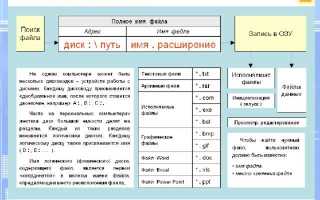
Работа с файлами на уровне байтов позволяет точно выявлять структуру данных, находить повреждения или скрытую информацию. Каждый байт хранит числовое значение от 0 до 255, что делает прямой просмотр критичным для анализа бинарных форматов, таких как изображения, исполняемые файлы и архивы.
Скриптовые языки, например Python, предоставляют возможность читать байты блоками, конвертировать их в числа или строки и фильтровать по критериям. Это полезно при автоматизации поиска шаблонов или анализа больших массивов данных без открытия файлов в GUI-интерфейсе.
Hex-редакторы, такие как HxD или 010 Editor, дают наглядное представление содержимого файла, позволяя сразу редактировать отдельные байты и сравнивать разные версии файлов. Важно выбирать инструмент с поддержкой отображения смещений и интерпретации данных в различных числовых системах.
Просмотр байтов не ограничивается чтением. Практические задачи включают поиск повторяющихся последовательностей, выявление скрытых метаданных, извлечение встроенных ресурсов и проверку контрольных сумм. Выбор метода зависит от объема данных, необходимости автоматизации и формата файлов.
Просмотр байтов в файле: методы и инструменты

xxd позволяет конвертировать файлы в hex и обратно, включая возможность создания бинарных патчей. Команда od удобна для просмотра числовых представлений байтов в восьмеричной, десятичной или шестнадцатеричной форме и позволяет фильтровать диапазоны смещений с помощью —skip и —count.
В Python открытие файла в бинарном режиме rb обеспечивает точное чтение отдельных байтов. Методы read(n) и seek(offset) позволяют выбирать блоки данных для анализа, а struct.unpack – интерпретировать последовательности байтов как числа, строки или составные структуры.
Hex-редакторы, такие как HxD и 010 Editor, дают возможность редактирования отдельных байтов, поиска шаблонов и сравнения версий файлов. В 010 Editor доступны бинарные шаблоны, которые распознают сложные форматы, включая изображения и сетевые пакеты, и отображают их содержимое в удобной структуре.
Выбор инструмента зависит от объема данных и целей анализа. Для оперативного просмотра и быстрого поиска подойдут командные утилиты, для автоматизации анализа больших массивов данных – скрипты, а для детального исследования структуры файлов и редактирования – hex-редакторы с поддержкой шаблонов и сравнения версий.
Использование командной строки для анализа бинарных файлов
Командная строка предоставляет быстрый доступ к просмотру и анализу байтов без установки графических инструментов. Утилита hexdump отображает содержимое файла в шестнадцатеричном формате и поддерживает опции -C для комбинированного вида с ASCII и -n для ограничения количества читаемых байтов.
xxd позволяет преобразовать файл в hex и обратно, с поддержкой параметров -g для группировки байтов и -s для смещения, что упрощает изучение структуры больших файлов. С помощью xxd -r можно применять изменения напрямую к бинарным данным.
Использование командной строки позволяет автоматизировать рутинный анализ, интегрировать проверки в скрипты и выполнять пакетную обработку файлов без открытия их в графических редакторах, что особенно полезно при работе с сотнями или тысячами бинарных объектов.
Чтение и визуализация байтов в Python
Для работы с бинарными файлами в Python используют открытие файлов в режиме rb, что позволяет считывать точные значения байтов. Метод read(n) возвращает последовательность из n байтов, а seek(offset) позволяет перемещать указатель для выборочного анализа сегментов файла.
Модуль struct используется для интерпретации байтов в числовые форматы: struct.unpack(‘<H’, data) конвертирует два байта в 16-битное число, а struct.unpack(‘<I’, data) – в 32-битное. Это удобно для анализа заголовков и встроенных данных.
Для больших файлов применяют чтение блоками: for block in iter(lambda: f.read(1024), b») предотвращает переполнение памяти и ускоряет анализ. Комбинация фильтрации и визуализации позволяет быстро находить подозрительные или аномальные участки данных.
