Словарь в Python представляет собой структуру данных, позволяющую хранить пары ключ-значение. Часто возникает необходимость преобразовать список элементов в словарь для ускорения поиска данных и упрощения их обработки. Например, список кортежей, где первый элемент – ключ, а второй – значение, можно быстро превратить в словарь с помощью встроенной функции dict().
При работе с двумя отдельными списками, например, с именами и их оценками, ключи и значения можно объединить через функцию zip(), что позволяет создавать словарь без ручного перебора элементов. Такой подход сокращает количество кода и минимизирует ошибки при обработке данных.
Для более сложных структур, например, когда список содержит вложенные списки или повторяющиеся ключи, можно использовать цикл for для последовательного добавления элементов, фильтрацию данных перед вставкой и проверку существующих ключей. Кроме того, Python позволяет создавать словари через dict comprehension, что упрощает запись и делает код более читаемым.
В этом руководстве представлены пошаговые методы создания словаря из различных типов списков, с конкретными примерами кода и рекомендациями по обработке повторяющихся или вложенных данных, что позволяет адаптировать подход под разные сценарии программирования.
Превращение списка кортежей в словарь с помощью dict()

Список кортежей в Python часто используется для хранения пар значений, где первый элемент выступает ключом, а второй – значением. Для преобразования такого списка в словарь подходит встроенная функция dict(), которая автоматически сопоставляет ключи с соответствующими значениями.
Пример: список data = [(‘яблоко’, 10), (‘банан’, 5), (‘вишня’, 20)] можно превратить в словарь следующим образом: fruits = dict(data). В результате получится {‘яблоко’: 10, ‘банан’: 5, ‘вишня’: 20}, что позволяет обращаться к значениям по ключу напрямую.
При работе с большими списками кортежей использование dict() сокращает время выполнения по сравнению с ручным перебором элементов через цикл for. Если в списке встречаются повторяющиеся ключи, dict() оставляет последнее значение, связанное с ключом, что важно учитывать при обработке данных.
Использование цикла for для формирования словаря из списка
Цикл for позволяет формировать словарь из списка, когда требуется контролировать процесс добавления элементов или выполнять дополнительные проверки. Например, если список содержит кортежи или вложенные списки, цикл обеспечивает гибкость при обработке ключей и значений.
Пример: data = [(‘яблоко’, 10), (‘банан’, 5), (‘вишня’, 20)]. Создание словаря через цикл выглядит так: fruits = {}
for key, value in data:
fruits[key] = value. Такой подход позволяет фильтровать данные, пропуская нежелательные элементы или изменяя значения перед добавлением в словарь.
Цикл полезен при работе с повторяющимися ключами: можно проверять наличие ключа с помощью if key not in fruits или суммировать значения для одинаковых ключей. Это обеспечивает точный контроль над структурой итогового словаря и предотвращает потерю информации.
При больших списках рекомендуется предварительно выделять память для словаря или использовать генерацию ключей и значений в отдельной переменной, чтобы уменьшить нагрузку на память и ускорить выполнение цикла.
Создание словаря из двух списков через zip()
Функция zip() позволяет объединить два списка в пары ключ-значение для последующего создания словаря. Первый список используется как ключи, второй – как значения, что исключает необходимость ручного сопоставления элементов.
Пример: keys = [‘яблоко’, ‘банан’, ‘вишня’] и values = [10, 5, 20]. Создание словаря выполняется так: fruits = dict(zip(keys, values)). Результат: {‘яблоко’: 10, ‘банан’: 5, ‘вишня’: 20}.
Если списки разной длины, zip() автоматически остановится на длине меньшего списка, предотвращая ошибку. Для обработки недостающих значений можно использовать itertools.zip_longest(), указав значение по умолчанию. Этот метод удобен при формировании словарей из динамически изменяющихся списков.
Перед созданием словаря рекомендуется проверить уникальность ключей, так как повторяющиеся элементы первого списка будут перезаписывать значения в словаре. Это важно учитывать при работе с данными из внешних источников.
