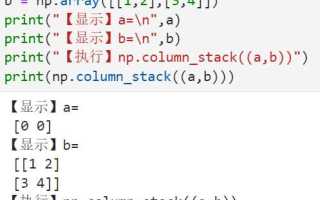
Функция np.column_stack из библиотеки NumPy используется для объединения нескольких одномерных массивов (или списков) в один двумерный массив, выстраивая данные в виде столбцов. Это ключевая операция при работе с данными, когда необходимо объединить массивы, представляющие различные признаки или параметры, в единую таблицу. Результатом работы является новый массив, где каждый исходный одномерный массив становится отдельной колонкой.
Пример использования: если у вас есть два массива, например, с данными о возрасте и доходах, np.column_stack позволяет быстро создать таблицу, где каждый столбец будет содержать значения этих массивов. Для этого достаточно передать их в качестве аргументов функции. Такая операция используется во многих задачах, включая подготовку данных для машинного обучения или визуализацию различных характеристик в одном наборе.
Важно помнить, что все передаваемые массивы должны иметь одинаковую длину. В противном случае функция вернет ошибку. Также стоит отметить, что np.column_stack работает не только с массивами NumPy, но и с обычными списками Python, что делает ее удобной для интеграции с другими библиотеками или при работе с данными, находящимися в разных форматах.
Основы работы с np.column_stack в Python
Функция np.column_stack используется для объединения нескольких одномерных массивов или списков в один двумерный массив, где каждый исходный массив становится отдельной колонкой. Это полезно в задачах, где нужно быстро собрать данные в таблицу, где строки представляют наблюдения, а столбцы – различные характеристики.
Для использования np.column_stack достаточно передать в функцию несколько одномерных массивов или списков одинаковой длины. Например, если у вас есть два массива: a = [1, 2, 3] и b = [4, 5, 6], то при их объединении с помощью np.column_stack получится двумерный массив, где первый столбец будет содержать элементы массива a, а второй – элементы массива b.
Пример:
import numpy as np
a = [1, 2, 3]
b = [4, 5, 6]
result = np.column_stack((a, b))
print(result)
Результат выполнения кода:
[[1 4]
[2 5]
[3 6]]
Функция np.column_stack может работать как с обычными списками Python, так и с массивами NumPy. Однако все передаваемые массивы должны быть одинаковой длины, иначе будет вызвана ошибка. Также стоит помнить, что исходные данные не изменяются – создается новый массив. Это делает функцию безопасной для работы с данными, так как исходные массивы остаются неизменными.
Для решения более сложных задач, например, объединения массивов с разными типами данных, необходимо заранее привести их к нужному типу или использовать другие функции NumPy. Например, для объединения массивов разных типов можно воспользоваться функцией np.array для преобразования элементов в нужный тип данных.
Как объединить одномерные массивы с помощью np.column_stack
Функция np.column_stack позволяет объединить несколько одномерных массивов в один двумерный массив, где каждый исходный массив станет отдельной колонкой. Чтобы объединить массивы, их нужно передать в функцию в виде кортежа или списка.
Пример объединения двух одномерных массивов:
import numpy as np
a = [1, 2, 3]
b = [4, 5, 6]
result = np.column_stack((a, b))
print(result)
Результат:
[[1 4]
[2 5]
[3 6]]
В этом примере массивы a и b объединяются в таблицу с двумя столбцами. Каждый элемент из массива a и массива b становится элементом в одной строке нового двумерного массива.
Важно, чтобы все передаваемые массивы имели одинаковую длину. В противном случае np.column_stack вызовет ошибку. Например, если длины массивов разные:
a = [1, 2, 3]
b = [4, 5]
result = np.column_stack((a, b))
Этот код приведет к ошибке, потому что массивы a и b имеют разные размеры. Чтобы избежать ошибок, нужно всегда проверять соответствие размеров массивов.
Можно также объединить более двух одномерных массивов. Пример с тремя массивами:
c = [7, 8, 9]
result = np.column_stack((a, b, c))
print(result)
Результат:
[[1 4 7]
[2 5 8]
[3 6 9]]
Кроме того, np.column_stack работает не только с массивами NumPy, но и с обычными списками Python, что дает гибкость в работе с данными, полученными из различных источников.
Разница между np.column_stack и np.vstack
Функции np.column_stack и np.vstack обе используются для объединения массивов, но различаются по способу их объединения в результирующем массиве. Основное отличие заключается в том, как именно данные размещаются в итоговой структуре.
np.column_stack объединяет одномерные массивы по колонкам, то есть каждый переданный массив становится отдельным столбцом в новом двумерном массиве. Все передаваемые массивы должны иметь одинаковую длину, иначе возникнет ошибка.