Python также поддерживает запись модифицированных байтов обратно в файл через режим wb, что делает язык удобным для тестирования патчей, исправления заголовков и извлечения встроенных ресурсов из бинарных объектов.
Hex-редакторы: обзор популярных программ

Hex-редакторы позволяют просматривать и редактировать файлы на уровне отдельных байтов, анализировать структуру данных и находить скрытые последовательности. Наиболее востребованные программы:
- HxD – бесплатный редактор для Windows, поддерживает работу с файлами размером до нескольких гигабайт, отображение смещений, поиск по шаблонам и экспорт в различные форматы.
- 010 Editor – платный редактор с поддержкой бинарных шаблонов, которые распознают сложные форматы файлов, включая изображения и сетевые пакеты. Поддерживает сравнение версий и редактирование блоков данных.
- Hex Fiend – оптимизирован для macOS, обеспечивает быстрый просмотр больших файлов, поиск по регулярным выражениям и редактирование без загрузки всего файла в память.
- Bless – редактор для Linux, поддерживает многопоточное отображение, конвертацию числовых форматов и сравнение файлов по байтам.
При выборе инструмента учитывают:
- Объем файлов, с которыми предстоит работать. Для гигабайтных файлов критична оптимизация по памяти.
- Необходимость шаблонов и интерпретации данных. 010 Editor позволяет сразу увидеть структуру сложного формата.
- Функции поиска и сравнения. Возможность фильтровать байты и выделять последовательности ускоряет анализ.
- Поддержку экспортируемых форматов. Возможность сохранять изменения или экспортировать части файла для внешнего анализа.
Отображение байтов в виде таблицы и графиков
Визуализация байтов помогает выявлять закономерности, повторяющиеся последовательности и аномалии. Для табличного отображения используют следующие подходы:
- Использование ASCII-колонки рядом с hex-значениями для идентификации читаемых символов.
- Группировка байтов по 8, 16 или 32 для удобства анализа блоков данных и структуры заголовков.
Графическая визуализация помогает оценить распределение значений и повторяемость последовательностей:
- Гистограммы распределения байтов по значениям (0–255) выявляют преобладающие символы и аномалии.
- Линейные графики изменения значений байтов по смещениям помогают обнаружить повторяющиеся паттерны или структуры файлов.
- Тепловые карты позволяют визуально выделить плотные участки данных или зоны с высокой вариативностью.
Для реализации используют Python с библиотеками matplotlib и pandas для построения таблиц и графиков, а также возможность фильтрации и выделения интересующих сегментов данных. Рекомендовано сначала считывать файлы блоками, чтобы избежать переполнения памяти при работе с большими бинарными объектами.
Сравнение двух файлов на уровне байтов
Сравнение бинарных файлов позволяет выявить изменения в структуре, повреждения или внедрённые данные. Для этого используются утилиты командной строки, скрипты и hex-редакторы.
В командной строке Linux применяют cmp для быстрого нахождения первого различия и diff с опцией —binary для полного анализа. В Python сравнение проводят побайтово, считывая блоки одинакового размера из обоих файлов и сравнивая их значения.
Для наглядного представления различий можно использовать таблицу:
| Смещение (байт) | Файл 1 | Файл 2 | Разница |
|---|---|---|---|
| 0x0000 | 0x4A | 0x4A | – |
| 0x0001 | 0xFF | 0xFE | 1 |
| 0x0002 | 0x10 | 0x10 | – |
| 0x0003 | 0x00 | 0x01 | 1 |
Таблица позволяет сразу увидеть позиции и величину различий. Для больших файлов рекомендуют автоматизированные скрипты с записью смещений и значений различающихся байтов в отдельный отчет, что ускоряет анализ и обеспечивает повторяемость проверки.
Поиск и выделение определённых байтовых последовательностей

Поиск конкретных байтовых последовательностей позволяет выявлять сигнатуры файлов, контрольные структуры и внедрённые данные. Для этого используют командные утилиты, скрипты и возможности hex-редакторов.
