной библиотеке нет готового типа, поэтому разработчик реализует его самостоятельно, используя массивы, связанные списки или хеш-таблицы. Основные задачи — хранение ключей, поиск по ключу и корректное управление памятью.
Какие структуры данных чаще всего применяют для реализации Dictionary в C?
Чаще всего используют массивы структур с линейным поиском, связанные списки и хеш-таблицы. Массив подходит для небольших наборов данных, связанные списки удобны при динамическом изменении количества элементов, а хеш-таблицы обеспечивают быстрый доступ при большом объёме ключей.
Как правильно организовать память при создании Dictionary в C?
Память нужно выделять под ключи и значения отдельно, особенно если ключи — строки. Каждый элемент списка требует выделения памяти для структуры и, при необходимости, копии ключа. При удалении элементов важно освобождать память каждого узла, чтобы избежать утечек.
Какие методы применяются для поиска значений по ключу в Dictionary на основе массива и списков?
Сначала вычисляется индекс массива через хеш-функцию, затем перебираются элементы связанного списка. Для строковых ключей используют strcmp, для числовых — прямое сравнение. Если элемент найден, возвращается его значение; если нет — сигнализируется отсутствие.
Как обработать ситуацию с коллизиями ключей при реализации Dictionary в C?
Коллизии возникают, когда два ключа дают одинаковый индекс хеш-функции. Их можно разрешать с помощью цепочек — связанного списка в каждой ячейке массива, или через открытую адресацию, когда поиск следующей свободной позиции осуществляется по заранее заданной схеме. Выбор метода зависит от объёма данных и требований к скорости добавления и поиска.
Можно ли использовать стандартные структуры данных C для создания Dictionary?
В стандартной библиотеке C нет готового Dictionary, поэтому для реализации используют базовые структуры: массивы, связанные списки и хеш-таблицы. Массивы подходят для небольших наборов данных с прямым доступом по индексу, списки позволяют динамически добавлять элементы, а хеш-таблицы ускоряют поиск при большом объёме ключей.
Как обеспечить корректный поиск и добавление элементов в самописный Dictionary?
Для поиска ключа сначала вычисляется индекс через хеш-функцию, затем выполняется просмотр списка элементов на этом индексе. Добавление элемента происходит аналогично: хеш определяет ячейку массива, в которой создаётся новый узел списка с ключом и значением. Важно правильно выделять память для ключей и значений и проверять, что ключ уже не существует в структуре, чтобы избежать дублирования.