TextIOWrapper в Python обеспечивает преобразование байтовых потоков в текстовые с заданной кодировкой. Он используется совместно с объектами io, такими как BytesIO и BufferedReader, позволяя читать и записывать текст без ручного декодирования. Для работы с файлами с нестандартной кодировкой достаточно передать параметр encoding, например, TextIOWrapper(file, encoding=’utf-8′).
Чтение больших файлов построчно через TextIOWrapper предотвращает загрузку всего содержимого в память. Методы readline() и readlines() позволяют контролировать объем считываемых данных, а использование buffering=1 включит построчную буферизацию для динамического обновления данных при записи.
При работе с сетевыми потоками или сокетами TextIOWrapper преобразует байтовые данные в строки и обратно. Передача аргументов errors=’ignore’ или errors=’replace’ позволяет обрабатывать некорректные символы без прерывания выполнения программы. Это особенно важно при получении данных с разных источников с непредсказуемой кодировкой.
Функции io в сочетании с TextIOWrapper открывают возможности для тестирования и симуляции файловых операций в памяти. BytesIO можно использовать для временного хранения данных, а TextIOWrapper над ним обеспечит стандартные методы чтения и записи текста. Такой подход упрощает обработку данных при разработке скриптов и тестировании модулей без создания реальных файлов.
Python textiowrapper и функции io: практическое применение

TextIOWrapper позволяет работать с текстом поверх байтовых потоков, таких как файлы, сокеты или объекты BytesIO. Для открытия файла с заданной кодировкой используйте io.open(‘file.txt’, ‘r’, encoding=’utf-8′), что гарантирует корректное чтение символов Unicode. При записи текста рекомендуется указывать параметр newline=», чтобы контролировать переносы строк и избежать автоматической конверсии.
При обработке больших файлов или потоков данных TextIOWrapper поддерживает буферизацию. Использование buffering=8192 снижает количество системных вызовов, ускоряя чтение и запись, а методы readline() и readlines(sizehint) позволяют считывать данные порциями для минимизации потребления памяти.
Для сетевых приложений TextIOWrapper оборачивает сокеты через socket.makefile(), превращая байтовые потоки в текстовые. Параметр errors=’replace’ помогает избежать ошибок при получении некорректной кодировки, а flush() обеспечивает немедленную отправку данных при записи.
При тестировании и прототипировании TextIOWrapper удобно использовать с BytesIO. Это позволяет создавать виртуальные текстовые файлы в памяти, проверять функции чтения и записи без создания физических файлов. Такой подход ускоряет разработку и упрощает отладку модулей, работающих с текстовыми потоками.
TextIOWrapper совместим с большинством функций io, включая BufferedReader и BufferedWriter, что позволяет гибко управлять потоками данных. Комбинация этих инструментов упрощает обработку больших объемов текста, преобразование кодировок и интеграцию с сетевыми и файловыми системами без потери контроля над данными.
Как использовать TextIOWrapper для чтения текстовых файлов с разной кодировкой
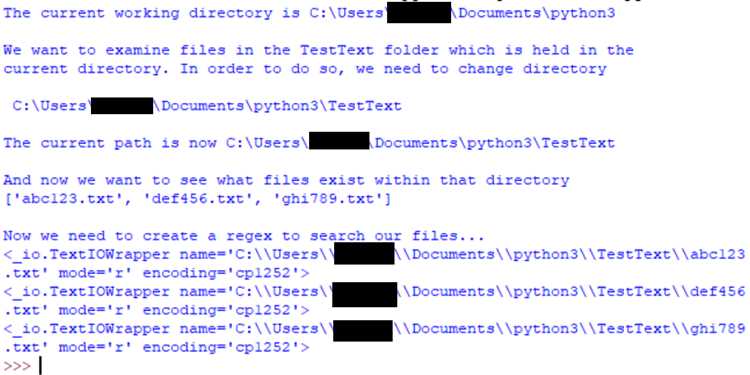
TextIOWrapper позволяет открывать текстовые файлы с указанием конкретной кодировки, что предотвращает ошибки декодирования при работе с файлами, созданными в разных системах. Для этого используется параметр encoding, например: TextIOWrapper(open(‘file.txt’, ‘rb’), encoding=’utf-8′). Если файл содержит нестандартные символы, полезно задавать errors=’replace’ или errors=’ignore’ для корректного чтения без прерывания выполнения программы.