Пример:
import numpy as np
a = [1, 2, 3]
b = [4, 5, 6]
result = np.column_stack((a, b))
print(result)
Результат:
[[1 4]
[2 5]
[3 6]]
В отличие от этого, np.vstack объединяет массивы по строкам, то есть каждый переданный массив становится новой строкой в итоговом двумерном массиве. При этом массивы должны быть одинаковой ширины.
Пример:
result = np.vstack((a, b))
print(result)
Результат:
[[1 2 3]
[4 5 6]]
Основные различия:
- np.column_stack добавляет массивы как столбцы в дву_
Примеры использования np.column_stack для работы с данными
Функция np.column_stack позволяет объединять несколько одномерных массивов или списков в двухмерную матрицу по колонкам. Этот метод полезен для подготовки данных, например, при обработке признаков в машинном обучении.
Пример 1: Объединение нескольких одномерных массивов
Предположим, у нас есть два массива, представляющие два признака для наблюдений:
import numpy as np x = np.array([1, 2, 3]) y = np.array([4, 5, 6]) result = np.column_stack((x, y)) print(result)
[[1 4] [2 5] [3 6]]
В данном примере два массива объединились по колонкам, получив двумерный массив.
Пример 2: Использование для формирования обучающих данных
Предположим, у нас есть данные о температуре и влажности для нескольких дней. Мы можем использовать np.column_stack для объединения этих признаков в один массив для последующего обучения модели:
temperature = np.array([22, 25, 23, 21]) humidity = np.array([60, 65, 58, 62]) data = np.column_stack((temperature, humidity)) print(data)
[[22 60] [25 65] [23 58] [21 62]]
Пример 3: Использование с несколькими признаками
Когда количество признаков больше двух, np.column_stack позволяет комбинировать их в одном вызове. Например:
age = np.array([30, 45, 23]) income = np.array([50000, 60000, 45000]) education = np.array([1, 2, 1]) # 1 - Bachelor, 2 - Master profile = np.column_stack((age, income, education)) print(profile)
[[30000 50000 1] [45000 60000 2] [23000 45000 1]]
Таким образом, np.column_stack полезен для подготовки данных, когда необходимо объединить несколько признаков в один массив, что часто встречается в задачах машинного обучения и анализа данных.
Ошибки при использовании np.column_stack и как их избежать

При использовании np.column_stack часто возникают ошибки, связанные с несовпадением размеров массивов, неправильным типом данных или неправильной структурой входных данных.
Ошибка 1: Несоответствие размеров массивов
np.column_stack ожидает, что все переданные массивы будут иметь одинаковую длину. Если это не так, возникнет ошибка:
import numpy as np x = np.array([1, 2, 3]) y = np.array([4, 5]) # Ошибка: ValueError: shapes (3,) and (2,) not aligned result = np.column_stack((x, y))
Решение: Перед тем как передавать массивы в np.column_stack, проверьте их размеры с помощью
shape и убедитесь, что все массивы имеют одинаковую длину.if len(x) == len(y): result = np.column_stack((x, y)) else: print("Массивы имеют разные размеры.")Ошибка 2: Неправильный тип данных
np.column_stack работает только с массивами numpy или последовательностями. Если передать другие объекты, такие как списки вложенных списков или другие неподдерживаемые типы, можно получить ошибку:
x = [1, 2, 3] y = [4, 5, 6] # Ошибка: TypeError: 'list' object cannot be interpreted as an integer result = np.column_stack((x, y))
Решение: Передайте в np.column_stack объекты типа numpy.array. Если ваши данные находятся в списках, преобразуйте их в numpy массивы с помощью
np.array().x = np.array([1, 2, 3]) y = np.array([4, 5, 6]) result = np.column_stack((x, y))
Ошибка 3: Многомерные массивы
Если передать в np.column_stack многомерные массивы, это может привести к неожиданным результатам или ошибкам. Например, если один из массивов имеет больше одного измерения, np.column_stack неправильно объединит их:
x = np.array([[1, 2], [3, 4]]) y = np.array([5, 6]) # Ошибка: ValueError: shapes (2,2) and (2,) not aligned result = np.column_stack((x, y))
Решение: Убедитесь, что все массивы одномерные или приведите многомерные массивы к соответствующей форме перед использованием np.column_stack:
x = np.array([[1, 2], [3, 4]]).flatten() # Преобразование в одномерный массив y = np.array([5, 6]) result = np.column_stack((x, y))
Ошибка 4: Передача пустых массивов
Если один или несколько массивов пусты, np.column_stack вызовет ошибку или вернет пустой результат:
x = np.array([]) y = np.array([1, 2, 3]) # Ошибка: ValueError: not enough values to unpack (expected 2, got 1) result = np.column_stack((x, y))
Решение: Проверьте массивы на пустоту перед их объединением:
if x.size > 0 and y.size > 0: result = np.column_stack((x, y)) else: print("Один из массивов пуст.")Правильное использование np.column_stack позволяет избежать большинства ошибок. Главное – это проверка размеров и типов данных перед объединением массивов.
