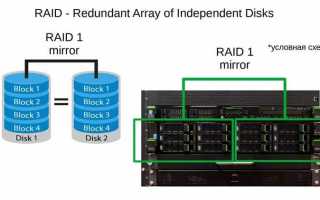
RAID массив объединяет несколько физических дисков в единую систему хранения данных, увеличивая производительность и надежность. Проверка состояния массива позволяет выявить деградирующие или отказавшие диски до возникновения потери данных. Регулярная диагностика особенно важна для массивов с уровнями RAID 5 и RAID 6, где потеря одного диска может привести к снижению избыточности.
Для анализа состояния массива используют встроенные утилиты контроллера RAID или сторонние программы. Команды типа megacli, storcli и mdadm показывают текущий статус дисков, уровень деградации, синхронизацию и наличие ошибок чтения/записи. SMART данные отдельных дисков помогают оценить риск отказа по физическим параметрам, таким как количество переназначенных секторов и время работы.
Проверка содержимого массива без его разрушения осуществляется через монтирование логических томов или использование функций read-only в утилитах диагностики. Это позволяет убедиться в целостности файловой системы, определить доступность критичных данных и своевременно выполнять резервное копирование. Комбинация мониторинга состояния и проверки содержимого обеспечивает контроль над работоспособностью массива и минимизирует риск потери информации.
Проверка состояния и содержимого RAID массива

SMART данные отдельных дисков анализируются с помощью smartctl -a /dev/sdX. Важно обращать внимание на Reallocated_Sector_Ct, Current_Pending_Sector и Offline_Uncorrectable, так как высокие значения указывают на повышенный риск отказа диска. Для массивов RAID 1, 5 и 6 деградация одного диска снижает отказоустойчивость, поэтому такие диски рекомендуется заменить сразу после выявления проблем.
Проверка содержимого массива проводится через монтирование логических томов в режиме read-only или использование специализированных утилит для проверки файловой системы без записи. Это позволяет убедиться в целостности данных и корректности структуры каталогов. Рекомендуется выполнять контрольные проверки не реже одного раза в месяц и вести журнал результатов, чтобы отслеживать динамику состояния массива и своевременно реагировать на ошибки.
Определение типа RAID массива на сервере
Для точного мониторинга и управления RAID массивом важно знать его тип и конфигурацию. Различают аппаратные и программные массивы, и методы определения типа отличаются.
Для программных массивов Linux используют команду mdadm —detail /dev/mdX, которая отображает:
- Уровень RAID (например, RAID 0, RAID 1, RAID 5, RAID 6);
- Количество активных и спящих дисков;
- Статус синхронизации и процент завершения операции;
- Идентификаторы физических дисков, входящих в массив.
Для аппаратных контроллеров применяются утилиты:
- storcli /c0 /v0 show – показывает виртуальный диск, тип RAID, состояние и физические диски;
- BIOS/UEFI RAID контроллера – позволяет визуально определить тип массива и текущий статус при загрузке.
После определения типа RAID важно задокументировать конфигурацию массива и проверить соответствие физической структуры заявленному уровню. Это поможет правильно планировать диагностику, резервное копирование и замену дисков при необходимости.
Использование встроенных утилит для диагностики RAID
Для контроля состояния RAID массива применяются утилиты, встроенные в операционную систему или предоставляемые производителем контроллера. В Linux для программных массивов используется mdadm. Команда mdadm —detail /dev/mdX отображает:
- Статус массива (active, degraded, inactive);
- Количество и идентификаторы активных дисков;
- Прогресс синхронизации и восстановительных операций;
Для аппаратных контроллеров доступны специализированные утилиты:
- storcli – показывает состояние виртуальных и физических дисков, наличие деградирующих томов и логов ошибок;
- megacli – позволяет выполнить тесты на чтение/запись, определить состояние батареи кэша и получить отчет о физических дисках;
- HP Array Configuration Utility (ACU) и Dell OpenManage – предоставляют графический и командный интерфейс для мониторинга и диагностики RAID массивов.
При использовании встроенных утилит важно выполнять диагностику в режиме read-only или тестовые проверки, чтобы не нарушить целостность данных. Регулярное выполнение таких проверок помогает выявлять деградирующие диски и предотвращает потерю информации.