Чтение построчно помогает обрабатывать большие файлы, минимизируя использование памяти. Методы readline() и readlines(sizehint) позволяют контролировать количество считываемых строк. Для демонстрации разных кодировок удобно использовать таблицу соответствия:
| Кодировка | Применение | Пример открытия файла |
|---|---|---|
| UTF-8 | Файлы с Unicode-символами, универсальная кодировка | TextIOWrapper(open(‘file.txt’, ‘rb’), encoding=’utf-8′) |
| CP1251 | Файлы, созданные в Windows с русскими символами | TextIOWrapper(open(‘file.txt’, ‘rb’), encoding=’cp1251′) |
| ISO-8859-1 | Файлы с западноевропейскими символами | TextIOWrapper(open(‘file.txt’, ‘rb’), encoding=’iso-8859-1′) |
Для потокового чтения больших данных рекомендуется сочетать TextIOWrapper с BufferedReader: io.BufferedReader(open(‘file.txt’, ‘rb’)). Это уменьшает количество системных вызовов при построчном чтении, сохраняя корректную обработку кодировки. Такой подход обеспечивает стабильное чтение файлов с любой текстовой кодировкой и упрощает интеграцию с различными источниками данных.
Запись строк в файл через TextIOWrapper с управлением буферизацией
TextIOWrapper позволяет записывать текст в файлы с контролем буферизации через параметр buffering. Значение buffering=0 отключает буферизацию, обеспечивая немедленную запись каждой строки, а buffering=1 включает построчную буферизацию, которая автоматически сбрасывается при символе новой строки. Значения больше 1 задают размер буфера в байтах, что ускоряет запись больших объемов данных.
Для записи строки используется метод write(), а для записи нескольких строк – writelines(). После записи рекомендуется использовать flush() для немедленной фиксации данных на диске, особенно при буферизации. Пример записи с построчной буферизацией:
with open(‘output.txt’, ‘wb’) as f:
wrapper = io.TextIOWrapper(f, encoding=’utf-8′, buffering=1)
wrapper.write(‘Первая строка\n’)
wrapper.writelines([‘Вторая строка\n’, ‘Третья строка\n’])
wrapper.flush()
При работе с большими файлами буферизация снижает количество системных вызовов, ускоряет процесс записи и уменьшает нагрузку на диск. Управление параметрами buffering и своевременный вызов flush() позволяют балансировать между производительностью и сохранностью данных, обеспечивая контроль над записью текстовых потоков.
Конвертация байтовых потоков в текст с помощью io функций
TextIOWrapper позволяет преобразовать байтовые потоки в строки с заданной кодировкой. Для этого байтовый поток передается в конструктор TextIOWrapper, где указывается encoding и опционально errors. Например: wrapper = io.TextIOWrapper(byte_stream, encoding=’utf-8′, errors=’replace’). Параметр errors=’replace’ заменяет некорректные байты символом �, предотвращая ошибки декодирования.
Чтение текста из байтового потока выполняется стандартными методами read(), readline() или readlines(). При работе с сетевыми или временными потоками полезно использовать io.BytesIO для имитации файлов в памяти: byte_stream = io.BytesIO(b’Пример текста’), после чего TextIOWrapper превращает байты в строки для дальнейшей обработки.
Для потоков с переменной кодировкой рекомендуется комбинировать TextIOWrapper с BufferedReader: io.BufferedReader(byte_stream). Это позволяет считывать данные порциями, снижать нагрузку на память и поддерживать корректное преобразование символов. Такой подход особенно полезен при чтении больших файлов, сетевых сообщений или логов, где исходный поток представлен в виде байтов.