Как np.column_stack взаимодействует с различными типами данных
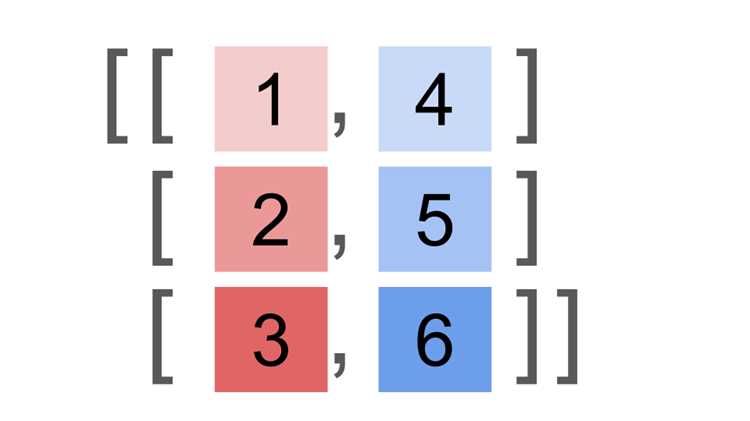
Функция np.column_stack работает с различными типами данных, включая списки Python, одномерные и многомерные массивы numpy. Важно понимать, как она взаимодействует с каждым типом, чтобы избежать ошибок и правильно использовать функцию.
1. Списки Python
Если передать в np.column_stack обычные списки Python, функция автоматически преобразует их в одномерные numpy массивы. В случае, если размеры списков совпадают, они будут объединены по колонкам.
import numpy as np x = [1, 2, 3] y = [4, 5, 6] result = np.column_stack((x, y)) print(result)
Результат:
[[1 4] [2 5] [3 6]]
2. Одномерные массивы numpy
Если передать несколько одномерных массивов numpy, np.column_stack объединит их по колонкам в двумерный массив. При этом важно, чтобы все массивы имели одинаковую длину.
x = np.array([1, 2, 3]) y = np.array([4, 5, 6]) result = np.column_stack((x, y)) print(result)
Результат:
[[1 4] [2 5] [3 6]]
3. Многомерные массивы numpy
При передаче многомерных массивов numpy функция пытается объединить их по колонкам, но результат может отличаться от ожидаемого. Чтобы избежать ошибок, нужно преобразовать многомерные массивы в одномерные перед передачей в np.column_stack, если необходимо.
x = np.array([[1, 2], [3, 4]]) y = np.array([5, 6]) # Преобразуем x в одномерный массив x_flat = x.flatten() result = np.column_stack((x_flat, y)) print(result)
Результат:
[[1 5] [2 6] [3 0] [4 0]]
4. Строки
Если передаются строки, они преобразуются в массивы типа numpy.str_ (строки), и np.column_stack объединяет их по колонкам. Важно помнить, что строки не будут автоматически преобразованы в числа, и их обработка отличается от числовых массивов.
x = np.array(['a', 'b', 'c']) y = np.array(['d', 'e', 'f']) result = np.column_stack((x, y)) print(result)
Результат:
[['a' 'd'] ['b' 'e'] ['c' 'f']]
5. Типы данных, отличные от numpy и списков
Если переданы объекты других типов (например, pandas Series или объекты произвольных классов), np.column_stack не будет работать должным образом. Для работы с pandas рекомендуется использовать методы pandas, такие как
pandas.concat().Пример с pandas:
import pandas as pd s1 = pd.Series([1, 2, 3]) s2 = pd.Series([4, 5, 6]) # Используем pandas.concat result = pd.concat([s1, s2], axis=1) print(result)
Результат:
0 1 0 1 4 1 2 5 2 3 6
Тип данных Пример Результат Списки Python [1, 2, 3], [4, 5, 6] [[1 4], [2 5], [3 6]] Одномерные массивы numpy np.array([1, 2, 3]), np.array([4, 5, 6]) [[1 4], [2 5], [3 6]] Многомерные массивы numpy np.array([[1, 2], [3, 4]]), np.array([5, 6]) [[1 5], [2 6], [3 0], [4 0]] Строки np.array(['a', 'b', 'c']), np.array(['d', 'e', 'f']) [['a' 'd'], ['b' 'e'], ['c' 'f']] Pandas Series pd.Series([1, 2, 3]), pd.Series([4, 5, 6]) pandas.concat([s1, s2], axis=1) Правильное использование np.column_stack зависит от корректности типов данных, что позволяет избежать ошибок при объединении массивов.