Проверка состояния дисков в массиве

Контроль состояния отдельных дисков RAID массива позволяет выявить потенциальные сбои до их проявления на уровне всего массива. Основные показатели, на которые следует обращать внимание:
- Статус диска: Online, Degraded, Failed – отображается в утилитах mdadm, storcli, megacli;
- SMART данные: количество переназначенных секторов (Reallocated_Sector_Ct), ожидающих переназначение секторов (Current_Pending_Sector), необрабатываемых ошибок (Offline_Uncorrectable);
- Время наработки на отказ (Power-On Hours): используется для оценки износа диска;
- Температура диска: превышение 50–55°C повышает риск повреждения.
Рекомендуется регулярно выполнять следующие действия:
- Проверка SMART с помощью smartctl -a /dev/sdX для каждого диска;
- Сравнение показателей с допустимыми значениями производителя;
- Фиксация всех отклонений в журнале и планирование замены дисков с критическими параметрами;
- Проверка состояния дисков после замены или восстановления массива для подтверждения корректной работы.
Систематический мониторинг состояния дисков снижает вероятность деградации массива и обеспечивает своевременное реагирование на физические сбои.
Чтение SMART данных для отдельных дисков
SMART (Self-Monitoring, Analysis and Reporting Technology) предоставляет подробные данные о состоянии жестких дисков и SSD в RAID массиве. Для анализа используют утилиту smartctl из пакета smartmontools. Основные команды:
- smartctl -H /dev/sdX – проверка общего статуса здоровья диска;
- smartctl -t short /dev/sdX и -t long – тесты чтения/записи для диагностики диска.
Ключевые SMART параметры, на которые следует обращать внимание:
| Параметр | Описание | Рекомендации |
|---|---|---|
| Reallocated_Sector_Ct | Количество переназначенных секторов | Если значение растет, планировать замену диска |
| Current_Pending_Sector | Секторы, ожидающие переназначения | Любое ненулевое значение требует проверки и резервного копирования |
| Offline_Uncorrectable | Секторы с необрабатываемыми ошибками | Диск с ненулевым значением лучше заменить |
| Power_On_Hours | Время работы диска в часах | Используется для оценки износа и планирования замены |
| Temperature_Celsius | Температура диска | Поддерживать в пределах 35–50°C |
Регулярное чтение и анализ SMART данных позволяет выявлять деградацию дисков до отказа, корректно планировать их замену и минимизировать риск потери данных в RAID массиве.
Просмотр содержимого массива без потери данных

Для проверки данных RAID массива без риска их повреждения следует использовать режим read-only или монтировать логический том в безопасном режиме. В Linux программные массивы монтируются через:
- mount -o ro /dev/mdX /mnt/raid – монтирование массива только для чтения;
- Использование rsync —dry-run или cp -n для проверки файловой структуры и доступности данных без записи.
Для аппаратных контроллеров утилиты storcli и megacli позволяют выполнить диагностику томов и просмотреть содержимое логических дисков без модификации данных. Важно:
- Не выполнять операции rebuild или repair во время анализа содержимого;
- Проверять целостность файловой системы через fsck -n или встроенные инструменты Windows (chkdsk /scan);
- Фиксировать результаты в журнале для дальнейшего мониторинга состояния массива.
Регулярный просмотр содержимого позволяет выявить поврежденные файлы, несоответствия в структуре каталогов и контролировать доступность критичных данных без риска потери информации.
Использование командной строки для проверки RAID
Командная строка позволяет быстро получить полную информацию о состоянии RAID массива и отдельных дисков без установки дополнительного ПО. В Linux для программных массивов применяют mdadm:
- mdadm —detail /dev/mdX – показывает уровень RAID, статус массива, количество активных и спящих дисков, прогресс синхронизации;
- cat /proc/mdstat – позволяет оперативно отслеживать текущее состояние всех массивов на сервере.
Для аппаратных контроллеров командная строка предоставляет расширенные возможности диагностики:
- storcli /c0 /v0 show – отображает состояние виртуального диска, уровень RAID, список физических дисков;
Рекомендуется использовать командную строку для регулярного мониторинга, автоматизации проверки через скрипты и интеграции с системами уведомлений, что позволяет своевременно выявлять деградацию массива и предотвращать потерю данных.