Преобразование списка списков в словарь ключ-значение
Список списков часто используется для хранения пар данных, где первый элемент внутреннего списка выступает ключом, а второй – значением. Для преобразования такой структуры в словарь удобно использовать цикл for с последовательным присвоением элементов.
Пример: data = [[‘яблоко’, 10], [‘банан’, 5], [‘вишня’, 20]]. Преобразование выполняется так:
fruits = {}
for item in data:
key, value = item
fruits[key] = value
Результат:
| Ключ | Значение |
|---|---|
| яблоко | 10 |
| банан | 5 |
| вишня | 20 |
При обработке больших списков рекомендуется проверять, что каждый внутренний список содержит ровно два элемента. Если длина отличается, можно использовать проверку if len(item) == 2 для предотвращения ошибок при добавлении в словарь.
Добавление и обновление элементов словаря при обходе списка

При обходе списка с помощью цикла for можно динамически добавлять новые элементы в словарь и обновлять существующие значения. Это особенно полезно, когда данные поступают последовательно и требуют агрегирования или корректировки.
Пример: data = [(‘яблоко’, 10), (‘банан’, 5), (‘яблоко’, 3)]. Создание и обновление словаря выполняется так:
fruits = {}
for key, value in data:
if key in fruits:
fruits[key] += value
else:
fruits[key] = value
В результате словарь fruits будет содержать суммарные значения для повторяющихся ключей: {‘яблоко’: 13, ‘банан’: 5}. Такой подход позволяет аккумулировать данные без потери информации.
Для оптимизации работы с большими списками можно использовать метод dict.get(), который возвращает текущее значение ключа или значение по умолчанию. Например: fruits[key] = fruits.get(key, 0) + value. Это сокращает количество проверок и делает код компактнее.
Фильтрация данных списка перед созданием словаря

Перед созданием словаря из списка часто требуется отфильтровать элементы, чтобы исключить нежелательные или некорректные данные. Фильтрация помогает сохранить только те пары ключ-значение, которые соответствуют условиям обработки.
Пример: data = [(‘яблоко’, 10), (‘банан’, -5), (‘вишня’, 20), (‘груша’, None)]. Можно оставить только элементы с положительными значениями и непустыми ключами:
- Использовать цикл for с условием if value > 0 and key is not None.
- Применять list comprehension для создания промежуточного списка допустимых элементов: filtered = [(k, v) for k, v in data if v > 0 and k].
- Создавать словарь на основе отфильтрованного списка: fruits = dict(filtered).
Для сложных условий фильтрации можно комбинировать несколько проверок:
- Проверка типа значения: isinstance(value, int)
- Проверка уникальности ключа перед добавлением
- Фильтрация по диапазону чисел или списку допустимых ключей
Такой подход минимизирует ошибки и гарантирует, что итоговый словарь содержит только корректные данные для дальнейшей обработки.
Обработка повторяющихся ключей при генерации словаря
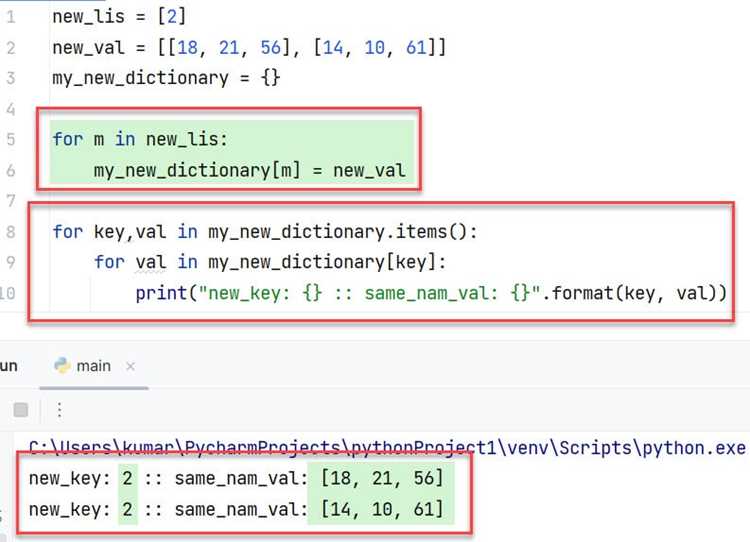
При создании словаря из списка часто встречаются повторяющиеся ключи. В стандартном словаре Python новое значение перезаписывает старое, что может привести к потере данных. Для сохранения информации необходимо заранее определить стратегию обработки повторов.