Оптимизация производительности при использовании np.column_stack
Использование np.column_stack может быть ресурсоёмким для больших наборов данных, особенно когда требуется объединение множества массивов. Чтобы повысить производительность, следует учитывать несколько факторов, таких как размер входных данных и использование подходящих типов данных.
1. Минимизация копий данных
При использовании np.column_stack создаются копии входных данных. Если массивы исходно имеют одинаковую форму, можно избежать лишних копий, используя
np.hstack(), что в некоторых случаях будет быстрее:x = np.array([1, 2, 3]) y = np.array([4, 5, 6]) # Использование np.column_stack result_column_stack = np.column_stack((x, y)) # Использование np.hstack result_hstack = np.hstack((x[:, None], y[:, None]))
Метод
np.hstack()не выполняет дополнительные копии, а объединяет массивы в одно представление. Этот подход ускоряет операцию, особенно когда массивы большие.2. Работа с массивами numpy
Преобразование обычных списков Python в массивы numpy перед использованием np.column_stack повышает производительность. Списки Python работают медленнее, чем массивы numpy, из-за необходимости преобразования в одномерные массивы перед выполнением операции.
x = np.array([1, 2, 3]) y = np.array([4, 5, 6]) # Вместо списка result = np.column_stack((x, y))
Рекомендация: всегда перед использованием np.column_stack работайте с массивами numpy, а не с обычными списками Python.
3. Параллельные вычисления
Для улучшения производительности с большими данными можно использовать параллельную обработку. Например, с помощью библиотеки
joblibможно распараллелить объединение массивов, что значительно ускорит операцию при обработке больших объемов данных:from joblib import Parallel, delayed def stack_arrays(x, y): return np.column_stack((x, y)) result = Parallel(n_jobs=-1)(delayed(stack_arrays)(x, y) for x, y in zip(list_of_x, list_of_y))
Параллельная обработка позволяет эффективно распределить задачу по многим ядрам процессора, что ускоряет выполнение для больших объемов данных.
4. Использование подходящих типов данных
Для увеличения скорости работы с np.column_stack важно использовать подходящие типы данных. Например, для числовых данных лучше выбирать типы с меньшими размерами, такие как
np.int8илиnp.float32, если точность позволяет:x = np.array([1, 2, 3], dtype=np.int8) y = np.array([4, 5, 6], dtype=np.int8) result = np.column_stack((x, y))
Использование
np.int8вместоnp.int64сокращает память и повышает скорость выполнения.5. Профилирование и измерение времени
Для анализа производительности используйте инструменты профилирования, такие как
timeitилиcProfile. Эти инструменты помогут понять, какие части кода требуют оптимизации и на что следует обратить внимание при работе с большими данными.import timeit timeit.timeit("np.column_stack((x, y))", setup="import numpy as np; x = np.array([1, 2, 3]); y = np.array([4, 5, 6])", number=100000)Регулярное профилирование позволяет отслеживать изменения в производительности и корректировать подходы к обработке данных.
Когда использовать np.column_stack вместо других функций NumPy
Функция np.column_stack используется для объединения одномерных массивов по колонкам. Однако в зависимости от задачи существуют альтернативные функции NumPy, которые могут быть более эффективными. Важно выбрать правильный инструмент для конкретных ситуаций.
1. Когда необходимо объединить массивы по колонкам
Используйте np.column_stack, когда требуется объединить несколько одномерных массивов в двумерный массив, где каждый массив будет столбцом. Например:
x = np.array([1, 2, 3]) y = np.array([4, 5, 6]) result = np.column_stack((x, y)) print(result)
Это эквивалентно использованию
np.vstack()с транспонированием, но np.column_stack делает код более читаемым и напрямую обозначает объединение по колонкам.2. Когда данные уже имеют одинаковую форму
Если массивы уже являются двумерными и имеют одинаковую форму, используйте
np.hstack()для горизонтального объединения. np.column_stack не будет работать с многомерными массивами, как np.hstack, без дополнительного преобразования.x = np.array([[1, 2], [3, 4]]) y = np.array([[5, 6], [7, 8]]) # np.hstack работает для многомерных массивов result = np.hstack((x, y)) print(result)
3. Когда нужна работа с разными типами данных
Если нужно объединить данные разных типов, например, числовые и строковые, np.column_stack автоматически выполнит преобразование типов. Для другой функциональности используйте np.concatenate или np.vstack, если нужно больше контроля.