Запись текста обратно в байтовый поток выполняется через TextIOWrapper в режиме ‘w’ с указанием кодировки. После записи необходимо вызвать flush(), чтобы все данные были перенесены в основной поток, обеспечивая надежную конвертацию и совместимость с другими процессами, работающими с байтовыми потоками.
Обработка больших файлов построчно без загрузки всего содержимого в память
TextIOWrapper позволяет считывать текстовые файлы построчно, что снижает потребление памяти при работе с большими файлами. Метод readline() возвращает одну строку за раз, а readlines(sizehint) считывает блок строк до указанного количества байт. Такой подход позволяет обрабатывать файлы размером в гигабайты без риска переполнения памяти.
Для ускорения обработки рекомендуется использовать буферизацию через параметр buffering. Например, TextIOWrapper(file, encoding=’utf-8′, buffering=8192) создаёт буфер размером 8 КБ, минимизируя количество системных вызовов при чтении строк. При необходимости можно комбинировать с io.BufferedReader для дополнительного контроля размера блока.
Применение построчного чтения особенно важно при анализе логов, обработке CSV и JSONL файлов, а также при потоковой обработке данных с сетевых источников. Каждая строка может обрабатываться по отдельности, записываться в новый файл или передаваться в обработчик данных без загрузки всего файла в память.
Для гарантии корректного чтения символов с разной кодировкой следует задавать encoding и обрабатывать ошибки с помощью errors=’replace’ или errors=’ignore’. Это обеспечивает стабильную работу скриптов с файлами, созданными в разных системах и приложениях.
Применение TextIOWrapper для работы с сетевыми потоками
TextIOWrapper позволяет оборачивать байтовые потоки сетевых соединений в текстовые, что упрощает чтение и запись данных через сокеты. Использование TextIOWrapper обеспечивает корректное преобразование байтов в строки с заданной кодировкой и обработку ошибок декодирования.
Основные рекомендации при работе с сетевыми потоками:
- Создавать объект TextIOWrapper поверх сокета: wrapper = io.TextIOWrapper(socket.makefile(‘rb’), encoding=’utf-8′, errors=’replace’).
- Использовать метод readline() для построчного чтения сообщений и write() для отправки текста.
- Вызывать flush() после записи, чтобы немедленно отправить данные через сокет.
- Для потоковой обработки больших сообщений применять буферизацию через параметр buffering и методы BufferedReader или BufferedWriter.
Применение TextIOWrapper в сетевых приложениях позволяет:
- Стабильно получать текстовые данные с разной кодировкой, избегая ошибок декодирования.
- Обрабатывать сообщения по мере их поступления, без необходимости хранения всего потока в памяти.
- Комбинировать с асинхронными сокетами для потоковой передачи данных и логирования сообщений.
Использование errors=’ignore’ или errors=’replace’ особенно важно при работе с нестандартными источниками данных, где могут встречаться некорректные байты. Это обеспечивает надежное чтение и запись сетевых сообщений без прерывания работы приложения.
Изменение и контроль параметров кодировки и ошибок при чтении и записи

TextIOWrapper позволяет точно управлять кодировкой текста и поведением при возникновении ошибок декодирования или кодирования. Параметр encoding задаёт формат преобразования байтов в строки, например utf-8, cp1251 или iso-8859-1. Это гарантирует корректное чтение и запись символов из разных источников.
Параметр errors контролирует обработку некорректных байтов:
- ‘strict’ – выбрасывает исключение при любой ошибке.
- ‘replace’ – заменяет некорректные байты символом �.
- ‘ignore’ – пропускает некорректные байты без остановки программы.
- ‘backslashreplace’ – заменяет ошибочные символы на escape-последовательности.
Для изменения кодировки при записи в уже открытый TextIOWrapper можно создать новый объект поверх того же потока с другой кодировкой. Пример:
wrapper = io.TextIOWrapper(file, encoding=’utf-8′, errors=’replace’)
wrapper.write(‘Текст для записи’)
wrapper.flush()
wrapper_new = io.TextIOWrapper(file, encoding=’cp1251′, errors=’ignore’)
Использование этих параметров особенно важно при работе с файлами, полученными из различных систем, или при обмене данными через сети. Управление кодировкой и обработкой ошибок позволяет избегать потери данных и обеспечивает совместимость текстовых потоков между различными платформами.