Пример: data = [(‘яблоко’, 10), (‘банан’, 5), (‘яблоко’, 3)]. Если требуется суммировать значения повторяющихся ключей, используют цикл:
fruits = {}
for key, value in data:
if key in fruits:
fruits[key] += value
else:
fruits[key] = value
Результат: {‘яблоко’: 13, ‘банан’: 5}. Альтернативный подход – сохранять все значения в списке, чтобы видеть историю изменений:
fruits = {}
for key, value in data:
fruits.setdefault(key, []).append(value)
Такой метод позволяет хранить полную информацию и обрабатывать повторяющиеся ключи гибко, например, для статистики или анализа изменений во времени.
Применение словарного включения (dict comprehension) к спискам
Словарное включение (dict comprehension) позволяет создавать словарь из списка в одну строку, сокращая код и улучшая читаемость. Этот метод особенно полезен для преобразования и фильтрации данных одновременно.
Пример: data = [(‘яблоко’, 10), (‘банан’, 5), (‘вишня’, 20)]. Создание словаря через comprehension:
fruits = {key: value for key, value in data}
Результат: {‘яблоко’: 10, ‘банан’: 5, ‘вишня’: 20}
Для фильтрации и обработки значений можно использовать условия и выражения:
- Сохранение только положительных значений:
fruits = {k: v for k, v in data if v > 0} - Преобразование значений, например умножение на коэффициент:
fruits = {k: v*2 for k, v in data} - Обработка повторяющихся ключей через функцию агрегирования:
fruits = {k: sum(v for key, v in data if key == k) for k, _ in data}
Словарное включение облегчает создание и модификацию словарей, позволяя одновременно фильтровать данные и изменять значения без использования дополнительных циклов.
Вопрос-ответ:
Как создать словарь из списка кортежей в Python?
Если список содержит кортежи, где первый элемент — ключ, а второй — значение, его легко преобразовать в словарь с помощью dict(). Например, data = [(‘яблоко’, 10), (‘банан’, 5)]. Создание словаря: fruits = dict(data). Результат: {‘яблоко’: 10, ‘банан’: 5}. Этот способ удобен для небольших списков с уникальными ключами.
Можно ли объединить два списка в словарь в Python?
Да, функция zip() объединяет два списка, превращая их в пары ключ-значение. Например, keys = [‘яблоко’, ‘банан’] и values = [10, 5]. Создание словаря: fruits = dict(zip(keys, values)). Если списки разной длины, zip() остановится на длине меньшего списка. Для заполнения недостающих значений применяют itertools.zip_longest().
Как правильно обрабатывать повторяющиеся ключи при создании словаря?
При повторяющихся ключах стандартный словарь оставляет только последнее значение. Чтобы сохранить суммарное значение для ключа, используют цикл: for key, value in data: fruits[key] = fruits.get(key, 0) + value. Если нужно хранить все значения, используют setdefault(): fruits.setdefault(key, []).append(value). Такой подход помогает сохранить все данные и анализировать повторения.
В каких случаях удобнее использовать словарное включение (dict comprehension)?
Словарное включение позволяет создавать словарь в одной строке, фильтровать элементы и изменять значения одновременно. Например, {k: v*2 for k, v in data if v > 0} создаст словарь с удвоенными значениями, исключая отрицательные. Метод подходит для преобразования списков с применением условий и арифметических операций к значениям.