В командной строке Linux применяют grep с опцией -a для бинарных файлов или xxd для преобразования в hex с последующим поиском последовательностей через регулярные выражения.
В Python используют побайтовое сравнение с функцией find для поиска подпоследовательностей в блоках данных. Например, block.find(b’\xFF\xD8\xFF’) позволяет обнаружить начало JPEG-файла внутри бинарного объекта.
Hex-редакторы, такие как HxD и 010 Editor, поддерживают поиск по hex-шаблону и выделение всех совпадений. В 010 Editor доступна функция «Find All», которая отображает список всех смещений для выбранной последовательности.
При работе с большими файлами рекомендуется считывать данные блоками и сохранять смещения найденных последовательностей в отдельный файл или таблицу для последующего анализа и сопоставления с другими файлами.
Экспорт и сохранение байтового содержимого для анализа
Экспорт байтового содержимого позволяет переносить данные в аналитические инструменты и сохранять промежуточные результаты анализа. В командной строке Linux используют xxd -p file.bin > file.hex для создания текстового hex-дампа, который легко обрабатывать скриптами или импортировать в таблицы.
Python предоставляет возможность сохранять отдельные блоки или весь файл через режим wb. Например, with open(‘output.bin’, ‘wb’) as f: f.write(block) позволяет экспортировать выбранные последовательности для последующего анализа.
Hex-редакторы поддерживают экспорт выделенного диапазона байтов в отдельный файл, включая опции сохранения в raw-формате, текстовом виде или с применением шаблонов для структурированных данных. В 010 Editor можно экспортировать блоки с сохранением смещений и комментариев для детального исследования.
При экспорте рекомендуется документировать смещения и исходное имя файла, чтобы при повторном анализе или сравнении с другими объектами можно было точно сопоставить байтовые диапазоны и избежать ошибок при интерпретации данных.
Вопрос-ответ:
Какие инструменты лучше использовать для просмотра больших бинарных файлов?
Для работы с файлами размером в гигабайты подходят командные утилиты и оптимизированные hex-редакторы. В Linux hexdump или xxd позволяют считывать данные блоками, не загружая весь файл в память. На Windows HxD способен открывать большие файлы и поддерживает поиск по шаблонам, а Hex Fiend на macOS использует методы потокового чтения для быстрого отображения содержимого.
Как найти конкретную последовательность байтов в файле с помощью Python?
Для поиска используют побайтовое чтение в бинарном режиме. Например, открывают файл через with open(‘file.bin’, ‘rb’) и читают блоками, после чего применяют метод find для поиска подпоследовательностей: block.find(b’\xFF\xD8\xFF’). Этот подход позволяет обнаруживать сигнатуры файлов, такие как заголовки JPEG, и фиксировать смещения для дальнейшего анализа.
Можно ли сравнивать файлы на уровне байтов без установки дополнительных программ?
Да, в большинстве операционных систем есть встроенные средства. В Linux подходят команды cmp для нахождения первого различия и diff —binary для полного анализа. В Windows можно использовать PowerShell с побайтовым чтением файлов и сравнивать их через циклы. Для наглядного отображения различий используют таблицы с указанием смещений, значений и величины отличий.
Какие преимущества hex-редакторов при анализе сложных форматов файлов?
Hex-редакторы позволяют сразу видеть структуру файла, выделять сегменты и сравнивать версии. Например, 010 Editor поддерживает бинарные шаблоны, которые распознают заголовки, встроенные ресурсы и сетевые пакеты. Такие редакторы дают возможность редактировать отдельные байты и экспортировать выделенные области для последующей обработки или анализа в скриптах.
Как визуализировать распределение байтов в файле для поиска аномалий?
Для анализа используют таблицы и графики. В Python можно построить гистограмму значений байтов через matplotlib и получить распределение по диапазону 0–255. Линейные графики отображают изменения байтов по смещениям, а тепловые карты позволяют визуально выявлять плотные участки и повторяющиеся последовательности. Такой подход помогает быстро находить подозрительные сегменты в больших бинарных объектах.