Реагирование на ошибки и деградацию массива
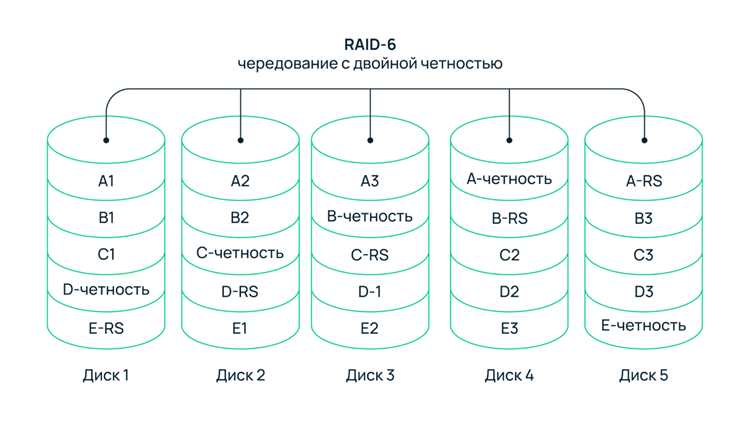
Если диск отмечен как degraded или failed:
- Отключить диск от массива и подготовить к замене;
- Подготовить новый диск того же объема и типа;
- Добавить диск в массив с помощью команд mdadm —add /dev/mdX /dev/sdY для программного RAID или storcli /c0 /v0 start rebuild для аппаратного;
- Следить за прогрессом восстановления через cat /proc/mdstat или встроенные команды контроллера.
При обнаружении ошибок чтения/записи на нескольких дисках рекомендуется:
- Выполнить резервное копирование критичных данных;
- Проверить файловую систему на наличие повреждений с помощью fsck -n или chkdsk /scan;
- Регулярно контролировать SMART данные для оставшихся дисков;
- Планировать профилактическую замену дисков с повышенным количеством переназначенных секторов или других критических параметров.
Своевременное реагирование на ошибки и деградацию обеспечивает восстановление массива без потери данных и поддерживает отказоустойчивость RAID системы.
Вопрос-ответ:
Как определить тип RAID массива на сервере без графического интерфейса?
Для определения типа RAID массива через командную строку в Linux можно использовать mdadm —detail /dev/mdX для программных массивов. Эта команда показывает уровень RAID, статус массива, количество активных и спящих дисков, а также прогресс синхронизации. Для аппаратных контроллеров применяют storcli /c0 /v0 show или megacli -LDInfo -Lall -aALL, которые предоставляют сведения о логических и физических дисках, состоянии массива и возможных ошибках.
Какие SMART параметры дисков наиболее критичны для RAID массива?
При проверке дисков в RAID массиве особое внимание уделяется Reallocated_Sector_Ct (количество переназначенных секторов), Current_Pending_Sector (секторы, ожидающие переназначения) и Offline_Uncorrectable (секторы с необрабатываемыми ошибками). Высокие значения этих параметров указывают на износ диска или риск его отказа. Также учитывают Power_On_Hours для оценки ресурса диска и Temperature_Celsius — повышение температуры выше 50°C ускоряет деградацию.
Можно ли просматривать файлы на RAID массиве без риска повреждения данных?
Да, для безопасного просмотра содержимого массива рекомендуется монтировать его в режиме read-only. В Linux это делается командой mount -o ro /dev/mdX /mnt/raid. Также можно использовать rsync —dry-run или cp -n для проверки структуры каталогов и доступности файлов без внесения изменений. Для аппаратных массивов утилиты storcli и megacli позволяют выполнять анализ логических дисков без записи.
Что делать при обнаружении деградирующего диска в RAID 5 массиве?
Если диск помечен как degraded, необходимо подготовить его к замене и установить новый диск аналогичного объема и типа. В программных массивах Linux используется mdadm —add /dev/mdX /dev/sdY для добавления нового диска, после чего массив автоматически начинает восстановление. Для аппаратных контроллеров применяются команды storcli /c0 /v0 start rebuild. Во время восстановления следует контролировать прогресс через cat /proc/mdstat или утилиты контроллера и убедиться, что массив полностью восстановлен перед дальнейшей эксплуатацией.