Вопрос-ответ:
Как использовать TextIOWrapper для чтения файлов с разной кодировкой без ошибок?
Для корректного чтения текстовых файлов с разной кодировкой нужно создать TextIOWrapper поверх байтового потока и указать параметр encoding соответствующей кодировке файла. Если возможны некорректные символы, полезно задать errors=’replace’ или errors=’ignore’, чтобы избежать прерывания выполнения программы. Например: wrapper = io.TextIOWrapper(open(‘file.txt’, ‘rb’), encoding=’utf-8′, errors=’replace’). Построчное чтение через readline() снижает нагрузку на память при больших файлах.
Как правильно записывать строки в файл с буферизацией через TextIOWrapper?
TextIOWrapper поддерживает управление буферизацией через параметр buffering. Для построчной буферизации используется buffering=1, что позволяет автоматически сбрасывать буфер при символе новой строки. При записи большого объема данных можно указать размер буфера в байтах, например buffering=8192, чтобы ускорить запись. После завершения записи рекомендуется вызвать flush(), чтобы записанные данные немедленно попали на диск.
Можно ли использовать TextIOWrapper для обработки сетевых потоков и как это сделать?
Да, TextIOWrapper можно использовать для работы с сетевыми потоками. Сначала нужно обернуть сокет в байтовый поток через socket.makefile(‘rb’), а затем создать TextIOWrapper с нужной кодировкой. Для чтения строк используется readline(), а для отправки текста – write(). После записи текста следует вызвать flush(), чтобы данные были немедленно отправлены через сокет. Параметр errors=’replace’ помогает обрабатывать некорректные байты без прерывания соединения.
Как конвертировать байтовый поток в текст для дальнейшей обработки в Python?
Для преобразования байтового потока в текст создают объект TextIOWrapper поверх байтового потока, указывая кодировку и способ обработки ошибок. Например, для данных в памяти можно использовать BytesIO: byte_stream = io.BytesIO(b’Пример текста’) и затем wrapper = io.TextIOWrapper(byte_stream, encoding=’utf-8′, errors=’replace’). После этого методы read(), readline() и readlines() позволяют получать текст для анализа или передачи дальше.
Как читать очень большие файлы без загрузки всего содержимого в память?
TextIOWrapper поддерживает построчное чтение, что позволяет обрабатывать большие файлы без полного считывания в память. Для этого используют метод readline() или readlines(sizehint). Буферизация через buffering уменьшает количество системных вызовов и ускоряет работу. Кроме того, можно сочетать TextIOWrapper с io.BufferedReader для контроля размера блока данных, что удобно при обработке логов, CSV или других больших текстовых файлов.
Как правильно обрабатывать файлы с разной кодировкой через TextIOWrapper без потери данных?
Для корректного чтения файлов с разной кодировкой TextIOWrapper создается поверх байтового потока с указанием параметра encoding, соответствующего кодировке файла. Если встречаются некорректные символы, используют errors=’replace’ или errors=’ignore’, чтобы программа не прерывалась. Построчное чтение через readline() снижает нагрузку на память при больших файлах. Например: wrapper = io.TextIOWrapper(open(‘file.txt’, ‘rb’), encoding=’cp1251′, errors=’replace’). Такой подход обеспечивает стабильное получение текста независимо от исходного формата файла.
Можно ли использовать TextIOWrapper для временного хранения текста в памяти и как это сделать?
Да, для хранения текста в памяти применяют io.BytesIO совместно с TextIOWrapper. Сначала создается байтовый поток: buffer = io.BytesIO(), затем поверх него TextIOWrapper с указанием кодировки: wrapper = io.TextIOWrapper(buffer, encoding=’utf-8′). Методы write() и writelines() позволяют записывать строки, а read() или readline() – получать текст обратно. Такой подход упрощает тестирование функций обработки текста или создание временных текстовых данных без создания физических файлов на диске.