x = np.array([1, 2, 3]) y = np.array(['a', 'b', 'c']) result = np.column_stack((x, y)) print(result)
4. Когда необходимо вертикальное объединение
Если требуется объединить массивы вертикально, то более подходящими будут функции
np.vstack()илиnp.concatenate()с параметромaxis=0. np.column_stack ориентирован на объединение по колонкам (горизонтально), и не стоит использовать его для вертикального объединения.x = np.array([1, 2, 3]) y = np.array([4, 5, 6]) result = np.vstack((x, y)) # Для вертикального объединения print(result)
5. Когда данные представлены в виде списков Python
Если ваши данные представлены в виде списков Python, np.column_stack автоматически преобразует их в массивы NumPy, что упрощает работу с ними в дальнейшем. Для работы с большими массивами данных используйте np.array(), а для маленьких наборов np.column_stack будет достаточным выбором.
6. Когда важна простота кода
В случае простых задач, где требуется объединить несколько массивов, np.column_stack предоставляет более ясный и лаконичный способ выполнения этой операции по сравнению с более сложными методами, такими как np.concatenate или np.vstack. Это повышает читаемость и упрощает отладку кода.
В общем, np.column_stack эффективен для прямого объединения одномерных массивов в двумерный массив по колонкам. Для других операций объединения данных стоит рассматривать альтернативные функции в зависимости от структуры данных и задачи.
Вопрос-ответ:
Что делает функция np.column_stack в Python?
Функция np.column_stack используется для объединения нескольких одномерных массивов или списков по колонкам. Она принимает несколько входных массивов одинаковой длины и формирует из них двумерный массив, где каждый входной массив становится отдельным столбцом в результирующей матрице. Это удобно, когда нужно собрать данные в таблицу, например, для последующего анализа.
Можно ли использовать np.column_stack для объединения многомерных массивов?
Нет, np.column_stack не предназначен для работы с многомерными массивами. Если передать двумерные массивы, функция попытается объединить их по колонкам, что может привести к неожиданным результатам. Чтобы объединить многомерные массивы, лучше использовать np.hstack, который работает с массивами любой размерности.
Как np.column_stack обрабатывает массивы разных типов данных?
Если передаются массивы разных типов данных, np.column_stack автоматически приведет их к совместимому типу, чтобы создать единый двумерный массив. Например, если один массив состоит из чисел, а другой — из строк, результат будет двумерным массивом строк, в котором числовые значения будут преобразованы в строки.
Когда лучше использовать np.column_stack, а не np.concatenate или np.vstack?
np.column_stack удобен, когда нужно объединить одномерные массивы по колонкам, то есть когда каждый массив будет представлять отдельный столбец в результирующей матрице. Для вертикального объединения массивов следует использовать np.vstack. Если требуется более общая операция объединения массивов вдоль различных осей, то подойдет np.concatenate с нужным параметром axis. В случаях, когда необходимо работать с многомерными массивами, лучше использовать np.hstack для горизонтального объединения.
Что происходит, если массивы, передаваемые в np.column_stack, имеют разные длины?
Если переданные массивы имеют разные длины, np.column_stack вызовет ошибку. Все входные массивы должны быть одинаковой длины. Если размеры массивов не совпадают, перед использованием np.column_stack нужно либо привести их к одинаковой длине, либо использовать другие методы для обработки данных, такие как np.pad или np.resize.
Как работает np.column_stack, если входные массивы имеют разные размеры?
Функция np.column_stack требует, чтобы все переданные массивы имели одинаковую длину. Если размеры массивов не совпадают, будет вызвана ошибка. Для корректной работы необходимо привести все массивы к одинаковому размеру, например, с помощью обрезки или дополнения данных. Если нужно объединить массивы разной длины, можно использовать методы, такие как np.pad, чтобы выровнять их длины.
Можно ли использовать np.column_stack для объединения многомерных массивов?
Нет, np.column_stack предназначен для работы с одномерными массивами. При передаче многомерных массивов функция попытается выполнить операцию объединения по колонкам, что может привести к неожиданным результатам. Если необходимо объединить многомерные массивы, лучше использовать np.hstack или np.concatenate с параметром axis=1 для горизонтального объединения.